
1. 문자열
- 문자열(string)은 큰따옴표와 작은따옴표를 모두 사용할 수 있습니다.
- 단 반드시 큰따옴표를 출력해야 하는 문자열은 작은따옴표를 사용해야 하며, 작은따옴표를 출력해야 하는 문자열은 큰따옴표를 사용해야 한다는 것입니다.

예제 4-1

문자열 읽어오기
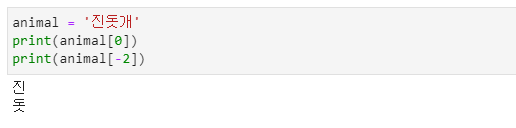
- 문자열형 변수에서 특정한 위치의 값을 읽어올 수 있습니다.
- 변수 animal에 'frog'라는 문자열을 입력하면 animal[0]부터 animal[3]까지 각각 순서대로 저장됩니다.
- 이 각각의 위치를 인덱스(index)라고 하며 n개의 저장장소가 있다면 인덱스는 0부터 n-1까지 존재합니다.
- animal에는 0부터 3까지의 저장 장소가 있습니다.- 마지막 항목으로부터 -1로 시작하여 1씩 감소시키는 인덱싱 방식도 제공합니다.
- 위 기능은 한글에서도 같은 방식으로 동작합니다.




예제 4-2

문자열 슬라이싱(Slicing)
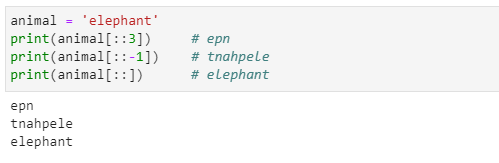
- 문자열에 저장된 항목의 일부를 출력하기 위해 슬라이스의 기능을 사용할 수 있으며 이것은 range 함수의 동작 원리와 비슷하다고 보면 됩니다.
- 배열에서는 콤마( , )가 아닌 콜론( : )으로 입력 인자를 구분합니다.
인자가 1개인 경우
- [] 괄호 안의 인자가 1개일 때는 배열에서와 같이 해당 인덱스 위치에 있는 값을 의미합니다.
인자가 2개인 경우
- [] 괄호 안의 인자가 2개일 때는 [시작 : 끝 + 1]의 의미를 가집니다.
인자가 3개인 경우
- 인자가 3개인 경우는 [시작 : 끝 : 간격]으로 생각하면 됩니다.
인자가 생략된 경우
- 콜론( : )이 1개일 경우
- 콜론( : )이 2개일 경우






예제 4-3







문자열의 병합(Merge)
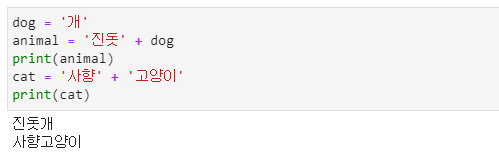
- 두 개의 문자열을 병합하는 방법이 있습니다.
- 두 개의 문자열 사이에 '+' 기호를 넣으면 '+' 기호 앞뒤의 문자열이 병합됩니다.
문자열 함수(메서드)
- 파이썬에서는 내장함수(Built-in Function)들을 제공하고 있으며 언제나 호출하여 사용할 수 있습니다.
- 문자열을 위한 함수로 len( )이 있으며 이것은 괄호 안의 문자열(객체)의 길이를 반환합니다.
정보 수집
- 객체와 객체의 메서드(함수)들은 다음 장에서 자세히 설명할 예정이며 여기에서는 아래와 같은 형태로 1개의 객체 안에 여러 가지 기능을 제공하는 메서드( )를 호출하여 실행합니다.
- animal이라는 변수에 문자열 'elephant'를 입력하면 자동으로 animal이라는 문자열형 객체가 생성되며 이 객체에서 제공해주는 다양한 메서드(함수)를 점( . )으로 연결하여 호출하게 됩니다.
- 첫 번째 명령문에는 animal이라는 문자열형 객체가 생성되며 이 animal 객체 이름에 점을 찍고 메서드(함수)명을 적으면 됩니다.
- 입력값이 있으면 이 메서드의 괄호 안에 입력값을 적어 넣습니다.
- 'e'라는 값을 입력하여 animal에 해당 문자가 몇 개 있는지 세어서(count) 반환하면 print( ) 함수가 그 값을 출력하게 됩니다.
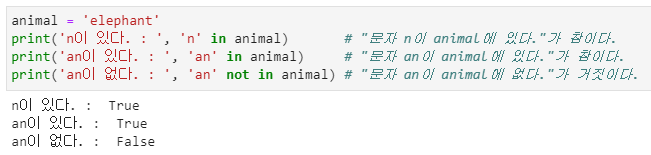
- 특정 문자 또는 문자열이 해당 문자열에 존재하는지 여부를 판단하는 구문 형식은 아래와 같습니다.
- 첫 번째 명령문은 문자 'n'이 해당 문자열에 있는지를 판단하여 출력하는 구문입니다.
- 두 번째 명령문은 문자가 아닌 문자열 'an'이 있는지를 판별하며, 마지막은 찾는 문자열이 해당 문자열에 없는지를 판별하는 명령문입니다.
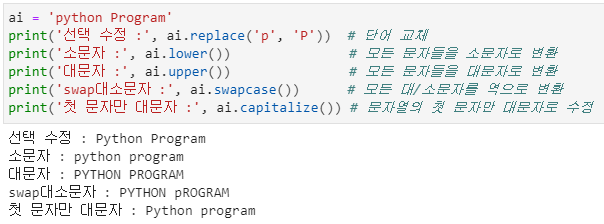
정보 수정
- 위 메서드들이 수정한 내용들은 화면에 출력만 하는 것이지 원래의 ai 변수에 저장된 내용을 수정하는 것은 아닙니다.
- 원래 저장된 내용을 수정하려면 위와 같이 명령문을 실행해야 합니다.
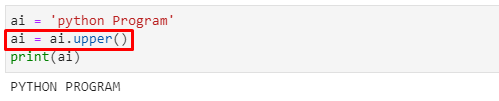
정보 분할






