c++에서 문자열을 다뤄야하는 경우, 우리는 당연하다는 듯이 std::string을 사용한다
그만큼 다양한 환경에서 빈번하게 사용된다고 볼 수 있다
그렇기에 많은 사람들이 성능을 쥐어짜내기 위해 지난 30년간 노력해왔다
이런 노력들을 되짚어보고자 나도 한번 string 구현하기에 도전해보았다
그리고 일주일이면 끝날거라고 자만했던 나는 무려 한달이나지나 완성할 수 있었다 기능이 반쪽짜리긴한데..
이번 글에서는 구현 과정에서 겪었던 시행착오와 마지막 1%의 성능을 쥐어짜기 위한 노력들을 알아볼까한다
SSO
일반적으로 동적배열을 저장하기 위해서는 3가지 요소가 필요하다
- 시작 포인터
- 크기
- 용량
그리고 문자열도 문자들의 배열이기에 동일한 3가지 요소가 필요하다
그렇기에 가장 단순한 형태의 문자열은 아래와 같이 만들 수 있을 것이다
template <typename CharT>
class basic_string {
private:
size_t capacity;
size_t size;
CharT* data;
};물론 한때는 저런 형태로 존재했던적이 있다 (한 25년 전쯤..?)
https://github.com/vincenthsu/stlport/blob/a2e414fa18838a1d23ecf77dd7fa590bb562869f/stlport/stl/_string.h#L114
허나 위와 같은 구현체는 문자열의 길이와 상관없이 매번 새롭게 메모리를 할당받아야한다
그리고 최적화에서 항상 나오는 이야기 중 하나가 바로 메모리 할당은 비싸다는 것이다
그렇다면 충분이 짧은 문자열은 메모리 할당없이 저장하여 최적화할 수 있지 않을까
일반적으로 std::string은 앞서 말했듯, 포인터 3개를 가지고 있어야하고 이것은 64bit 기준 24byte이다
즉, 이론상 메모리 할당없이도 24byte의 공간을 사용할 수 있다는 이야기이다
하나의 문자를 저장하기 위해서 ASCII는 1byte, UTF8은 보통 2~3byte 정도를 필요로한다
따라서 이론상 우리는 메모리할당 없이도 24개의 ASCII 문자를 저장할 수 있다
이러한 발상에서 시작된 최적화가 Short String Optimization, 즉 SSO이다
이것을 이루기 위해서는 메모리 할당받을 공간과, 할당받지 않을 공간을 Union으로 묶을 필요가 있다
union SSO {
struct Large {
size_type size;
size_type capacity;
value_type data;
};
static constexpr size_type SmallCapacity = sizeof(Large);
Large large;
value_type small[SmallCapacity];
};위 구현에서의 문제는 둘중 현재 어떤놈이 활성화 되었는지 알방법이 없다는 것이다
또한 Short String의 크기와 null terminator가 위치할 공간이 없다
위 세가지 정보를 한데 묶어 1byte에 우겨넣는 방법도 존재하지만, 오늘은 2byte로 풀어볼 생각이다
구현이 더 복잡해지는 감도 있고, 굳이 1byte을 위해 추가적인 성능을 희생시키지 않고 싶기 때문이다
만약 SSO-23의 구현을 원한다면 페이스북의 FBString이나 EASTL의 구현체를 참고하면 된다
https://github.com/facebook/folly/blob/main/folly/FBString.h
https://github.com/electronicarts/EASTL/blob/master/include/EASTL/string.h
2byte에 해당 정보들을 저장하기 위해서는 우선 활성화 비트와 사이즈를 엮을 필요가 있다
이것은 bitfield를 활용하여 쉽게 해결할 수 있다
또한 메모리 할당의 경우에도 동일한 비트에 layout을 표시해주어야한다
libc++의 경우 size의 1bit을 사용하여 표기하는데, 나도 동일하게 구현하였다
struct Large {
size_type layout : 1;
size_type size : (sizeof(size_type) * 8 - 1);
size_type capacity;
pointer data;
};
static constexpr size_type SmallCapacity = (sizeof(Large) / sizeof(value_type)) - 2;
struct Small {
unsigned char layout : 1;
unsigned char size : 7;
value_type data[SmallCapacity + 1];
};
static_assert(sizeof(Large) == sizeof(Small));
union SSO {
Large large;
Small small;
} sso;이렇게 표기한 layout은 다음과 같이 간단한 함수로 확인할 수 있다
bool is_long() const noexcept {
return sso.large.layout == 1;
}이제 데이터가 단순히 포인터를 가르키지 않으므로, 이것을 layout에 맞게 반환할 필요가 있다
const_pointer data() noexcept {
