
특별하지 않지만 개선한 건에 대한 기록
legacy code를 보다보면 가끔 이해할 수 없는 코드들이 있다. 이미 만들어진 시스템을 왜 이렇게 만들었는지에 대하여 전임자를 욕하는 것은 좋지못한 행동이지만 우리 유닛 모두가 한결같이 자주 이야기 했던 데이터가 있다. 그만큼 많이 터지고 많이 속을 썩인 구조중의 하나다. 얼마 전 사용자의 증가로 인하여 아키텍쳐가 변경되어 내용을 정리해 보고자 한다.
Longpolling을 통한 사용자 행위 데이터 추출
현재 내가 운영하는 플랫폼은 longpolling을 이용한 notification system을 구축하고 있다. longpolling을 이용하여 알림 뿐만 아니라 사용자들의 행위에 대한 데이터도 예측치로 얻고있다. 사용자들이 어느 메뉴에서 작업을 하는지에 대한 데이터가 필요한 것이다.
기본적으로 longpolling은 N초가 지나 event가 없거나 N초 이전에 event를 받으면 다시 맺어진다. (여기는 30초로 되어있다.) 사용자가 web page에 머물러 있는 동안에 데이터를 적재하여 잘 동기화 시키면 특정 사용자가 어떤 web page에 머물러 있는지 추정할 수 있다. 또한 이 데이터는 사용자가 longpolling을 다시 맺었는지 맺지않았는지 추정할 수 없기때문에 30초가 지나면 기본적으로 사라져야한다.
DATA
- UniqueValue1 : 사용자의 권한 일련 번호
- UniqueValue2 : 1번과 동일한 사용자의 권한을 가리키는 고유번호
- pageName : page의 고유 ID
- number : 사용자가 바라보는 page의 routing 번호
- userID : 사용자의 Access ID
조건
- 데이터는 longpolling이 맺어지면 들어온다. 열어놓은 Tab(page)갯수만큼 connection이 생기며 page에 대한 데이터도 tab(page)갯수만큼 생긴다. (특정 service 한정) userID가 1개이다 하더라도 여러개의 page를 방문하고 있다면 표기해야한다.
1개의 ID에 대하여 N개 이상의 page - 30초가 지나면 사라져야 한다. longpolling이 끊어질수도있기때문.
TTL : 30sec - 두가지 조회 API
- ①, ②, ③, ④의 데이터로 ⑤을 조회해야한다.
- ①, ②의 데이터로 ⑤을 조회해야한다.
위에 서술한 조건으로 사용자가 어느 메뉴에 있는지에 대한 데이터가 실시간으로 필요하다. 이 데이터는 특정 서비스의 사용자와 사용자가 사용하는 Tab 갯수가 늘어날 때 부하가 생긴다.
Legacy code
위에 기술된 내용을 바탕으로 기존의 system은 사용자가 페이지에 머물러있는 정보를 redis에 저장하고 있었다.
| data type | key | value | TTL |
|---|---|---|---|
| string | uniqueValue1_uniqueValue2_pageName_number_uniqueValue1_userID | timestamp | 30sec |
기존 legacy code에서 redis에 저장된 형식은 위와 같다. key가 6개의 정보를 _(underscore)를 사용하여 구분하고 있었다. 그 중에 ①번 데이터는 중복으로 들어있고, value는 사용할 필요가 없는 똥값이었다. 화가 나기 시작한다. 우리 수석님 주말에 상무님한테 전화와서 털렸다고했다.
redis는 key-value 기반의 in-memory DB이다. key를 정의하는 것에도 권장사항이 존재한다.
Redis key 설계 권장사항
- 조회 측면에서 Key는 간결하면서도 중복되지 않아야 함.