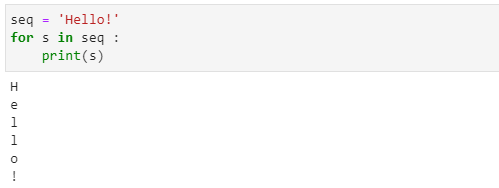
예제 4-4
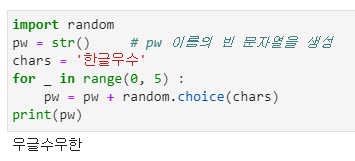
Random 모듈
- random 모듈을 사용하면 무작위에 관련된 다양한 기능들을 사용할 수 있습니다.
- randrange( ) 메서드를 사용하면 특정한 범위의 수 중 무작위의 값을 얻을 수 있습니다.
- 2개의 정수를 입력값으로 받으며 첫 번째 정수에서 두 번째 정수 사이의 무작위 정수값을 반환하게 됩니다.
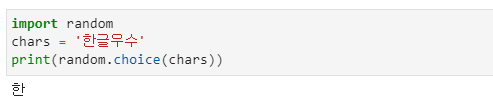
- 저장된 문자열 중에 무작위로 문자를 출력할 수 있는 함수도 있습니다.
- random 모듈에서 제공하는 choice( ) 함수입니다.
- 배열에서도 문자를 무작위로 출력할 수 있습니다.
- shuffle( ) 함수에 입력값으로 섞고자 하는 배열을 입력하면, 초기에 입력한 순서와 다르게 정렬됩니다.
- 배열의 순서를 임시로 배치하는 것이 아니라 실제로 배열의 순서가 바뀌어서 저장됩니다.



예제 4-5
예제 4-6

2. 배열의 종류
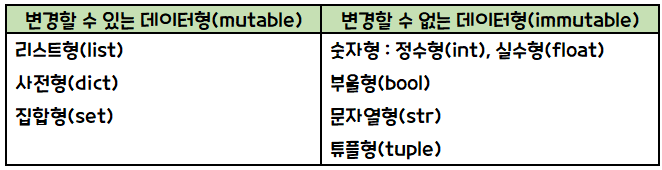
- 파이썬에는 문자열형(strings), 유니코드 문자열형(Unicode strings), 리스트(list), 튜플(tuple), 바이트배열(byte array), xrange와 같은 형태의 배열형(Sequence Type) 자료구조가 있습니다.
- 배열형의 자료구조들은 한 개의 변수로 다수 개의 데이터를 저장해 두고 편리하게 접근(access)하고자 하는 목적을 가지고 있습니다.
- 파이썬에서는 데이터가 변할 수 있는 것과 없는 것으로 구분하고 있으며 튜플형을 제외하고 모두 변할 수 있는(mutable) 데이터 형입니다.
- 위 표를 보면 정수형이 변한 수 없는(immutable) 데이터형란에 적혀 있습니다.
- 결론적으로 정수는 객체이므로 '3'이란 값을 대입했다가 '5'를 대입해도 '3'은 사라지지 않으므로 수정할 수 없는 존재입니다.
리스트(List)
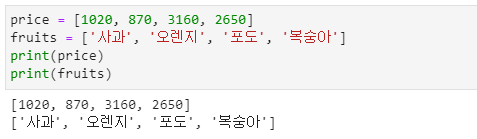
- 리스트는 4가지 배열형중 문자열형과 함께 가장 많이 사용되는 자료구조이며 한 개의 리스트는 한 가지의 자료형만 입력할 수 있는 것이 아니라 다수의 자료형들도 입력이 가능합니다.
- 대괄호([])를 사용하며 각각의 항목들은 콤마( , )로 구분하면 됩니다.
- 값들을 일렬로 저장한 것을 1차원 리스트라고 합니다.
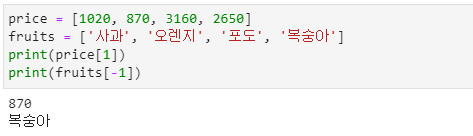
- price[1]은 price 리스트에서 두 번째 항목인 870을 의미하며, fruits[-1]은 끝에서 첫 번째 항복을 의미합니다.
- fruits처럼 중복되게 값을 저장할 수도 있습니다.
- fruitstag는 문자열과 정수값을 반복적으로 갖는 리스트의 예입니다.
- 문자열과 정수를 번갈아 입력한 것처럼 다양한 자료형을 하나의 리스트에 저장할 수 있습니다.
- a는 3개의 값을 갖는 리스트형 변수입니다.
- 변수 a는 수정한 적이 없으므로 값이 변하지 않을 것 같지만 a의 값도 변했습니다.
- b = a라는 명령문은 변수 a가 가리키고 있는 객체를 변수 b도 가리키게 되는 것이므로 b가 가리키고 있는 내용을 수정하게 되면 당연히 a에도 같은 결과를 가져옵니다.