return is_long() ? sso.large.data : sso.small.data;
}마찬가지로 size와 capacity의 경우에도 비슷하게 조정해줘야 한다
이때 small capacity의 경우 null terminator까지 고려하여 계산해주면 된다
size_type size() const noexcept {
return is_long() ? sso.large.size : sso.small.size;
}
size_type capacity() const noexcept {
return is_long() ? sso.large.capacity : SmallCapacity;
}이런식으로 나머지 함수들도 구현해주면 쉽게 SSO가 적용된 string을 구현할 수 있다
https://godbolt.org/z/MoGPMsxro
Constexpr Problem
c++20에 큰 변경점중 하나로 cosntexpr vector와 string이 등장하였다
이를 위해 object lifetime을 새로 정립하고 constexpr 구문에서 new를 허용하는 등의 변화가 있었다
다만 이러한 변화는 SSO에 심각한 문제를 일으켰다
우선 constexpr funtion에 대해서 짚고 넘어가야할 것이 있다
함수가 constant evaluated되기 위해서는 아래 4가지 조건이 필요하다
(물론 이 4가지 이외에도 많은 조건들이 존재하고, 예외도 많이 존재한다)
- constexpr 함수안에서는 constexpr 함수만 호출할 수 있다
- undefined behaviour가 함수 내부에 포함될 수 없다
- pointer간 reinterpret_cast가 수행될 수 없다
- void*가 어떠한 형태로도 등장할 수 없다
이 중에서 오늘 살펴볼 것은 undefined behaviour가 존재하면 안되는 것이다
그렇다면 이것이 SSO랑 어떠한 관계가 있길래 그런것일까
Active Member in Union
A union is a special class type that can hold only one of its non-static data members at a time.
cppreference
c++에서 union이란 여러개의 타입이 공존할 수 있는 새로운 타입이다
그리고 union안에 존재하는 member들도 다른 object들과 마찬가지로 lifetime이 존재한다
따라서 임의의 member가 활성화되어 lifetime이 지속되는 동안은 다른 member가 활성화될 수 없다
문제는 inactive member를 접근할때 발생한다
standard에 따르면, inactive member를 직접적으로 접근하는것은 undefined behaviour이다
최적화를 위해 일부 예외 케이스가 존재하기는 하지만, 이건 지금 해당되는 이야기는 아니다
https://stackoverflow.com/questions/11373203/accessing-inactive-union-member-and-undefined-behavior
다시 돌아와 위에서 구현했던 SSO의 가장 큰 문제는 is_long() 함수에 있다
bool is_long() const noexcept {
return sso.large.layout == 1;
}문자열에 접근하기 이전에 항상 short인지 long인지를 구분해야한다
그런데 저 bit을 접근하기 위해서는 short 혹은 long 둘중 하나는 반드시 접근해야한다
즉, 어떤놈이 활성화 된지도 모른채 둘중 한개를 접근해야한다는 것이다
이것은 명백한 undefined behaviour이고, constant evaluation이 불가능하다
실제로 위 구현의 constexpr 버전을 실행해보면 에러가 발생한다
clang의 오류 메세지를 보면 알 수 있듯, 친절하게 inactive member에 접근하고 있다고 알려준다
https://godbolt.org/z/dEvbsjd95
<source>:64:15: error: static assertion expression is not an integral constant expression
64 | static_assert(foo() == 0);
| ^~~~~~~~~~
<source>:54:16: note: read of member 'large' of union with no active member is not allowed in a constant expression
54 | return m_Storage.large.layout == 1;
| ^
<source>:45:16: note: in call to 'this->is_long()'
45 | return is_long() ? m_Storage.large.size : m_Storage.small.size;
| ^~~~~~~~~
<source>:61:12: note: in call to 'str.size()'
61 | return str.size();
| ^~~~~~~~~~
<source>:64:15: note: in call to 'foo()'
64 | static_assert(foo() == 0);
| ^~~~~
1 error generated.