- 긴 문자열은 지양 (피치못할 경우 hash SHA1)
겨우 데이터는 30000개 정도 밖에 안되는데 왜 레디스 cpu가 97%에 육박하며 조회하는데에 0.02초도 안걸리는애가 5초씩이나 걸리면서 애가 정신을 못차리지?했지만 이유가 있었다. key를 insert하는 것은 배제하고 key를 조회하는 쿼리를 하루에 100만개 정도 쏘는데 가장 많이 쏘는 시점에는 초당 50건 정도 조회한다. 그렇다면 조회 쿼리를 확인해야 했다.
arr, err := redis.MultiBulk(conn.Do("SCAN", nextCursor, "MATCH", uniqueValue1+"_"+uniqueValue2+"_"+pageName+"_"+number+":"+uniqueValue1+":"+"*", "COUNT", 1000))코드를 보면 MultiBulk를 사용하여 Redis 특정 index에 있는 key들을 *(astarisk)로 SCAN한다. git 기록을 보니 기존에 KEYS로 되어있었으나 성능이슈로 인하여 SCAN으로 변경된 흔적을 볼 수 있었다. 둘의 차이는 KEYS는 특정 시점의 index를 처음부터 끝까지 key를 탐색하는 것이고, SCAN은 특정 시점에 index의 데이터 전체를 count만큼 쪼개어 탐색하는 것으로 알고있다. 기존 scan count는 1000이었다. 기존에는 30,000개 정도 되는 값을 1000개씩 나누어 읽었다는 것이다.
일단 임시방편으로 redis를 기존에 같이 사용하는 redis와 분리를 했다.
redis를 잘못쓰면 망한다는 것을 몸소 느꼈다. 애초에 요구사항에 대한 Database의 선택이 잘못 되었다. 이것을 알고 난 이상 아키텍쳐 설계를 다시 해야했다.
MongoDB로 변경
MongoDB로 변경하기 전 다양한 의견이 나왔다. 일단 redis의 사용법이 잘못 되었으니 서비스 담당자인 나로써는 redis를 사용하고 싶지 않았다. 하지만 임원을 설득하지 못했다. 기존에 redis를 사용했고, 임원이 다시 그 위 임원을 설득하기 쉽지 않으니 redis를 그대로 고수하라는 지시였다.
| data type | key | value | TTL |
|---|---|---|---|
| List | uniqueValue1:uniqueValue2:pageName_number | userID | none |
메뉴를 진입할때 위와 같은 데이터를 적재한 뒤 browser를 나가게 된다면 value인 userID를 지우라는 것이다. 테스트를 해 보았지만 browser가 끊기는 타이밍이 애매하여 시점 잡는 것이 애매하여 data sync가 맞지 않았다.
위의 테스트를 진행하면서 다른 Database검토까지 같이 진행했다.
- lonpolling을 통하여 1분에
사용자의 접속자 수 * 사용자가 open한 Tab 수 * (60초/30초 -longpolling 맺는 시간)정도의 data를 받을수 있을 것. 대략 서비스사용자가 30000명이라면 대강 평균 open하는 tab갯수가 10개일 경우... 30000 * 10 = 300,000 ?... 최대치는 아님 - key-value가 아닐 것. (검색)
- 속도가 빠를 것.
- expireration을 지원할 것.
위의 사항을 고려하여 선택한 것이 mongoDB였다. 구현이 가능한지 개발기에 적용부터 해보았다. 문제가 생겼다. redis는 expire time을 정해주면 딱 그 시간에 삭제가 되는데 mongoDB는 자체 thread가 1분에 한번씩 돈다. 정확한 삭제시간을 보장받을 수 없기 때문에 그냥 일반적으로 조회를 했을때 과거 데이터가 나올 수 있다는 것이었다.
db.createCollection("myCollection")
db.myCollection.createIndex(
{ "expireAt": 30 },
{ expireAfterSeconds: 0 }
)그래서 index를 만들때 expireAt이라는 field를 기준으로 해당시점과 현재시점이 같을 경우 삭제가 되도록 만들었다. 그리고 longpolling을 맺을때 (insert 시) expireAt field에 30초를 더하고 조회(select) 시 만료시점이 현재시점 이상인 것을 조회하도록 변경했다.
err := c.Insert(UserInfo{
...
...