슬라이싱(Slicing)
- 리스트에 저장된 항목의 일부를 출력하기 위해 슬라이스의 기능을 사용할 수 있으며 이것은 앞에서 설명한 문자열과 기본적으로 같습니다.
- 리스트에서는 저장되는 내용이 문자뿐만 아니라 정수, 실수, 문자열 등 다양한 데이터들을 저장할 수 있습니다.
- 문자형에서의 슬라이싱과 같이 range 함수의 기능을 많이 활용하고 있으며 다음과 같은 구조를 가지고 있습니다.

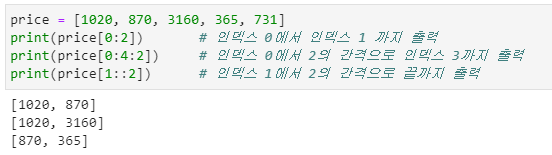
예제 4-7

리스트에서의 병합(Merge) 및 삽입(Insert)
복수 개 변수의 병합
- 복수 개의 변수들을 1개의 리스트로 묶거나(packing) 풀(unpacking) 수 있습니다.
- 2개의 변수들을 1개의 리스트로 묶어서 packing이라는 변수에 저장한 후 다시 각기 다른 변수에 저장하는 코드입니다.
- 여러 개의 데이터들을 하나로 묶어 리스트로 만드는 것은 특별해 보이진 않지만 푸는 기능은 앞서 배운 함수의 반환형이 여러 개일 때와 닮아 보입니다.
복수 개 리스트의 병합
- 복수 개의 리스트를 병합하는 방법이 있습니다.
- 문자열과 비슷하게 '+' 기호를 사용합니다.
- 연결할 리스트 사이에 '+' 기호를 삽입하면 모든 리스트에 포함된 원소들을 한 개의 새로운 리스트의 원소로 병합할 수 있습니다.


예제 4-8

리스트에 원소 삽입
- 기존의 리스트에 1개씩의 새로운 값을 추가할 수 있는 방법으로 3가지가 있습니다.
- 1. append( ) 메서드를 이용하여 리스트의 가장 후면에 추가하는 방법
- 2. insert( ) 메서드를 이용하여 리스트의 원하는 위치에 추가하는 방법
- 3. for문과 if문을 결합한 리스트의 함숙(comprehension) 기법을 이용하여 선택적으로 리스트에 원소들을 삽입하는 방법
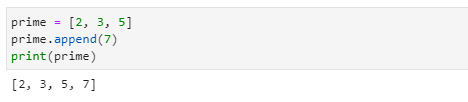
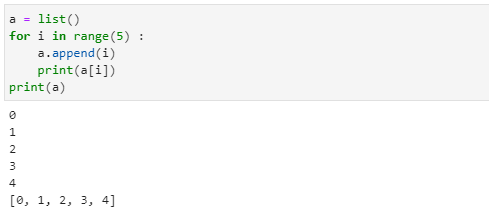
append( ) 메서드
- append( ) 메서드는 1개의 인자를 입력으로 받아들이며 해당값을 리스트의 마지막에 추가로 붙여 넣을 수 있습니다.
- 새로운 리스트를 만들 때에는 빈 리스트를 우선 만들고 append( )를 이용하여 새로운 값을 리스트의 뒷부분에 하나씩 추가하면 됩니다.