Compiler returned: 1이것을 해결하는 방법으로 세가지 정도를 알고있다
- SSO-22(23)을 포기하고 SSO-15로 만족하기
- constant evaluated인 경우, 항상 long string으로 취급하기
std::bit_cast를 사용하여 bit field 읽기
(union을 bit_cast하는건 constexpr 구문에서 불가능하다. cppcon 영상에서 누가 된다고 했었는데, union을 직접 casting하지 않고 읽는 다른 방법이 필요해보인다.)
https://en.cppreference.com/w/cpp/numeric/bit_cast.html
일반적으로는 1번을 선택하곤 한다
비록 7~8byte의 손해가 있음에도 구현도 더 심플해지고, 성능적인 측면에서의 우위가 있기 때문이다
(여기서 말하는 성능이란, size를 접근할 경우 분기가 없어 발생하는 소소한 이득이다)
이런 이유 때문만은 아니겠지만 현재 GCC와 MSVC는 SSO-15로 구현되어 있다
https://github.com/microsoft/STL/blob/main/stl/inc/xstring#L424
https://github.com/gcc-mirror/gcc/blob/master/libstdc%2B%2B-v3/include/bits/basic_string.h#L218
하지만 clang은 여기서 조금 다른 선택을 한다
더 번거롭지만 더 큰 SSO 용량을 확보할 수 있는 두번째 방법을 선택하여 구현하였다
그리고 이번 글에서도 두번째 방법에 기반하여 설명해볼까 한다
Forcing Long String
이제 무엇을 해야하는지를 파악했으니 어떻게 해야할지를 생각해보자
고쳐야할 곳은 큰 맥락에서 두가지 경우가 존재한다
- short string으로 초기화되는 경우
- long string에서 short string으로 변경되는 경우
이 두가지에 해당하는 함수들을 추려보면 다음과 같다
- constructor
- assign (operator=)
- shrink_to_fit
아무래도 초기화와 관련되어있는 부분이다보니 생각보다 그렇게 많지는 않다
우선 생성자는 아래와 같이 변경하면 된다
constexpr basic_string(const_pointer str)
: m_Alloc{}
{
pointer buffer;
size_type len = string_length(str);
if (std::is_constant_evaluated() || len > SmallCapacity) {
std::construct_at(&sso.large);
buffer = m_Alloc.allocate(len + 1);
sso.large.size = len;
sso.large.capacity = len + 1;
sso.large.layout = 1;
sso.large.data = buffer;
}
else {
buffer = sso.small.data;
sso.small.size = len;
sso.small.layout = 0;
}
begin_lifetime(buffer, len + 1);
string_copy(buffer, str, len);
buffer[len] = value_type(0);
}여기서 신경써줘야할 곳은 3군데 정도가 있다
- constant evaluated인 경우, 항상 long string으로 생성
