RuntimeError: CUDA error: no kernel image is available for execution on the device 해결
코드 내 amp.initialize를 실행하는 라인에서 runtime error가 발생했다.
해당 에러는 설치되어 있는 torch와 cuda의 버전이 맞지 않아 발생하는 에러이다.
torch & nvidia driver, cuda version 확인
현재 사용하려는 가상환경에서 torch가 어떤 버전의 cuda에서 빌드되는지, 내가 사용하는 서버의 cuda driver의 버전이 무엇인지 확인한다.
(env name) username@currentpath $ python -m torch.utils.collect_env그럼 아래와 같이 정보가 나온다.
PyTorch version: 1.6.0+cu101
Is debug build: No
CUDA used to build PyTorch: 10.1
OS: Ubuntu 18.04.6 LTS
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
CMake version: Could not collect
Python version: 3.8
Is CUDA available: Yes
CUDA runtime version: Could not collect
GPU models and configuration:
GPU 0: A100-SXM4-40GB
GPU 1: A100-SXM4-40GB
GPU 2: A100-SXM4-40GB
GPU 3: A100-SXM4-40GB
Nvidia driver version: 450.236.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.8.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.8.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.8.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.8.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.8.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.8.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.8.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn.so.8.0.2
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.0.2
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.0.2
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.0.2
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.0.2
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.0.2
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.0.2
....
Versions of relevant libraries:
[pip3] numpy==1.24.3
[pip3] torch==1.6.0+cu101
[pip3] torchvision==0.7.0+cu101
[conda] mxnet-cu101mkl 1.6.0.post0 pypi_0 pypi
[conda] numpy 1.24.3 pypi_0 pypi
[conda] torch 1.6.0+cu101 pypi_0 pypi
[conda] torchvision 0.7.0+cu101 보면 PyTorch version이 1.6.0+cu101라고 되어 있다. 1.6.0버전의 pytorch를 해당 가상환경에서 사용하고 있으며 이는 cuda버전 10.1위에서 빌드되는 버전이라는 의미이다.
CUDA used to build PyTorch: 10.1 라고 나와 있는 것은 pytorch를 빌드할 때 10.1버전의 cuda가 사용되었다는 의미이다.
하지만 Nvidia driver version를 보면 450.236.01라고 되어 있으며, cdDNN version이 따르는 cuda를 보면 경로에 cuda-11.0라는 폴더 이름이 보인다.
[Table 2. CUDA Toolkit and Minimum Required Driver Version for CUDA Minor Version Compatibility]
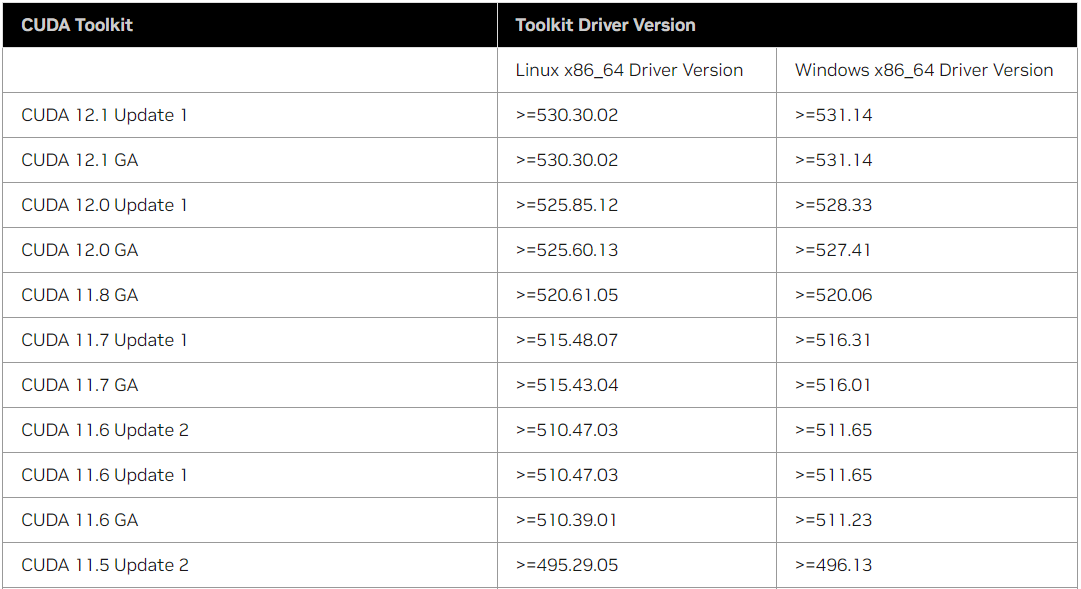
이 링크로 들어가면 위와 같은 표를 통해 자신의 nvidia driver 버전에 맞는 cuda가 무엇인지 확인할 수 있다.
확인해보면 내 driver version은 450.236.01이므로 cuda 버전 11.0.1에 맞게 하면 될 것이다. nvdia-smi 명령어로 터미널에서 확인해보면 설치된 driver version과 그에 맞게 설치된 cuda버전이 뜨는데 이때도 cuda 버전이 11.0으로 나온다.