예제 4-9

예제 4-10

insert( ) 메서드
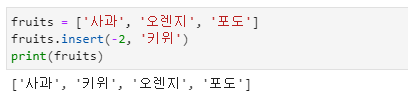
- insert( ) 함수에는 2개의 입력인자가 있는데, 첫 번째는 인덱스 번호이며 해당 인덱스 번호 직전의 위치에 두 번째 인자의 값을 입력하라는 의미입니다.
- 명련문 fruits.insert(1, '키위')는 인덱스 1번 전에 '키위'를 삽입하라는 명령어입니다.
- 따라서 기존의 인덱스 1번에 있는 '오렌지' 이전에 '키위'를 삽입하게 됩니다.

예제 4-11
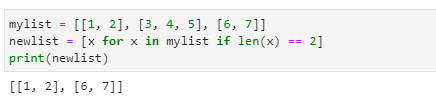
리스트의 함축(Comprehension)
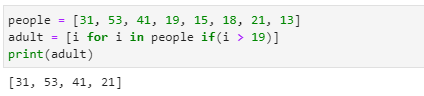
- 파이썬의 일반적인 for문과 if 조건식을 함축적으로 결합한 형식으로 특정 리스트에 저장된 모든 원소들에 대해 조건에 맞는 원소만을 선택적으로 추가할 수 있습니다.
- 이를 리스트의 함축이라 하며 기본 형식은 아래와 같습니다.
- 리스트(①)의 원소들을 i(②)로 읽어 와서 조건식(③)에서 그 값을 테스트 한 후 결과가 참이면 i(④)를 리스트에 입력하게 됩니다.
- 리스트명은 mylist이며 이 mylist의 원소를 각각 i에 저장한 후 이 i를 조건식 (i % 2) == 0에서 테스트합니다.
- 만약 조건식이 참이라면 함축 명령문의 첫 번째 i에 등록되어 리스트에 저장되는 방식입니다.


예제 4-12
리스트의 항목 삭제
- 리스트의 항목을 부분적으로 삭제하기 위한 방법으로 3가지가 있습니다.
- 1. 지정한 항목을 del 명령문으로 삭제하는 방법
- 2. pop( ) 메서드를 사용하는 방법
- 3. 빈 리스트(empty list)를 사용하는 방법del 명령문으로 삭제
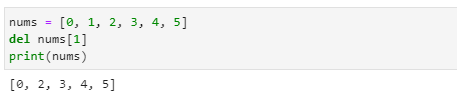
- del 명령문을 이용하면 지정한 위치에 해당하는 항목을 1개 이상 삭제할 수 있습니다.
- nums[1]처럼 인덱스 번호를 입력하면 해당 인덱스의 값이 삭제됩니다.
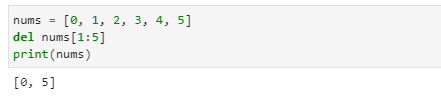
- del 명령어로 여러 개의 항목을 삭제하려면 슬라이스 기능을 사용하면 됩니다.
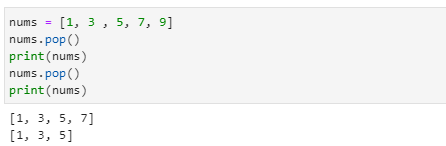
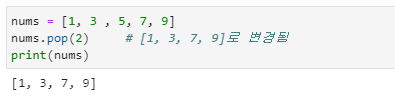
pop( ) 함수로 삭제
- 파이썬은 모든 데이터들이 객체로 구성되어 있습니다.
- 리스트 또한 객체입니다.
- 객체에는 다양한 기능들을 함수(메서드)로 제공하고 있으며 선택적으로 기능들을 사용할 수 있습니다.
- nums라는 객체 이름과 사용하려는 pop( ) 사이에 점만 찍어주면 사용할 수 있습니다.
- 입력 인자를 입력하지 않으면 리스트의 마지막 항목이 삭제되며, 입력 인자를 입력하면 해당 인덱스의 값이 삭제됩니다.
- pop( ) 함수(메서드)에 입력값을 넣어주면 인덱스로 인식하여 해당 위치의 항목을 삭제합니다.
빈 리스트( [] ) 로 삭제
- 리스트 nums의 1번에서부터 2 직전까지의 항목을 빈 리스트( [] )로 대체한다는 의미이며 인덱스 1번의 값만 삭제된 것을 볼 수 있습니다.

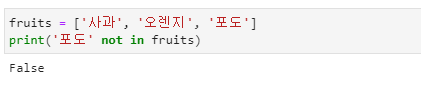
존재 여부(Checking Membership)
- 항목이 리스트에 있는지 in 또는 not in을 사용하여 검사할 수 있습니다.
- word 안에 'r'이 존재하기 때문에 True를 출력합니다.