- union member를 직접 활성화 시켜줘야한다는 것
- 할당 받은 메모리의 각 element도 활성화 시켜줘야한다는 것
우선 첫번째는 if문 조건을 추가해줌으로써 쉽게 해결 가능하다
두번째부터 살짝 까다로운데 lifetime 문제를 std::construct_at로 해결해줘야한다
물론 trivial type의 경우 이것을 호출한다고해서 뭘 추가적으로 하진않는다
그럼에도 불구하고, constant evaluation을 위해 명시적으로 호출해줘야한다
우선 Large 오브젝트를 활성해주기 위해 해당 위치에서 std::construct_at을 호출했다
그리고 추가적으로 문자열의 각 문자들도 활성화 해줘야하기에 동일한 호출이 필요하다
위 코드에서 begin_lifetime 함수를 통해 해결하는 부분인데, 구현은 다음과 같다
constexpr void begin_lifetime(pointer ptr, size_type len) {
if (std::is_constant_evaluated()) {
for (size_type i = 0; i < len; ++i) {
std::construct_at(&ptr[i]);
}
}
}char은 POD type이기에, 마찬가지로 constructor을 호출한다해도 no-op이다
다만 반복문이 존재하는 만큼, 이 경우에는 constant evaluated인 상황만 분기하여 넣었다
이러한 처리들을 모두 넣어줄 경우, 정상적으로 동작하는 것을 확인할 수 있다
마찬가지로 assign 또한 비슷하게 구현할 수 있다
차이점이라고 해봐야 이전에 할당받았던 메모리가 있을 경우, 해제해줘야한다는 점 정도이다
constexpr void assign(const_pointer ptr) {
pointer buffer;
size_type len = string_length(ptr);
if (std::is_constant_evaluated() || len > capacity()) {
buffer = m_Alloc.allocate(len + 1);
begin_lifetime(buffer, len + 1);
string_copy(buffer, ptr, len);
if (is_long()) {
m_Alloc.deallocate(sso.large.data, sso.large.capacity);
}
sso.large.data = buffer;
sso.large.layout = 1;
sso.large.capacity = len + 1;
}
else {
buffer = data();
string_move(buffer, ptr, len);
}
buffer[len] = value_type(0);
set_size(len);
}shrink_to_fit도 현재 long string인 경우만 고려하면 되기에 그렇게 복잡하지는 않다
이후에 short string으로 갈지, 아니면 크기만 줄인 long string으로 갈지 정도만 정하면 된다
소소한 팁이라고 한다면, 문자열 복사시 null ternimator를 같이 복사하는 정도일 것이다
(물론 이걸 할려면, 문자열 수정 동작 이후에 항상 null terminator를 넣어줘야한다)
constexpr void shrink_to_fit() {
if (!is_long()) [[unlikely]] {
return;
}
size_type len = sso.large.size;