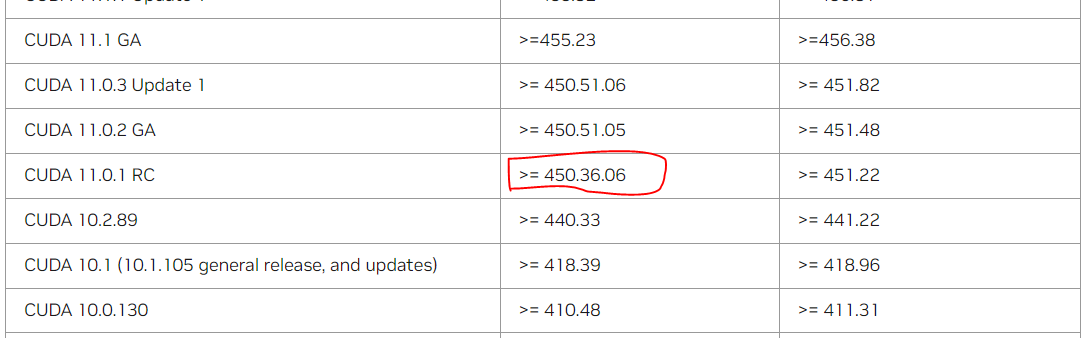
따라서 pytorch와 다른 여러 라이브러리의 버전들을 cuda 11.0과 호환되는 것으로 바꾸어야 한다.
cuda 버전에 맞는 torch 라이브러리 설치 및 환경 설정
python -m torch.utils.collect_env 명령어를 통해 확인한 바로는 torch 뿐만이 아니라,
torchvision도 버전명에 +cu101이 붙은 걸로 보아, cuda버전 10.1위에서 돌아가는 버전인 것이다. 따라서 cuda 11.0버전에 호환되는 가상환경을 만들기 위해 이 사이트로 들어가서 torch와 cuda버전에 맞는 명령어를 찾는다.
파이토치 1.6.0를 사용중이었는데, 해당 버전은 cuda 11.0버전에서 빌드될 수 없다. 맞는 명령어가 없는 것을 확인할 수 있다. 따라서 cuda 11.0버전 위에서 돌아갈 수 있도록 파이토치 버전을 올려야 한다.
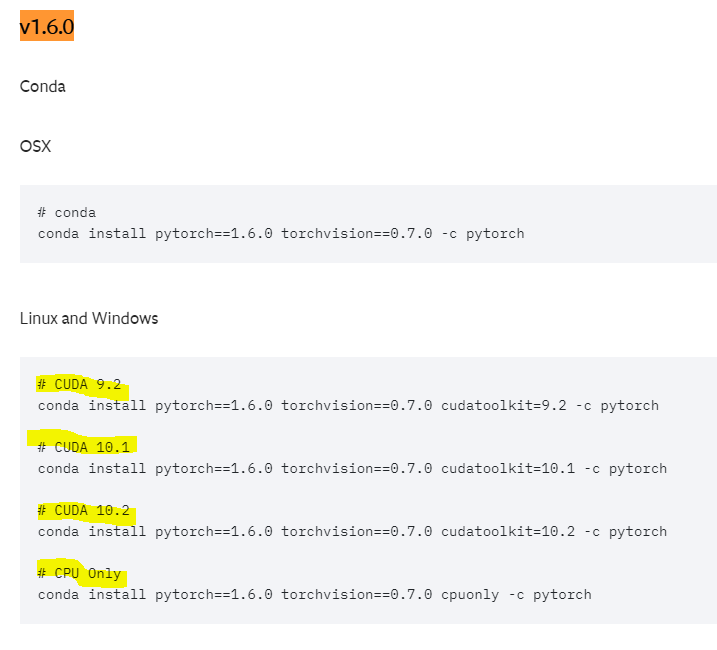
파이토치 v1.7.1과 cuda 11.0에 맞는 버전의 명령어를 복사하여 터미널에서 실행한다.