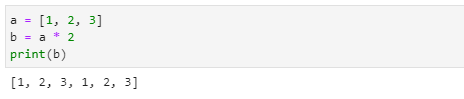
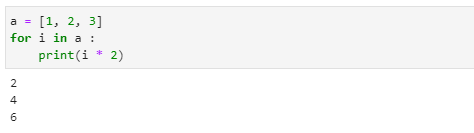
원소의 반복
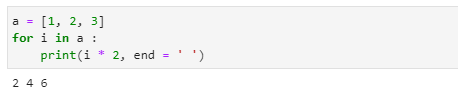
- 배열에 수를 곱해버리면 그 횟수만큼 출력합니다.
- 각 원소에 일일이 2씩을 곱하는 방법을 사용해야 합니다.
예제 4-13
원소의 개수 측정
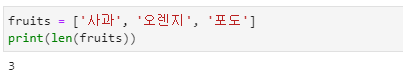
- 리스트에 저장된 원소의 개수를 조사하여 출력할 수 있습니다.
- len( ) 함수의 입력값으로 리스트를 입력하면 해당 리스트에 저장된 개수를 출력합니다.
검색(Search) 기능
빈도수 검사
- 해당 리스트 내에 존재하는 특정 값의 개수를 측정할 수 있습니다.
- 리스트 객체에서 제공하는 count( ) 메서드를 사용하면 가능합니다.
- 입력 인자가 해당 리스트에 몇 개 있는지를 카운트하여 알려줍니다.

예제 4-14

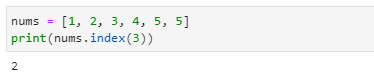
인덱스 번호로 찾기
- 아래의 형식으로 index( ) 메서드를 실행하면 해당하는 인덱스 번호를 얻을 수 있습니다.

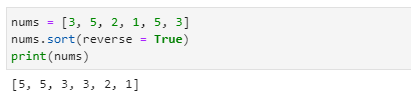
정렬(Sorting)
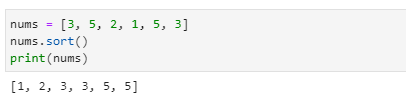
- 리스트에 저장된 항목들은 중복되어 있을 수도 있고 순서 없이 입력되어 있을 수도 있습니다.
- 이 항목들을 크기 순서대로 정렬하여 다시 리스트에 저장할 수 있습니다.
- 오름차순으로 정렬하려면 sort( ) 메서드를 입력값 없이 사용하고, 내림차순으로 정렬하려면 reverse = True 옵션을 사용하면 됩니다.
- sort는 임시로 정렬한 내용을 출력하는 것이 아니라 실제로 리스트의 내용을 정렬하여 저장하게 됩니다.
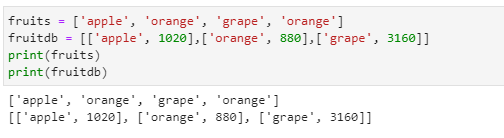
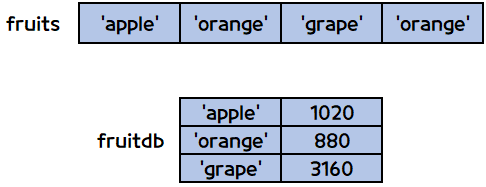
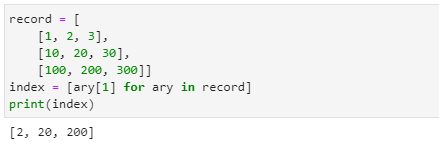
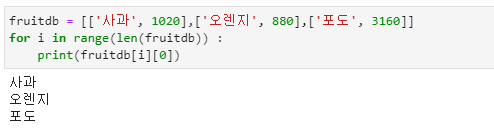
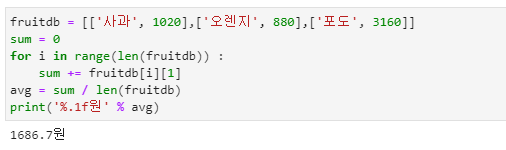
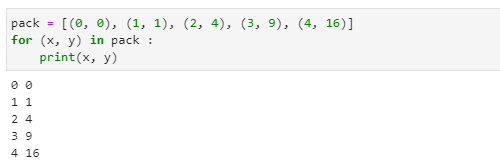
2차원 리스트
- 2차원 리스트는 리스트가 여러 개의 작은 리스트를 가지는 개념입니다.
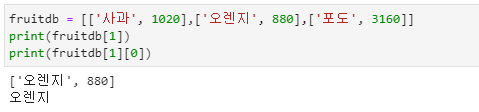
- fruitdb[1]은 fruitdb[1]에 저장된 모든 내용을 출력합니다.
- fruitdb[1][0]은 fruitdb[1]에 저장된 내용 중 0번의 인덱스 내용만 출력합니다.
- 위 코드는 2차원 리스트 record에 저장된 모든 리스트들의 1번 인덱스에 저장된 내용들만 모아 새로운 index 리스트를 생성하는 명려문입니다.
- 리스트의 함축(comprehension) 기능은 1차원뿐만 아니라 2차원 리스트에도 같은 방식으로 적용할 수 있습니다.
예제 4-15

