
본 포스트의 상당 내용은 인과추론의 데이터과학 강의를 참고하였습니다.
현재 학교에서 계절학기로 Causal discovery에 관해 연구를 진행중이다.
4명의 인원이 각각 PC, FCI, NO TEARS, DAG-GNN 알고리즘을 분담하여 해당 알고리즘을 공부하고 Sachs 데이터의 Causal Graph를 도출하여 서로 공유하는 것을 목표로 하고 있다.
그 중, Constraint-based method인 FCI(Fast Causal Inference) 알고리즘을 맡게 되어 학습한 내용 및 결과들을 블로그에 정리해보려 한다.
바로 FCI 알고리즘을 설명하는 것보단, 굉장히 비슷하고 base가 되는 PC 알고리즘을 먼저 설명하고, 그 다음 PC와 FCI의 차이를 비교하는 것이 좋을 듯 하다.
알고리즘의 설명에 앞서, 개인적으로 인과관계와 상관관계의 차이가 굉장히 헷갈려서 그 개념을 명확히 잡고 가고자 했다.
몇 개의 논문과 강의 영상 등을 보고 나서도 애매함이 해소되지 않았을 때, 그 차이를 잘 정리해 놓은 이 블로그 글을 발견했다.


인과관계와 상관관계가 헷갈리는 것은 인과관계 속에 상관관계가 존재하기 때문이다.
둘 모두 A가 이렇게 변하면 B는 이렇게 변한다라고 주장한다.
하지만, 인과관계는 그 속에 올바른 논리가 필요하고, 상관관계는 그렇지 않다는 차이가 있다.
상관관계가 인과관계로 인정받지 못하는 이유
- 누락 변수에 의한 영향
- 누락 변수란 다른 변수에 의한 영향을 고려하지 않는 것을 의미함. 즉, 결과가 다른 원인에 의해 발생했을 가능성이 높은데, 해당 가능성을 배제하는 것
- 시간우선성 존재
- 시간우선성의 존재란 원인이 결과보다 앞서야 한다는 것을 의미. 즉, '역의 인과관계가' 성립하지 않아야 한다. 어떤 것이 시간적으로 우선적인지 알 수 없는 역의 인과관계가 성립하면 이것을 확실하게 인과관계로 규정짓기 어려워진다.
결국엔, 상관관계와 인과관계의 가장 큰 차이는 논리적으로 명확히 증명할 수 있느냐로 보인다.
우연적으로 결과가 발생한 것이 아닌, 앞에 발생한 사건이 명확하게 이 결과에 대한 원인인 것을 논리적으로 설명할 수 있어야 한다.
우리가 살면서 많은 사람들을 경험하다 보면, "사람 보는 눈이 생긴다"라는 말을 들어본 적이 있을 것이다.
살면서 경험한 다양한 상관관계들을 통해 직감이 발달했다고 할 수 있을 거 같은데, 정확히 파고 들어가면 그 상관관계들 속에 명확한 인과관계들이 존재한다고 생각한다.
HR 쪽에서도 이것을 활용해 새로운 팀원을 뽑을 때, 빅데이터를 기반으로 하여 인재채용에 활용한다고 들은 적이 있다.
내가 이해한 Causal discovery란, 어떠한 한 사건이 일어나기 위해 필요했던 다양한 우연들 속에서 서로간의 관계를 발견하는 것이다.
Causal Discovery
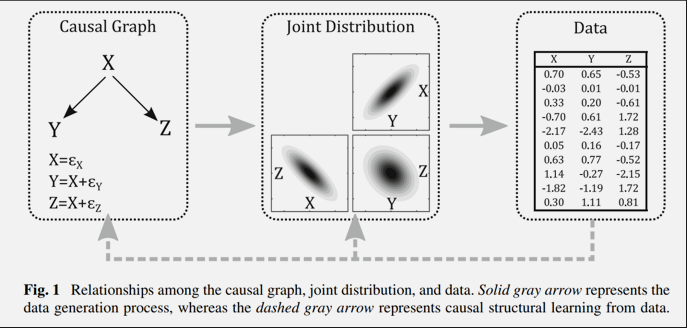
기존의 많은 연구들은 위 그림처럼 잘 정의된 Causal Graph Model을 통해 Joint Distribution(여러 사건이 동시에 일어날 확률)을 구하고, 이 Joint Distribution을 따르는 데이터를 활용하여 인과관계의 효과를 추정했다.
이것이 바로 Structural Causal Model이다.
기존에는 Causal Graph를 연구자가 도메인 지식에 의거하여 설계하였기에, 연구자마다 설계한 다이어그램이 다를 수 있고 실제 Causal Graph와 일치하지 않을 수 있다는 문제점이 존재한다.
만약 완벽한 그래프가 주어진다면, 이론적으로 완벽한 인과 효과를 계산할 수 있지만, 현실세계에서 완벽한 그래프 자체가 구축되기 어려우며, 상당한 도메인 지식 역시 요구될 것이다.