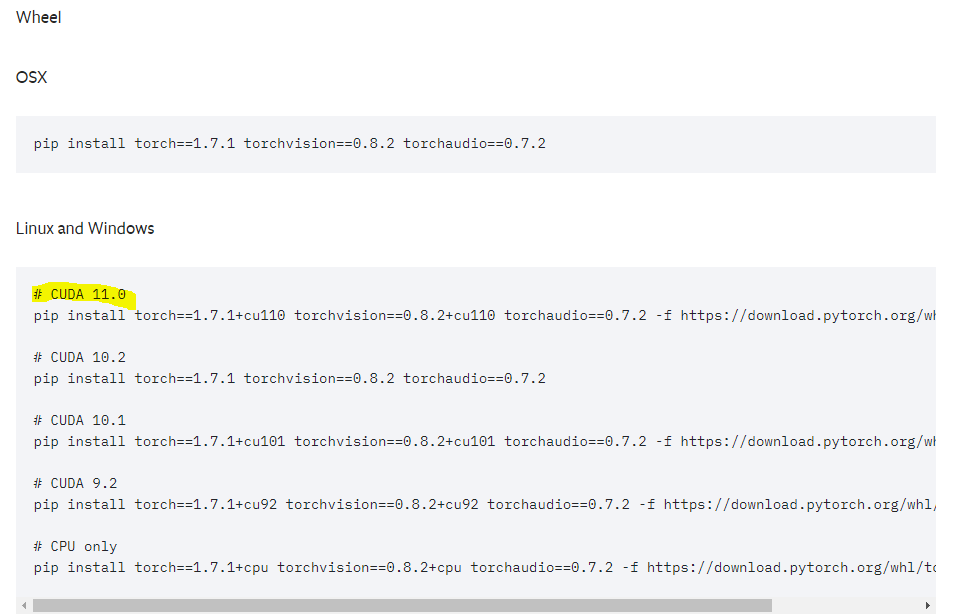
pytorch 버전 선택 / conda가 아닌 wheel 명령어 실행
-
v1.6.0 바로 위의 버전인 v1.7.0도 cuda 11.0에 맞는 버전이 있어 해당 명령어를 사용해보았으나 dependancy의 문제로 설치가 제대로 이뤄지지 않았다. 따라서 v1.7.1버전으로 설치했더니 문제가 발생하지 않았다. 이는 각자 구축된 가상환경마다 다를 수 있는 문제인 것 같으니 정확히 꼭 맞는 버전을 아는 것이 아니라면 그냥 버전을 하나씩 올려서 호환이 될 때까지 실행시켜보면 되는 것 같다.
-
conda 버전과 wheel 버전의 명령어가 따로 있는데
wheel 버전의 명령어를 사용했다. 처음에 conda 버전으로 사용했더니, cuda 11.0에 맞는 명령어를 실행하였는데도 불구하고 torch와 torchvision의 버전이 그대로였다.(단지 11.0버전의 cudatoolkit이 설치되었을 뿐.) 즉, 버전명에 +cu101이 붙어 있었다. 여전히 cuda 10.1에 호환되는 버전이라는 의미이다. 따라서 각 라이브러리마다 버전에 호환되는 cuda의 버전을 명시한 wheel 명령어를 권장하고 싶다.
여전히 torch, torchvision의 버전명에 +cu101이 붙어 있는 경우
이때는 cu110버전과 cu101버전이 함께 설치되어 있어서 문제가 생기는 것이므로 cu101버전을 삭제해주면 된다.
패키지가 설치되어 있는 경로로 이동한다. 가상환경 안에 설치되어 있는 패키지들을 관리하려는 명목이므로 가상환경 경로로 가면 있다. 가상환경의 경로는 conda env list를 통해 확인할 수 있다.
예를 들면 이런 식으로 되어 있다. -> /home/ubuntu/anaconda3/envs/가상환경명/lib/python3.8/site-packages/
쭉 내려보면 torch와 torchvision의 dist-info 폴더가 두 가지 버전 모두 존재하는 것을 확인할 수 있다. 여기서 cu101이 붙은 폴더만 삭제하면 된다.
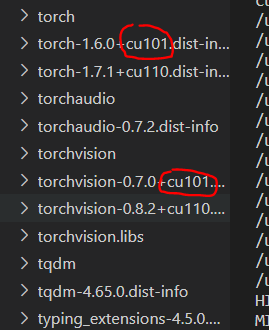
물론 터미널에서 명령어로 삭제해도 된다.
삭제하고도 제대로 구동하지 않을 경우
torch와 torchvision을 pip uninstall 명령어로 완전히 삭제한 다음 다시 설치해보자.
+) pip3과 conda의 패키지 버전이 서로 다른 경우
pip과 conda install로 서로 다른 버전이 모두 설치되어 있어서이다. 이 경우, 패키지를 삭제하려고 해도 metadata가 존재하지 않는다며 삭제되지 않을 것이다. 따라서 3번에서 한 것과 마찬가지로 직접 경로에 들어가 폴더를 삭제하면 된다.
이때도 터미널에서 명령어로 삭제해도 된다.
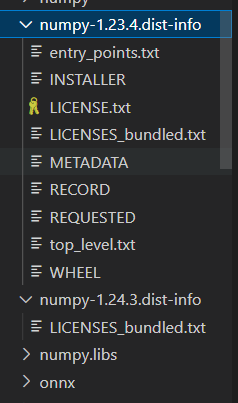
두 버전의 패키지 중 하나는 아래 이미지의 numpy-1.24.3.dist-info처럼 폴더 내에 METADATA를 비롯한 여러 파일들이 부재할 것이다.
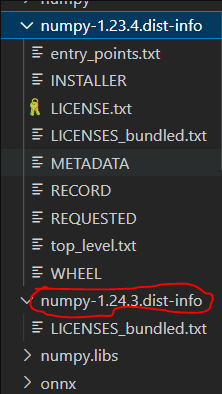
그 폴더를 삭제하면 된다.