예제 4-16
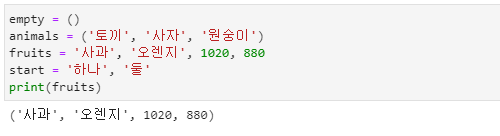
튜플
- 튜플(tuples)은 초기화한 후 변경할 수 없는(immutable) 배열이며 리스트의 대괄호( [ ] )가 아닌 소괄호( ( ) ) 형태로 묶인 형식으로 항목들은 콤마( , )로 연결합니다.
- 튜플 형식으로 데이터를 입력할 때는 괄호를 생략해도 됩니다.
- 튜플은 문자열, 숫자, 튜플, 리스트를 포함할 수 있으며 형식은 리스트와 다르지만 인덱싱, 슬라이싱, 지원하는 다양한 메서드들의 기능들이 리스트와 유사합니다.
- 위 예제는 튜플의 원소로 문자열과 숫자를 가질 수 있다는 것과 색인방법 그리고 편집할 수 없다는(immutable) 것을 보여줍니다.
- start에 저장된 튜플 형식처럼 마지막 입력을 콤마( , )로 마치면 이것 역시 튜플 형식이 됩니다.
- 튜플에서는 리스트와 마찬가지로 인덱싱과 슬라이싱 기능을 제공합니다.
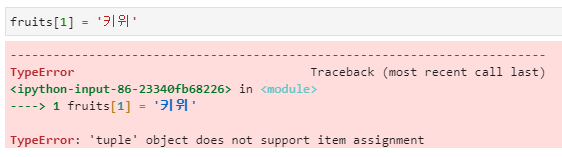
- 튜플은 변경할 수 없는(immutable) 배열입니다.
- 한 번 입력한 내용을 변경할 수 없도록 설계되어 있습니다.
- 튜플은 중첩(nested)될 수 있습니다.
- 튜플은 튜플을 원소로 가질 수 있으며 리스트와 마찬가지로 2차원적인 구성을 만들 수 있다는 의미입니다.
- 편집할 수 없는(immutable) 튜플은 편집할 수 있는(mutable) 리스트를 포함할 수 있습니다.
- 튜플에서는 인덱싱은 가능하지만 인덱스 번호로 새로운 값을 입력할 수 없도록 설계되어 있습니다.
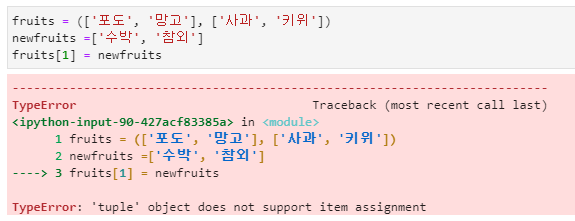
- 다수의 튜플을 원소로 가지고 있는 리스트에서 튜플의 교체는 가능합니다.
- 튜플 안의 내용을 수정을 한 것이 아니라 리스트의 원소를 수정했기 때문에 가능한 것입니다.
- 튜플의 원소가 리스트이며 리스트는 편집이 가능한 데이터형이기 때문에 튜플 내부의 원소로 존재하는 리스트는 수정이 가능합니다.





리스트와 비교한 튜플의 기능들
- 튜플은 기본적으로 리스트에서 사용할 수 있는 대부분의 기능들을 사용할 수 있으나 편집할 수 없는(immutable) 특성을 가지고 있기 때문에 편집에 관련된 기능들은 지원하지 않습니다.
슬라이싱
- 리스트에서와 같이 튜플에서도 저장된 항목의 일부를 출력하기 위한 슬라이싱 기능이 가능합니다.
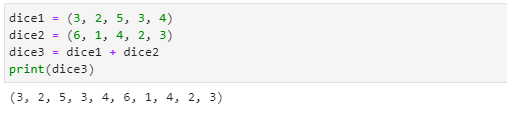
병합(Merge)
- 튜플은 리스트에서처럼 복수 개의 변수들을 1개의 튜플 형태로 묶거나(packing) 풀(unpacking) 수 있습니다.
- 튜플에서는 리스트처럼 append( )나 insert( )로 데이터를 삽입하거나 del 명령어와 pop( ) 메서드를 사용하여 항목을 삭제하는 기능들이 없습니다.
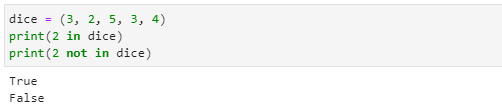
존재 여부(Chekcing Membership)
- 리스트에서와 같이 찾고자 하는 항목이 튜플에 존재하는지 in 또는 not in을 사용하여 검사할 수 있습니다.
반복
- 리스트와 마찬가지로 튜플에 저장된 값들에 특정값을 곱하면 반복적으로 저장됩니다.
원소의 개수 측정
- len을 사용하면 대상의 항목 개수를 출력합니다.
검색(Search) 기능
- 빈도수 검사
- 리스트와 마찬가지로 해당 튜플 내에 존재하는 특정 값의 개수를 측정할 수 있습니다.