그래서 오직 데이터에 기반하여 객관적으로 Causal Graph를 그리는 방법이 필요해졌고, 이렇게 등장한 것이 Causal Discovery이다.
Causal Discovery는 Structural Causal Model과 반대로, 데이터가 주어지면, 해당 데이터 안의 Joint Distribution을 파악하고, 이걸 바탕으로 Causal Graph를 도출하는 방식이다.
Causal Discovery는 주어진 데이터에서 변수 간 관계를 파악하는 방법이다.
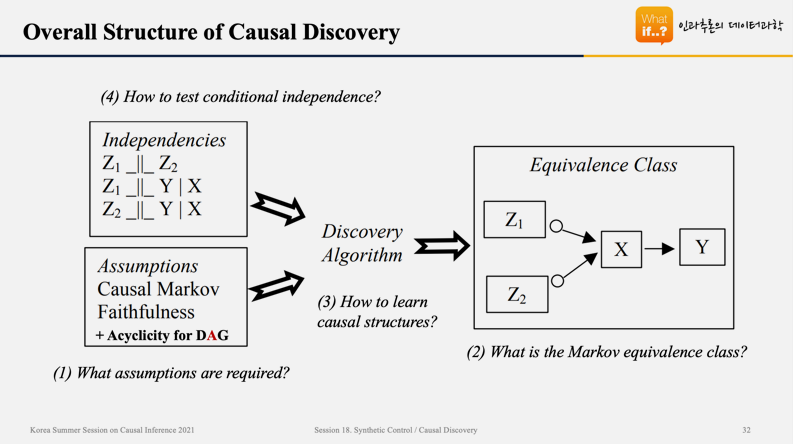
위의 표는 Causal Discovery의 진행과정을 보여준다. 먼저, 데이터 상에 존재하는 변수들 간의 Joint Distribution을 도출하여 각각의 변수들이 서로 독립인지, 종속인지를 파악한다. 그리고, 몇 개의 Assumption들을 모두 만족하는 경우의 관계를 그래프로 표현하면, Equivalence Class라고 부르는 Causal Graph가 도출된다.
Assumptions for Causal Discovery
Causal Discovery는 3가지 가정이 필요하다.
- Acyclicity (for DAG) Assumption -> 그래프가 Cycle을 이뤄선 안 된다.
- Causal Markov Assumption
- Faithfulness Assumption
Causal Markov Assumption
확률 변수 X1, X2, X3의 Joint Distribution은 P(X1, X2, X3) = P(X1)P(X2|X1)P(X3|X1,X2)로 표현할 수 있다.
만약 아래와 같은 그래프가 주어지면 어떨까?
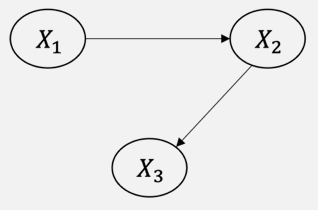
Causal Markov Assumption은 노드는 자신에게 직접적으로 영향을 주는 노드에게만 종속되며, 이외의 모든 노드들과는 독립이라는 가정이다. 이를 수식으로 표현하면, P(X1,X2,X3) = P(X1)P(X2|X1)P(X3|X2)로 표현할 수 있다. 즉, X3는 X2에만 직접적 영향을 받고, X1으로부터는 간접적인 영향을 받기에 X1과 X3는 독립이라고 판단하게 된다.
Faithfulness Assumption

위와 같은 그래프를 가정해보자. A->B->D 경로와 A->C->D 경로가 존재하기에 노드 A와 노드 D는 d-connected 되어 있다고 할 수 있다.
하지만 만약, A->B->D의 경로는 +1의 효과를, A->C->D의 경로는 -1의 효과를 가진다면, 둘의 효과는 상쇄될 것이다.
Faithfulness Assumption은 이러한 효과는 존재하지 않으며, 경로 내에 있는 노드들은 반드시 종속적인 관계여야 한다고 가정한다.
Markov Equivalent Class
PC 알고리즘을 이해하기 위해서는 Markov Equivalente Class를 알아야 한다.
Markov Equivalent Class란, 동일한 skeleton과 V-structure를 가지며, 동일한 Conditional Dependency를 가진 그래프들의 집합으로 정의할 수 있다.
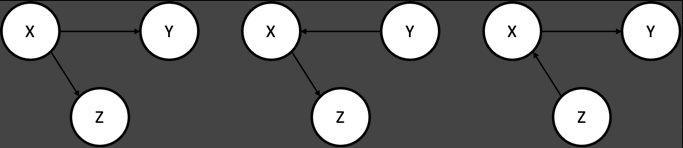
위의 세 그래프는 모두 Equivalent 하다고 할 수 있다.
