네이버 뉴스 웹크롤링
- 네이버 뉴스 검색 결과 웹크롤링
- 날짜, 발행사이트(press), 제목, 간단한 내용, 상세 내용 url 등을 수집하여 엑셀파일로 정리
- 작업은 python 3.9.0 주피터노트북 파일로 진행했어요
검색조건
- 검색어: 데이터과학, 파이썬
- 검색엔지: 네이버
- 검색기간: 최근 6 개월
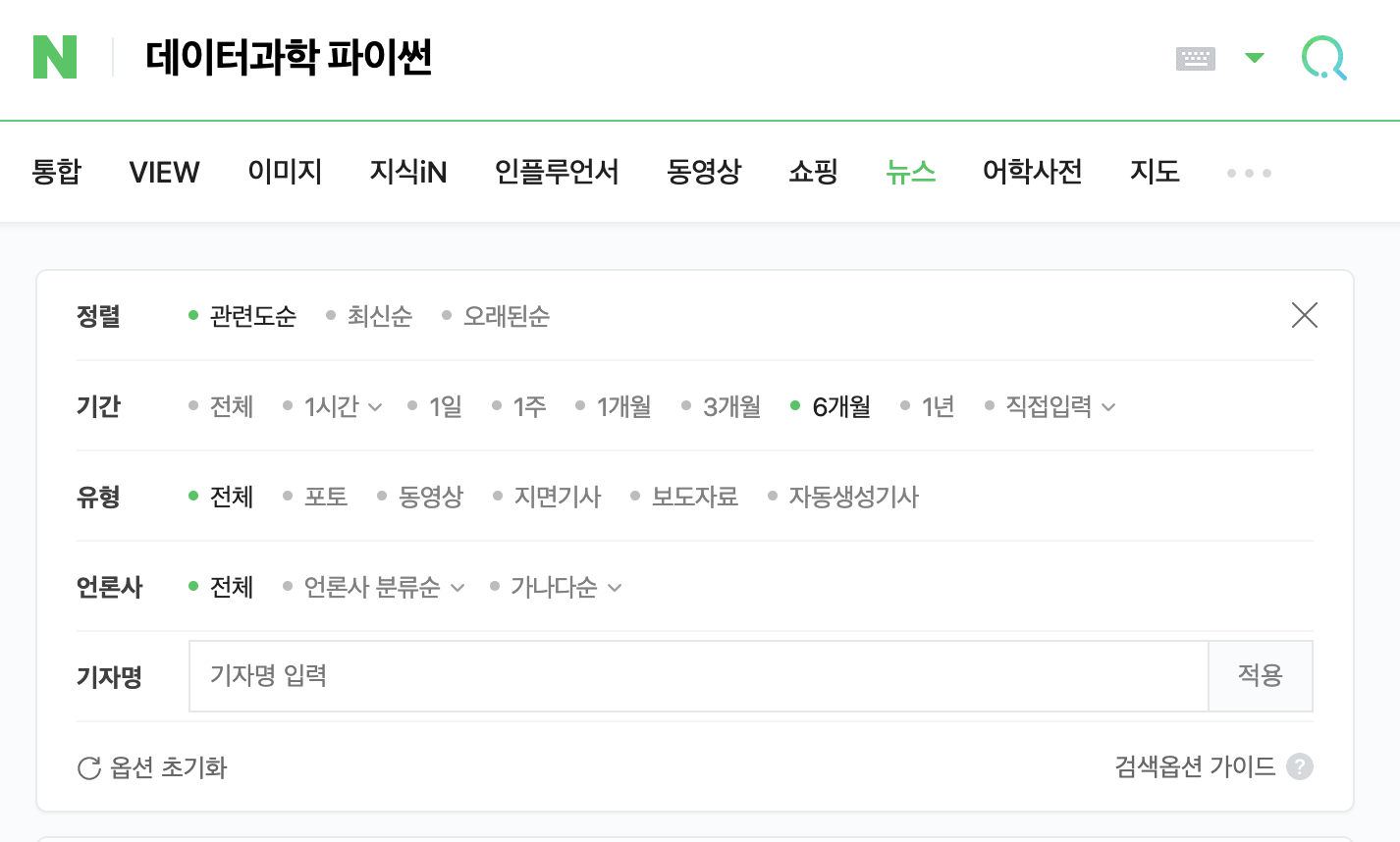
1. 네이버 검색 url 복사하기
1-1 네이버 검색창에 데이터과학 파이썬 입력하기
1-2 입력차 아래에 '뉴스' 클릭
1-3 아래 옵션에서 6개월 선택
1-4 마지막으로 모든 선택이 완료된 후에 주소창(url)을 복사해 둔다
1-5 검색 결과 페이지를 넘겨보면 몇 페이지까지 있는지 확인해 봄(여기서는 21 페이지까지 나옴)
2. 웹크롤링 코딩 시작
- 총 3 개의 코딩 블록으로 구성되어 있음
- 첫 번째는 1-4)에서 복사한 주소를 통하여 검색 결과 페이지를 저장
- 두 번째는 결과 페이지의 내용을 분리해서, 필요한 요소들을 추출
- 세 번째는 추출된 요소들을 데이터 프레임으로 작성
2-1 패키지 로딩
from bs4 import BeautifulSoup
import requests
import openpyxl
from openpyxl import Workbook
import pandas as pd
import numpy as np
from openpyxl.utils.dataframe import dataframe_to_rows2-2 검색 주소(1-4) 입력