- 인덱스 번호 찾기
- 리스트처럼 index( ) 메서드를 실행하여 찾고자 하는 값이 위치한 인덱스 번호를 얻을 수 있습니다.




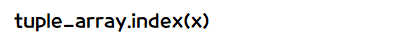
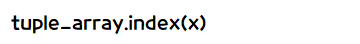

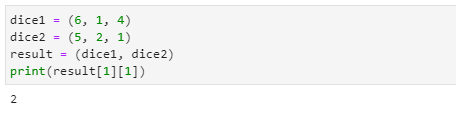
2차원 튜플
- 리스트에서와 마찬가지로 튜플도 2차원으로 원소를 구성할 수 있습니다.
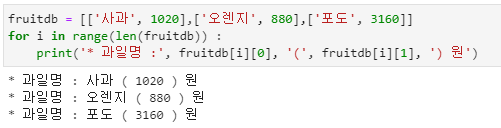
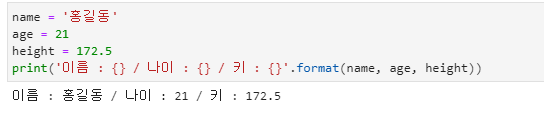
튜플 포매팅
- print( ) 함수에서 튜플 포매팅 방식으로 결과를 출력할 수 있습니다.
예제 4-17
사전
- 사전(dictionary)은 키(key)와 값(value)이 하나의 쌍(pair)으로 이루어진 형식으로 되어있습니다.
- 사전은 리스트나 튜플에서처럼 숫자로 색인(indexing)을 하는 것과 달리 키로 색인을 합니다.
- 키는 문자열이나 숫자 또는 튜플을 사용할 수 있습니다.
- 하나의 사전에 유일한 키들을 포함하고 있어야합니다.
- 키가 직 • 간접적으로 수정이 가능한 객체를 포함하고 있다면 키로 사용할 수 없습니다.
- 슬라이싱이나 apeend( ), extend( )와 같은 메서드를 사용할 수 있는 리스트는 사전에서 키로 사용할 수 없습니다.
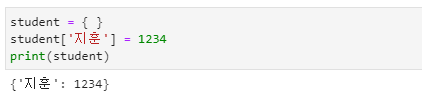
사전의 생성 및 삽입
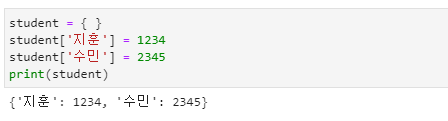
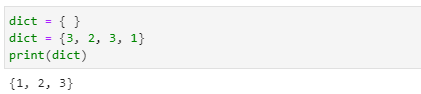
- 한 쌍의 중괄호 { }는 빈 사전을 생성합니다.
- 사전에서는 정렬되지 않은 키:값{key:value} 형태의 쌍으로 구성된 집합 형식으로 입력해야 합니다.
- 2개 이상의 항목이 있으면 콤마( , )로 연결됨을 알 수 있습니다.
- 여러 개의 정보를 하나의 명령문으로 입력할 수도 있습니다.
- 인덱싱이나 슬라이싱 모두 동작하지 않고 에러를 발생시킵니다.
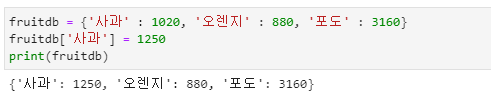
사전 항목 삭제
- 사전의 항목은 del 명령으로 삭제할 수 있습니다.
- 키의 값은 문자열이기 때문에 키(key)의 앞뒤로 따옴표가 필요합니다.
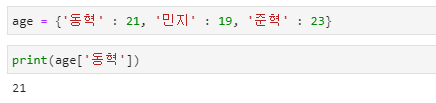
사전 항목 검색
- 아래는 사전의 내용을 조회하기 위해 준비된 다양한 사전의 메서드들입니다.
- print( )는 (키 in 사전) 형식으로 원하는 키값이 사전에 있는지 검색한 후 있으면 True 없으면 False를 반환합니다.
- get( ) 함수는 검색하고자 하는 키(key)가 있으면 해당 키의 값을 반환하며 없으면 None을 출력합니다.
- key( )는 student 사전에 저장되어 있는 모든 키들을 반환합니다.
- values( )는 student 사전에 저장되어 있는 모든 값들을 반환합니다.
- items( )는 student 사전에 저장되어 있는 모든 키:값 쌍들을 반환합니다.
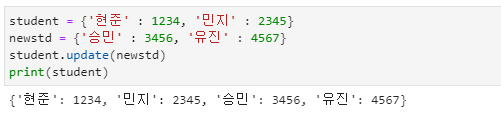
사전 병합
- update( ) 메서드를 이용하여 한 개의 사전에 또 다른 하나의 사전을 병합할 수 있습니다.
다른 배열로 사전 만들기
- dict( )라는 함수(생성자)를 이용하여 키:값 쌍으로 된 배열을 사전 형식으로 만들 수 있습니다.
- 리스트나 튜플과 같이 다른 형태의 배열도 사전으로 작성할 수 있습니다.
- 문자열이지만 따옴표가 없는 키와 대응하는 연결시키는 등호(' = ')를 사용해도 사전 형식으로 전환할 수 있습니다.