if (!std::is_constant_evaluated() && len <= SmallCapacity) {
pointer buffer = sso.large.data;
string_copy(sso.small.data, buffer, len + 1);
sso.small.layout = 0;
sso.small.size = static_cast<unsigned char>(len);
m_Alloc.deallocate(buffer, len);
}
else {
pointer buffer = m_Alloc.allocate(len + 1);
string_copy(buffer, sso.large.data, len + 1);
sso.large.data = buffer;
sso.large.capacity = len + 1;
}
}https://godbolt.org/z/3a39PKWbK
Memory Operations
혹시 문자열 복사시 for문을 돌리는것과 memcpy의 성능 차이를 비교해본적이 있는가
직접 비교해보고 그 결과를 두 눈으로 확인한다면 안놀랄수가 없다
(컴파일러의 constant folding을 방지하기위해 코드가 좀 이상한데, asm을 보면 재대로한게 맞다)
https://godbolt.org/z/7ja5db65G
https://quick-bench.com/q/YLPGQqerUV_SHHvDbU3y4WUkkME
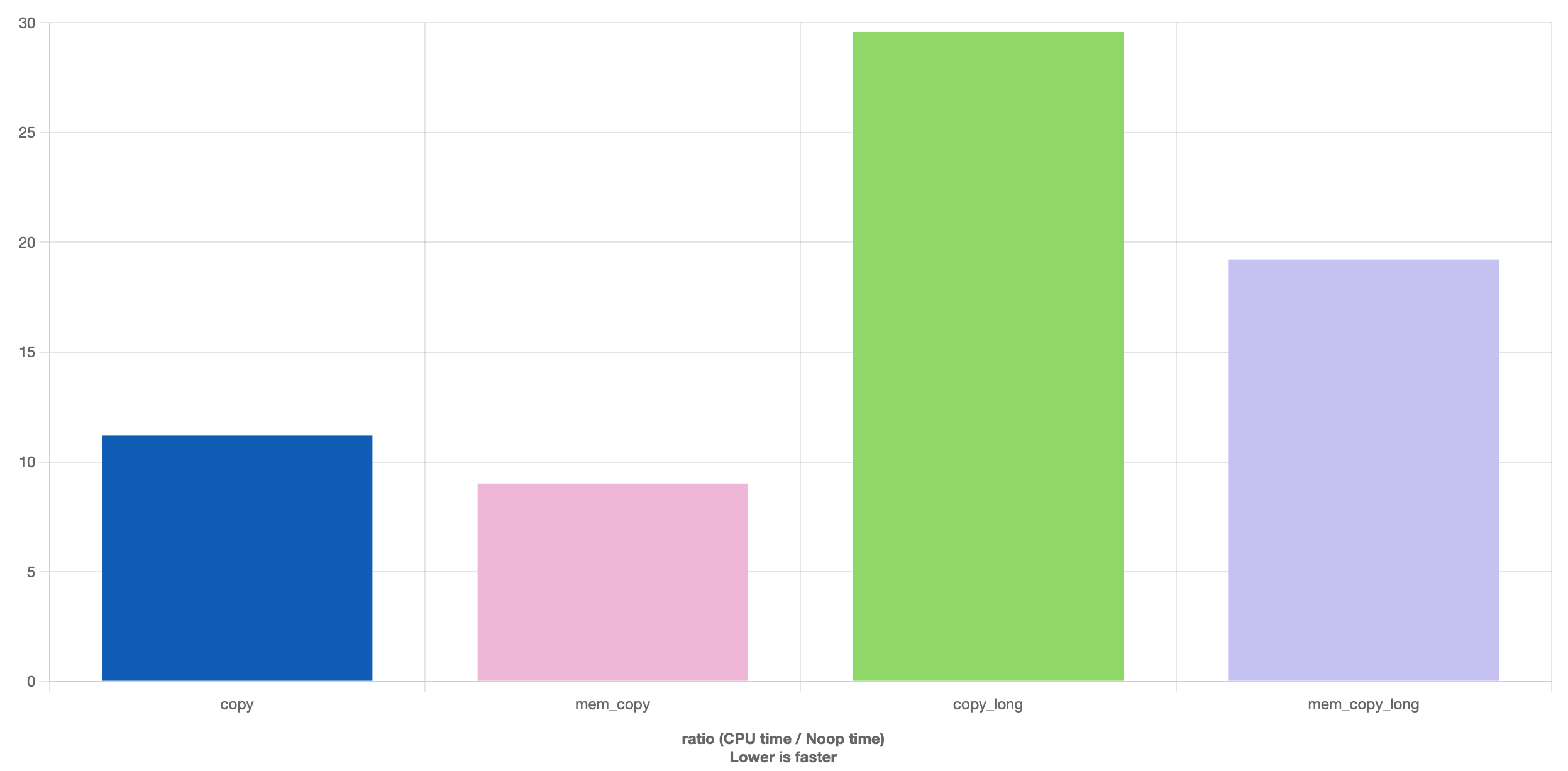
짧든 길든, memcpy가 일방적으로 빠른것을 확인할 수 있다
실제로 memcpy는 각 플랫폼에 맞게 가장 최적화된 구현체이다
glibc나 libc++의 memcpy 구현체를 본다면 메모리 복사하는게 이렇게까지 복잡해야하나 싶을정도다
어찌되었건 성능을 위해서 우리는 일반적인 copy 대신, memcpy를 사용해 문자열을 복사할 필요가 있다
Another Constexpr Problem
여기서 다시 constexpr 문제가 발생한다
메모리 관련 동작들 대부분은 constexpr가 아니다 (앞으로 최소 10년은 constexpr를 못달지 않을까)
이 경우에도 여러가지 해결방법이 있겠지만, 위와 동일하게 분기처리하는 식으로 해결하였다
사실 bit_cast를 사용하고 싶긴했는데, 윈하는 위치에 복사를 해주는게 아니라 포기했다
우선 문자열의 길이를 측정하는 strlen은 다음과 같이 변경해주면 된다
constexpr size_type string_length(const_pointer str) const {
if (!std::is_constant_evaluated()) {
if constexpr (std::same_as<value_type, char>) {
return strlen(str);
}
else if constexpr (std::same_as<value_type, wchar_t>) {
return wcslen(str);
}
}
size_type len = 0;
for (; *str != value_type(0); ++len, ++str);
return len;
}위 코드를 보면 타입에 따라 다시한번 더 분기하고 있다는 것을 발견할 수 있다
이것은 strlen이 char만 받기 때문에 해준 처리이다
사소한 처리지만 wchar_t도 마찬가지로 처리해줄 수 있다
나머지는 strlen 같은 구현체가 없기에 어쩔 수 없이 반복문을 돌리면서 직접 비교해야한다