searchPath = "https://search.naver.com/search.naver?where=news&sm=tab_pge&query=%EB%8D%B0%EC%9D%B4%ED%84%B0%EA%B3%BC%ED%95%99%20%ED%8C%8C%EC%9D%B4%EC%8D%AC&sort=0&photo=0&field=0&pd=6&ds=2022.08.04&de=2023.01.31&cluster_rank=52&mynews=0&office_type=0&office_section_code=0&news_office_checked=&nso=so:r,p:6m,a:all&start="
- 검색주소와 코드에 입력한 검색 주소의 차이
- 웹브라우저에서 복사한 검색 주소 마지막에는 &start = 0 으로 되어 있음
- 입력 코드의 검색 주소는 마지막 0을 뺀 $start = 까지만 입력함
- 왜냐면, $start = 다음이 오는 숫자에 따라서 패이지가 넘어가기 때문임
- 실습 $start = 뒤에 0, 11, 21, 31 을 차례로 입력하고 주소창에 붙여넣어보면 페이지가 넘어가는 것을 알 수 있음
2-3 페이지 번호 리스트 작성
- 총 21페이지까지 있음
- 따라서 $start = 뒤에 0, 11, 21, ... , 201까지 입력하면 됨
- 한 페이지당 10개의 검색결과가 있다. 그래서 다음 패이지로 넘어가면 11이 됨
pageCount = [i if i == 0 else i * 10 + 1 for i in range(21)]
print(pageCount)[0, 11, 21, 31, 41, 51, 61, 71, 81, 91, 101, 111, 121, 131, 141, 151, 161, 171, 181, 191, 201]