예제 4-18

에제 4-19
사전 포매팅
- 사전에서도 print 함수를 사용할 때 포매팅 기능이 있습니다.

예제 4-20

집합(Set)
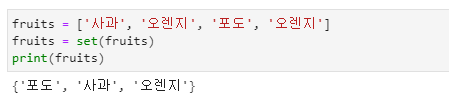
- 집합은 중복되지 않고 정렬되지 않은 원소들로 구성되어 있습니다.
- 집합은 사전과 같이 { } 기호를 사용하고 원소들을 콤마( , )로 구분한다는 공통점이 있지만 사전과 달리 키만 있고 값이 없는 형식입니다.
- 집합을 생성하기 위해서는 { } 기호를 사용하는 방법도 있지만 set( ) 함수를 사용하여 리스트나 튜플을 집합 형태로 생성할 수 있습니다.
추가 및 삭제
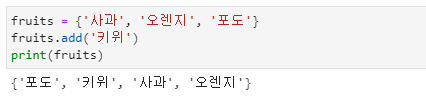
- add( )와 update( ) 메서드를 이용하면 새로운 원소를 집합에 입력할 수 있습니다.
- add( )를 사용하면 3개의 과일에서 키위를 추가하면 순서에 상관없이 키위가 추가되는 것을 볼 수 있습니다.
- update( ) 메서드를 사용하면 새로운 집합을 기존의 집합에 추가할 수 있습니다.
- 집합의 원소를 삭제하는 방법으로는 remove( ), pop( ), clear( )가 있습니다.
- remove( ) 메서드를 사용하면 내가 원하는 원소를 삭제할 수 있습니다.
- pop( ) 메서드를 사용하면 맨 앞에 있는 원소를 삭제할 수 있습니다.
- clear( ) 메서드를 사용하면 모든 데이터가 원소가 삭제되는 것을 볼 수 있습니다.
존재 여부(Cheking Membership)
- 해당하는 값이 멤버인지 아닌지 확인하려면 'in'이나 'not in'을 사용할 수 있습니다.
집합의 연산





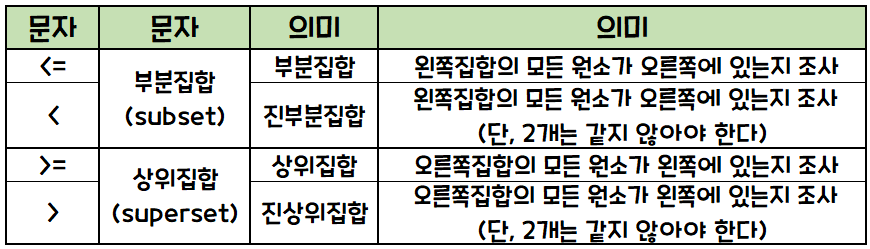
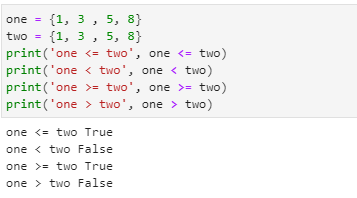
예제 5-21
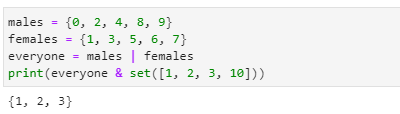
예제 5-22
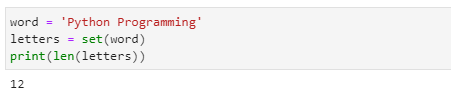
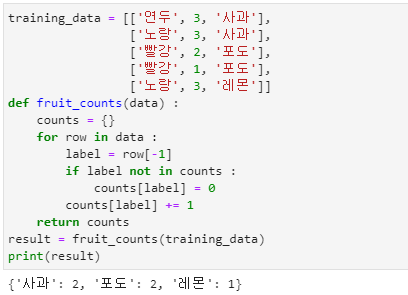
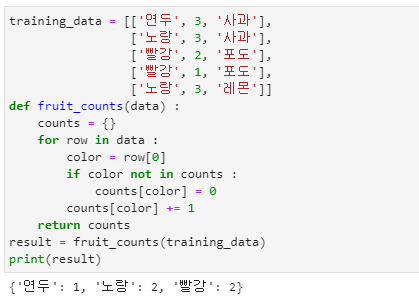
인공지능을 위한 빅데이터 분석의 예제
- 인공지능에서는 입력 데이터로 학습을 시켜야 합니다.

Nil Desperandum <절대 절망하지 마라>