그에 비해 memcpy와 memmove는 비교적 단순하게 구현이 가능하다
strlen 같이 특정 타입으로 동작하지 않고 void*로 동작하기 때문이다
constexpr void string_copy(pointer dst, const_pointer src, size_type len) {
if (!std::is_constant_evaluated()) {
memcpy(dst, src, len * sizeof(value_type));
return;
}
for (; len; --len) *(dst++) = *(src++);
}
constexpr void string_move(pointer dst, const_pointer src, size_type len) {
if (!std::is_constant_evaluated()) {
memmove(static_cast<void*>(dst), static_cast<void const*>(src),
len * sizeof(value_type));
return;
}
if (static_cast<const_pointer>(dst) < src) {
for (; len != 0; --len) *dst++ = *src++;
}
else {
const_pointer s = src + len;
pointer d = dst + len;
for (; len != 0; --len) *(--d) = *(--s);
}
}이런식으로 strcmp나 strchr 등을 전부 구현해주면 되는데 귀찮은 관계로 넘어간다
https://godbolt.org/z/7Gnsca1Wo
Builtin Functions
컴파일러만이 할 수 있는 일들중 하나로 builtin 함수라는 것이 존재한다
이 함수들은 해당 컴파일러에 한해서만 동작하지만, 그 만큼 성능을 더 쥐어짜낸다
물론 오늘날 memcpy 같은 함수들의 내부 구현은 사실상 이 내장 함수들로 되어있다
예로 clang의 memcpy 구현을 따라가다 보면 아래와 같이 __builtin_memcpy_inline을 만날 수 있다
그리고 __builtin_memcpy_inline은 __builtin_memcpy와 동일하다
https://clang.llvm.org/docs/LanguageExtensions.html#guaranteed-inlined-copy
// llvm-project/libc/src/string/memcpy.cpp
// llvm-project/libc/src/string/memory_utils/inline_memcpy.h
// llvm-project/libc/src/string/memory_utils/aarch64/inline_memcpy.h
// llvm-project/libc/src/string/memory_utils/op_builtin.h
// llvm-project/libc/src/string/memory_utils/utils.h
template <size_t Size>
LIBC_INLINE void memcpy_inline(void *__restrict dst,
const void *__restrict src) {
#ifdef LLVM_LIBC_HAS_BUILTIN_MEMCPY_INLINE
__builtin_memcpy_inline(dst, src, Size);
#else
// ...