세 그래프 모두 X와 Z 및 X와 Y가 직접적으로 연결되어 있어 서로 Dependent하고, Y와 Z는 X를 통해 연결되어 있어 서로 Dependent하면, X를 Conditioning 했을 때, Y와 Z가 Conditionally Independent 해지는 구조이기 때문이다.
이런 식으로 X, Y, Z로 표현할 수 있는 DAG 그래프는 아래와 같다.
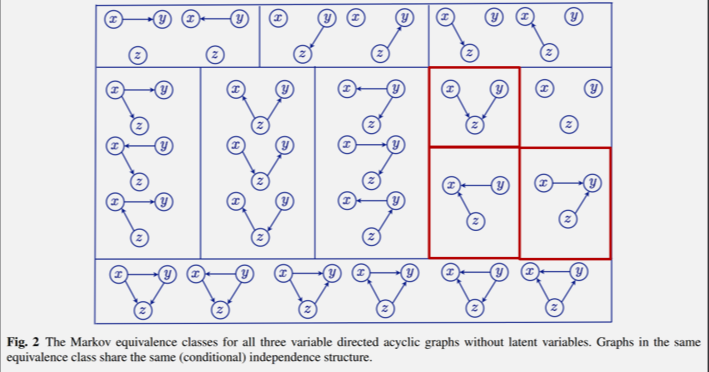
데이터의 Joint Distribution 내에 존재하는 노드들 간의 동일한 관계들로 그려낼 수 있는 Equivalent Graph가 위와 같이 여러 개 존재한다.
문제는, 이와 같이 동일한 관계로 여러 그래프가 도출되면, 이 중에서 어떤 그래프가 옳은 Causal Graph인지 특정할 수 없게 된다.
위 그래프에서 빨간색 부분을 보면, Collider로 V-structure를 이루고 있는 것을 볼 수 있다.
Collider 형식으로 이루어진 노드 간 종속 관계는 Equivalent한 그래프가 한 개만 존재하는 것을 볼 수 있다.
즉, Collider 구조는 노드 간에 종속 또는 독립 관계를 확인할 수 있다면, 단 하나의 Causal Graph로 특정할 수 있는 구조라는 것이다.
이러한 이유로 Collider 구조는 Causal Disovery에서 핵심적인 역할을 수행한다.
PC Algorithm
이제 드디어, 다양한 변수들간의 인과관계를 찾기 위해 Constraint-based method와 Score-based method가 있는데 그 중, Conditional independence를 활용하는 Constraint-based method 종류 중 대표적인 PC 알고리즘에 대해 알아보자.
1.PC 알고리즘을 이용하여 도출하고자 하는 Ground Truth 그래프는 아래와 같다고 하자.
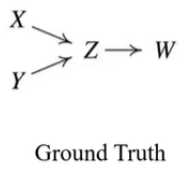
2.첫번째로 Complete Undirected Graph로 시작한다.
모든 변수를 노드로 표시하고 해당 변수들 간에 방향이 없는 Edge를 그려준다.
3.두번째로 서로 전혀 관계없는 Independence 관계인 두 노드 사이의 Edge를 제거한다.
4.세번째로 두 노드 간 다른 노드가 있는 경우, 사이에 있는 노드를 Conditioning 해 보았을 때, 두 노드가 Conditional Independent하다면, 두 노드 사이의 Edge를 제거한다.
이 과정을 반복하면 아래와 같이 Skeleton이 만들어진다.
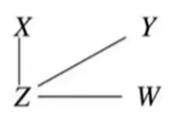
5.네번째로 V-structure를 규명하여 Edge의 방향을 정해준다.
세 변수간 Conditioning Independence check를 하였을 때 V-structure 구조에 부합하는 패턴이 나오는 경우 Edge의 방향을 하나로 규정할 수 있기에 이 과정을 통해 Edge 방향을 정해줄 수 있다.
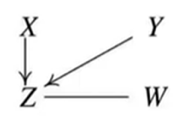
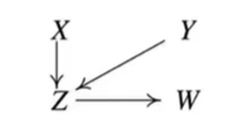
6.마지막으로 Orientation Propagation이라고 불리는 과정이다.
Collider가 만들어 지지 않도록 남아있는 undirected edge의 방향을 정해준다.
PC 알고리즘의 한계
PC 알고리즘은 2가지 한계점을 가지고 있다.
-
Unobserved Confounder를 규명하지 못한다.
PC 알고리즘은 관찰하지 못한 Confounder는 존재하지 않느다는 가정 하에 수행된다.
만약 관찰하지 못한 confounder가 존재할 경우, 실제 Causal Graph와 다르게 나타날 수 있다. -
Edge의 방향을 규명하지 못하는 경우가 존재한다.
참고자료

안녕하세요 좋은 포스팅 감사합니다. 혹시 DAG-GNN에 대한 자료도 있으실까요..? 제가 DAG-GNN에 대해 관심이 있는데 정리한 자료들이 많이 없네요ㅠㅠ