2-4 웹 페이지 크롤링 하기
- 크롤링하면 화면에 보여지는 전체 페이지가 추출됨
- 전체 페이지에서 뉴스 부분만 추출해야 함
- 뉴스 부분이 위치한 테그는 'div.news_area'임
-
웹 페이지 구조 보기
-
검색 결과 창
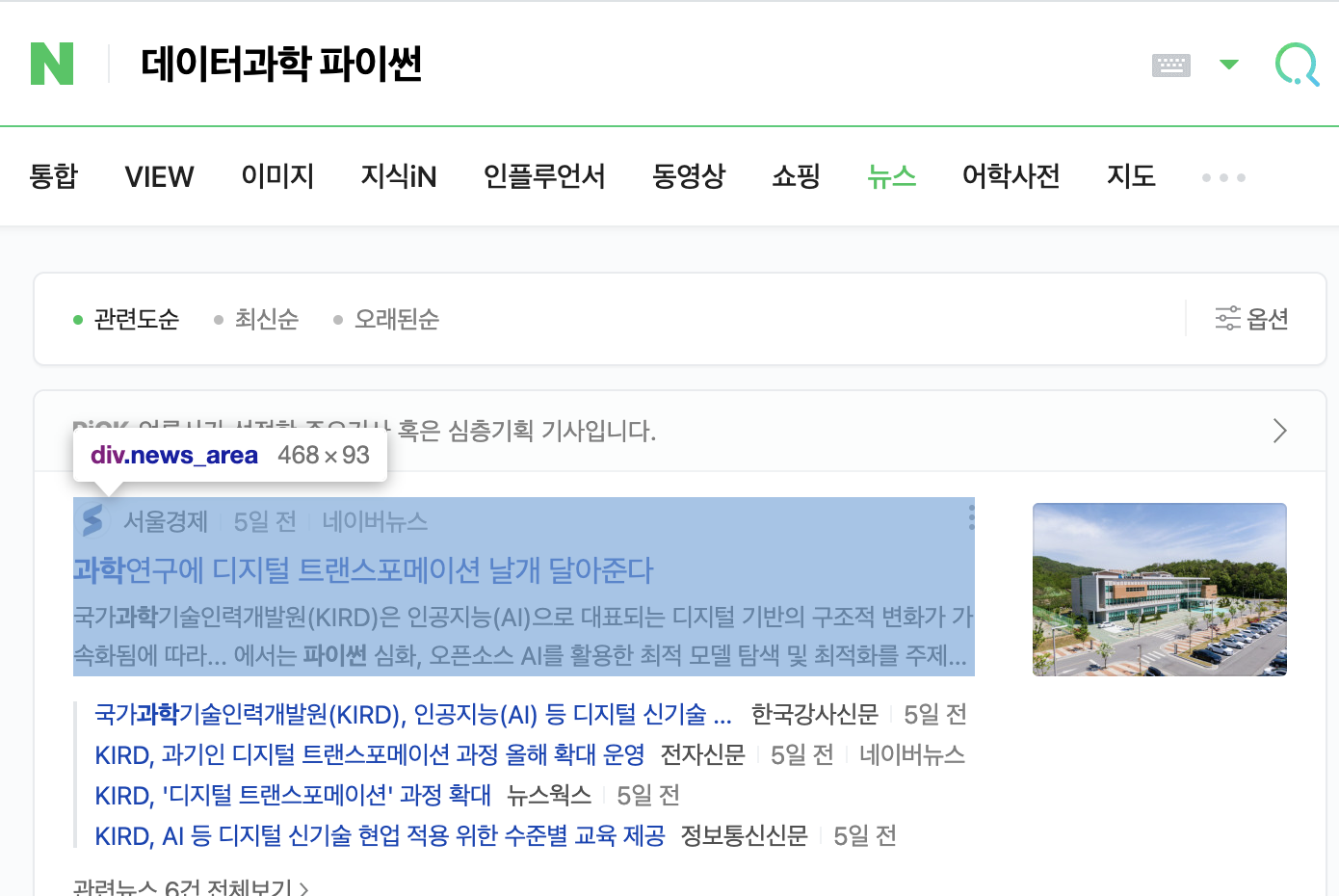
- 웹 페이지 구조에서 div.news_area 보기
- div.news_area 에서 div 는 태그 이름이고 news_area는 class 이름

resp = requests.get(f'{searchPath}{pageCount[0]}')
html = resp.text
soup = BeautifulSoup(html, 'html.parser')
totalNews= soup.select('div.news_area') - 페이지가 잘 읽혔는지 확인해 볼께요
totalNews[0]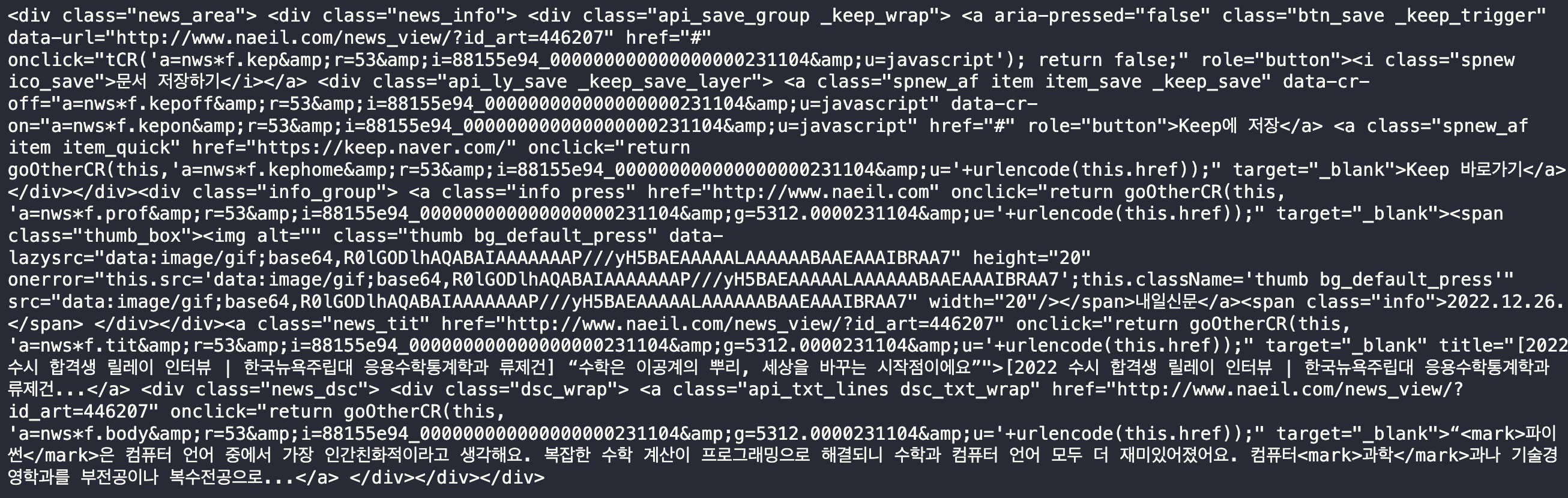
- 같은 방법으로 totalNews[1], totalNews[2], ..., totalNews[9] 까지 입력해 보세요
- 그런데 totalNews[10]에서는 오류가 나옵니다
totalNews[0]
- 왜냐면, 한 페이지에 수록된 검색 결과는 총 10개, 그니싼, 0, 1, 2, 3, 4, 5, 6, 7, 8,9 이렇게 해서 10개가 되지요. 그래서 totalNews[10]은 오류~~
2-5 각 뉴스별 상세 페이지 주소 가져오기
- 상세 페이지는 각 뉴스의 제목에 링크로 되어 있습니다.