}https://github.com/llvm/llvm-project/blob/llvmorg-20.1.6/libc/src/string/memory_utils/utils.h#L86
그렇다면 결과적으로 내장 함수를 사용하게 되는데 굳이 내장 함수를 써야할까 싶을 것이다
그런데 놀랍게도 벤치마크를 찍어보면 약간의 차이가 발생한다
https://godbolt.org/z/9Gnx3eKo4
https://quick-bench.com/q/078690-CBmFn1SqWw2LDJiZ7CSI
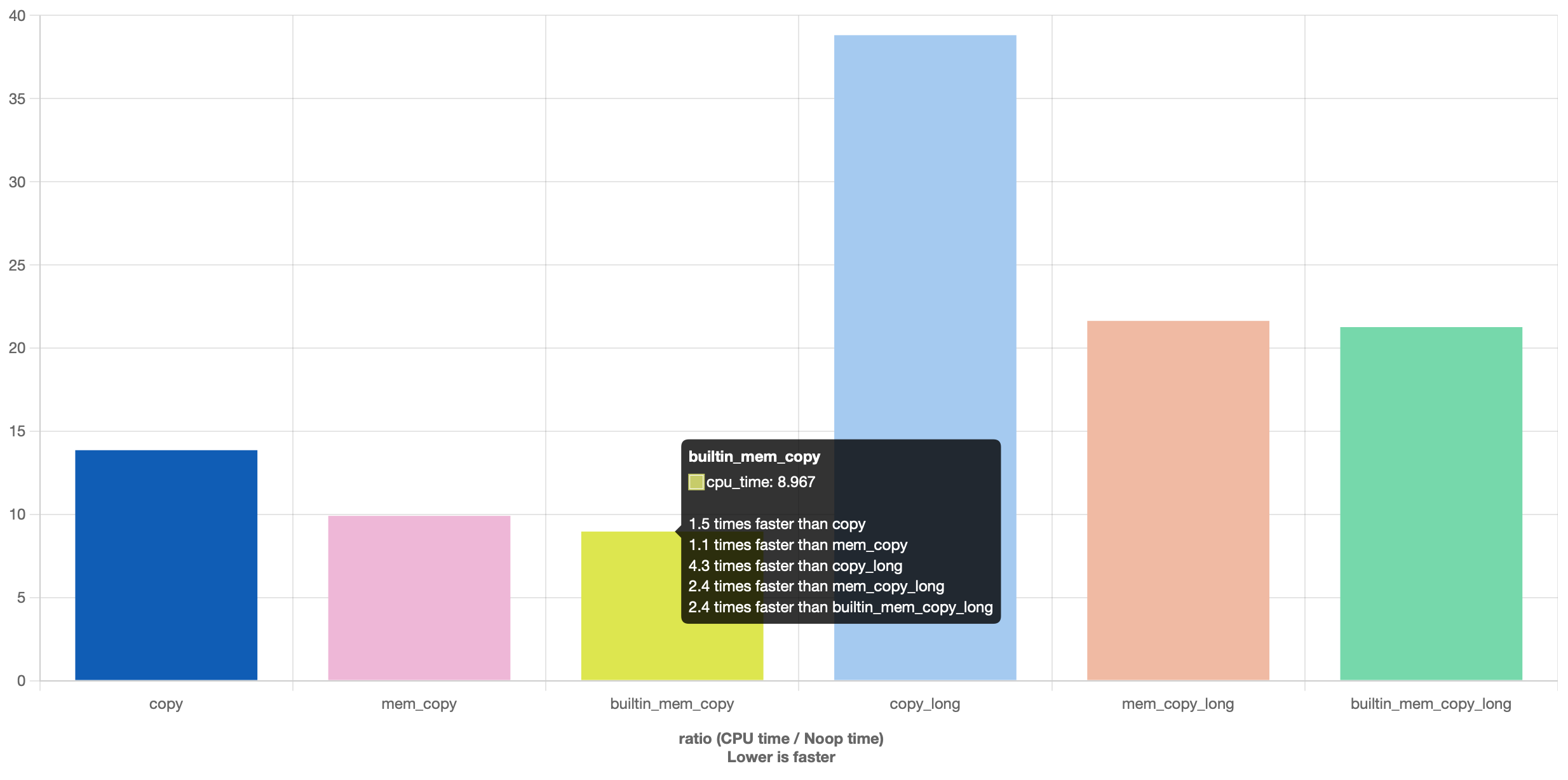
문자열이 충분히 짧다면, 아주 근소한 차이지만 builtin 쪽이 더 빠른걸 확인할 수 있다
대신 긴 문자열은 오차 수준의 차이만 보일뿐 사실상 동일한 결과를 보여준다
물론 이것은 컴파일러마다 다르고, 심지어는 버전에 따라 결과가 달라질 수 있다
허나 이미 컴파일러들이 흔하게 사용하고 있는만큼 내장 함수가 느려질일은 없다고 봐도 무방하다
따라서 진정 속도를 원한다면 내장함수도 도입하는것이 좋다
builtin 함수를 적용하기 이전에 컴파일러의 지원여부를 체크해줘야한다
이는 간단한 매크로로 확인할 수 있다
여기서 주의할 점은 호완성을 위해 __has_builtin 매크로를 미리 체크해야한다는 점 정도이다
#ifndef __has_builtin
# define __has_builtin(x) 0
#endif
#if __has_builtin(__builtin_strlen)
# define BUILTIN_STRLEN __builtin_strlen
#else
# define BUILTIN_STRLEN strlen
#endif
#if __has_builtin(__builtin_wcslen)
# define BUILTIN_WCSLEN __builtin_wcslen
#else
# define BUILTIN_WCSLEN wcslen
#endif
#if __has_builtin(__builtin_memcpy)
# define BUILTIN_MEMCPY __builtin_memcpy
#else
# define BUILTIN_MEMCPY memcpy
#endif
#if __has_builtin(__builtin_memmove)
# define BUILTIN_MEMMOVE __builtin_memmove
#else
# define BUILTIN_MEMMOVE memmove
#endif위 매크로를 기반으로 메모리 관련 함수들을 다시 작성하면 다음과 같다
단순히 함수 호출부에서 이름만 매크로로 바꿔주면 된다
constexpr size_type string_length(const_pointer str) const {
if (!std::is_constant_evaluated()) {
if constexpr (std::same_as<value_type, char>) {
return BUILTIN_STRLEN(str);
}
else if constexpr (std::same_as<value_type, wchar_t>) {
return BUILTIN_WCSLEN(str);
}
}