ExpireAt: time.Now().Add(time.Second * 30),
})
err := c.Find(bson.M{
...
...
"expireAt": bson.M{
"$gte": now,
},
}).All(&res)이로써 legacy code의 migration은 끝났다. 성능 검증을 할 차례이다.
일단 적재 test code부터 작성했다. n분동안 m x 100개의 초당 1개씩 데이터를 insert하는 worker로 적재 하는 것이다. 이때 하루 돌려 놓고 집에 갔다 왔는데 무의미 했던것같다. 데이터를 더 격렬하게 넣고 돌려야 했기 때문... 이때 분당 데이터가 m x 100 x 60 이었는데 이정도 넣고 돌렸을 경우 cpu가 10% 밑돌았다. (cpu 4, mem 8) 데이터 더 넣도록해서 테스트 해봐야지 하던 차에 redis가 터졌다.
무사 반영
기본적인 기능 구현은 다 되어있는 상태에서 개발기에서 운영기로 반영만 시키면 되었다. 회의 끝에 mongoDB를 반영해보는 것으로 결정이 났다. 모두 내일도 똑같은 일이 일어날 것이라 예상하였다. 그날 야근 각이었다. 이사님이 치킨에 골뱅이까지 사준다해서 씹으면서 작업했다. 완벽하게 테스트가 끝나지 않은 상황에서 큰 변화를 반영하려니 불안하긴 했다. 제일 짜증나는게 내가 맡은 서비스 특징이 잘 되고있으면 티가 안나고 안되면 티가 확 난다는 거다. 반영을 완료하고 검수 요청을 했다. 근데 안된다고한다. 듣자하니 내가 제공하는 API의 결과물을 다른 API에 전달해서 뭔가를 받아오는 로직이라고 하는데 다른 API가 응답이 없다고한다. 아니 내꺼는 운영기에서 정상인데 뭐지? 싶었지만 불안했다. 한 1시간정도 대기를 더 했는데 아무리 테스트를 해도 그쪽 API가 안나온다는게 문제인데 하면서 마지막으로 전체 데이터 테스트를 한 뒤에 집으로 복귀했다. 다음 날 아침에 확인 해보니 검증하는 계정이 테스트 계정이라 안나오는 것이라 했다. 아무튼 무사히 잘 반영 되었다.