- a 테그의 href 로 url을 가져 올께요
m = totalNews[0]
print(m.select_one('a.news_tit'))
url = m.select_one('a.news_tit')['href']
url
- 첫 번째 뉴스 페이지를 객체 m에 담고
- 객체 m의 내용중에서 a 태그에 class 이름이 news_tit 인 내용에서 하이퍼링크(href)를 가져오는 것이죠
2-6 각 뉴스별 제목 가져오기
print(m.select_one('a.news_tit'))
title = m.select_one('a.news_tit').text
title
- 위 2-5에서와 같이 뉴스 제목(news_tit)에서 이번에는 태그로 감싸인 텍스트, 그러니깐 제목을 가져오는 것이에요
2-7 짧은 내용 가져오기
- 뉴스 소개에 관련한 짧은 글을 가져 올께요
print(m.select_one('div.dsc_wrap'))
- div class = 'dsc_warp' 부분이 잘 추출되었습니다.
- 그리고 div class = 'dsc_warp' 바로 다음에 a class = "api_txt_lines dsc_txt_wrap" 이 나옵니다.
- 뉴스의 짧은 소개 글도 링크가 있어요. 글을 클릭하면 상세 페이지로 넘어가죠.
- 여기 a 태그로 감싸인 내용이 짧은 뉴스 내용입니다.
- 이제 짧은 내용을 가져올께요
- 상위 테그 아래 태크를 가져올때는 > 를 사용하고요, class 이름의 공백은 . 으로 표시하죠
- 그러니깐 div.dsc_wrap > a.api_txt_lines.dsc_txt_wrap이 됩니다
message = m.select_one('div.dsc_wrap > a.api_txt_lines.dsc_txt_wrap').text
message
2-8 출처 가져오기
press = m.select_one('a.info.press').text
press2-9 추출한 자료를 데이터 프레임으로 만들기
out = pd.DataFrame(np.array([[date, press, title, message, url]]),
columns=["Date", "Press", "Title", "Message", "URL"])
out3. 코드 정리
- 고생하셨습니다. 이제 모든 코드를 합쳐서 정리할께요
패키지 가져오기
from bs4 import BeautifulSoup
import requests
import openpyxl
from openpyxl import Workbook
import pandas as pd
import numpy as np
from openpyxl.utils.dataframe import dataframe_to_rows검색 주소, 페이지 리스트 만들기
searchPath = "https://search.naver.com/search.naver?where=news&sm=tab_pge&query=%EB%8D%B0%EC%9D%B4%ED%84%B0%EA%B3%BC%ED%95%99%20%ED%8C%8C%EC%9D%B4%EC%8D%AC&sort=0&photo=0&field=0&pd=6&ds=2022.08.04&de=2023.01.31&cluster_rank=52&mynews=0&office_type=0&office_section_code=0&news_office_checked=&nso=so:r,p:6m,a:all&start="
pageCount = [i if i == 0 else i * 10 + 1 for i in range(21)]데이터를 저장할 빈 객체 생성
dat = pd.DataFrame()웹크롤링 및 데이터 저장
for i in range(len(pageCount)):
resp = requests.get(f'{searchPath}{pageCount[i]}')
html = resp.text
soup = BeautifulSoup(html, 'html.parser')
totalNews= soup.select('div.news_area')
for j in range(len(totalNews)):
m = totalNews[j]
url = m.select_one('a.news_tit')['href']
title = m.select_one('a.news_tit').text
message = m.select_one('div.dsc_wrap > a.api_txt_lines.dsc_txt_wrap').text
date = m.select_one('span.info').text
press = m.select_one('a.info.press').text
out = pd.DataFrame(np.array([[date, press, title, message, url]]), columns=["Date", "Press", "Title", "Message", "URL"])
dat = dat.append(out)결과 확인하기
dat.head()결과 저장하기
dat.to_excel("resultOut.xlsx") THE END

data scientist