반영 뒤
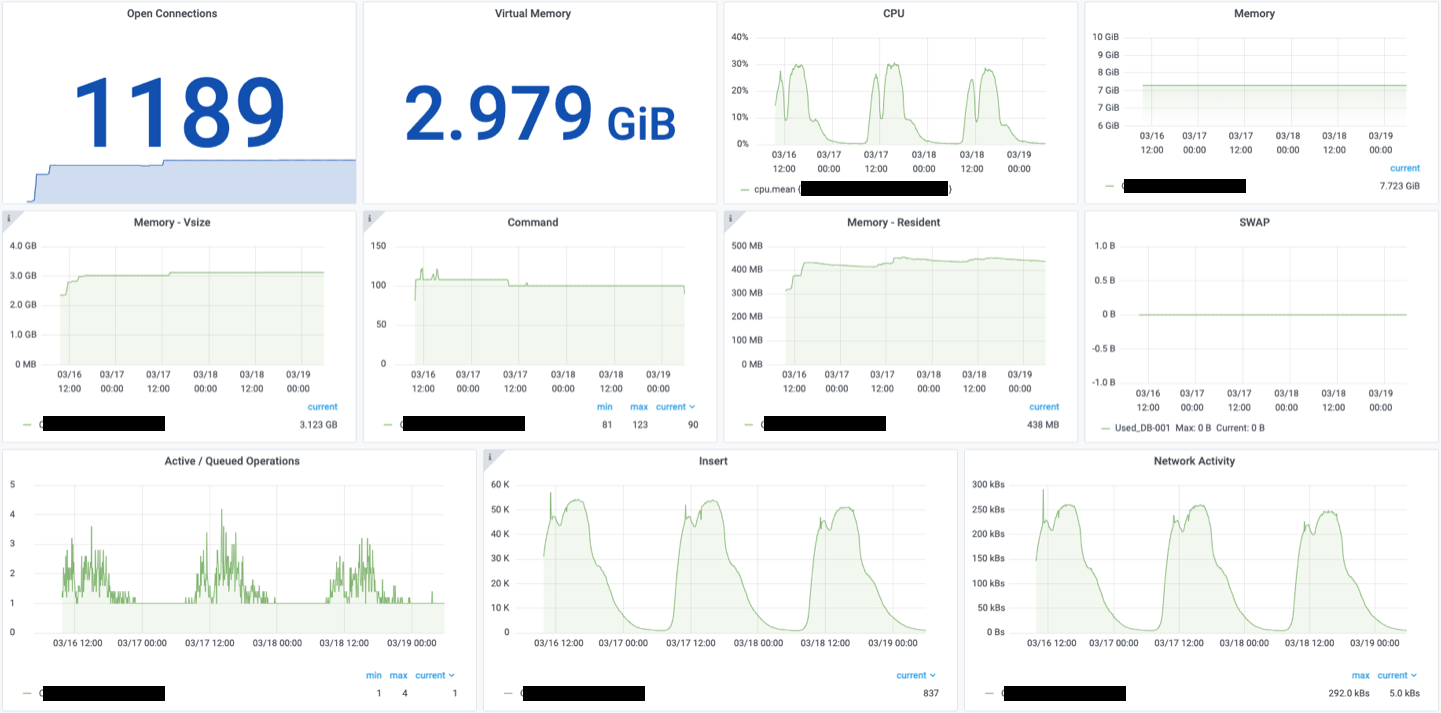
반영하고 나서 같은 조건에도 불구하고 CPU와 Memory가 날뛰며 장애가 일어나는 일은 없다. Grafana를 붙여서 모니터링하고 있다. cpu의 최대치는 30% 남짓, memory도 3GB정도, SWAP도 사용하지 않았다. 전체적으로 사용량과 비례하여 완만한 그래프를 그리고 있다. 사용량의 증가를 예상할 수 있으면 최고의 시나리오 겠지만 안타깝게도 어떤 곳이든 사용량의 증가를 완벽하게 추측하기가 힘들다. (산업 특성상 시기 정도는 예측 가능) 지금까지 서술 한 내용이 아직까지 크리티컬한 이슈가 되지는 않아 다행이다. 하지만 언제라도 이슈가 발생할 수 있으니 지속적인 모니터링과 대비를 할 예정이다.
마무리하며
사실 위에 서술한 사항을 겪은지 1년은 된 이야기이다. 1년전에 한번 겪고 같은 상황을 1년뒤인 지금 한번 더 겪고나서야 운영기에 반영할 수 밖에 없었던 것은 보수적인 판단 때문이라고 생각했다.
우리 팀은 저렇게 두면 언젠가 터질 것을 알면서도 방치했다. 지금 사용자들이 사용하고 있는 상태에서 우리 팀은 임원들을 설득하기 위해 기반이 되는 테스트 데이터를 모으는 것에 급급했던것 같다. 나는 아직 연구원에 불과하기때문에 아주 수직적인 문화를 가진 이 회사에서 누군가를 절대 설득할 수 없을 것이라 생각했다. 아직도 조금 아쉬운 점은 내가 주체적으로 임원을 설득해서 미리 반영했더라면 똑같은 이슈가 발생하지않았을 것이라고 생각한다.
플랫폼을 안정적으로 운영한다는 것은 서비스를 사용하는 사용자들의 신뢰와 관련이 있다. 기업의 책임자들은 안정적이고 오류가 없는 서비스를 제공하는 것을 최우선으로 한다. 다행이도 개발 담당자인 나도 그렇게 생각했기에 3시간만에 개발기에 모든 사항을 준비해 두어 빠르게 운영기에 반영할 수 있었다. 아마 개발기에 준비 해 놓지 못했다면 그 누구도 설득하지 못했을 것이다.