size_type len = 0;
for (; *str != value_type(0); ++len, ++str);
return len;
}
constexpr void string_copy(pointer dst, const_pointer src, size_type len) {
if (!std::is_constant_evaluated()) {
BUILTIN_MEMCPY(dst, src, len * sizeof(value_type));
return;
}
for (; len; --len) *(dst++) = *(src++);
}
constexpr void string_move(pointer dst, const_pointer src, size_type len) {
if (!std::is_constant_evaluated()) {
BUILTIN_MEMMOVE(static_cast<void*>(dst), static_cast<void const*>(src),
len * sizeof(value_type));
return;
}
if (static_cast<const_pointer>(dst) < src) {
for (; len != 0; --len) *dst++ = *src++;
}
else {
const_pointer s = src + len;
pointer d = dst + len;
for (; len != 0; --len) *(--d) = *(--s);
}
}https://godbolt.org/z/aje4Pq5fP
Inlining
많은 사람들이 inlining이 빠른 이유를 function call이 비싸서라고 답한다
이것도 맞는 말이지만, 그 외에도 몇가지 이유가 더 있다
그리고 여기서 이야기하고 싶은 부분은 constant folding과 관련된 부분이다
컴파일러는 컴파일 시간에 constant를 만날경우, 이를 최대한 할용하여 최적화한다
예를들어 loop 횟수가 constant라면 이를 unrolling한다
혹은 조건문이 constant evaluation때 계산 가능하다면 분기를 없애버린다
SSO를 예를 들어 생각해보면 이해가 쉽다
만약 컴파일 시간에 문자열의 길이를 안다면 어떨까
굳이 short / long 분기 없이 문자열을 생성하거나 변경할 수 있게된다
혹은 더 나아가 strcpy 연산이 unrolling 되어 단순 mov 연산으로 바뀔 수 있을 것이다
허나 이러한 최적화를 위해서는 inlining이 전제되어야한다
함수는 어딘가에서 호출될 수 있는 존재이기에, 함부로 변수의 값을 단정할 수 없다
그러나 함수가 inline 되었고, 변수가 constant로 정해져있다면 어떨까
이 경우에는 컴파일러가 constant folding을 최대한 활용할 수 있게된다
이처럼 inlining은 최적화에서 굉장히 중요하기에 직접 만든 string이 재대로 inlining되고 있는지를 확인해볼 필요가 있다
Splitting Functions
godbolt에서 llvm의 opt-viewer를 켜서 inline 여부를 확인해볼 경우 다음과 같다
https://godbolt.org/z/9v1bvrYWj
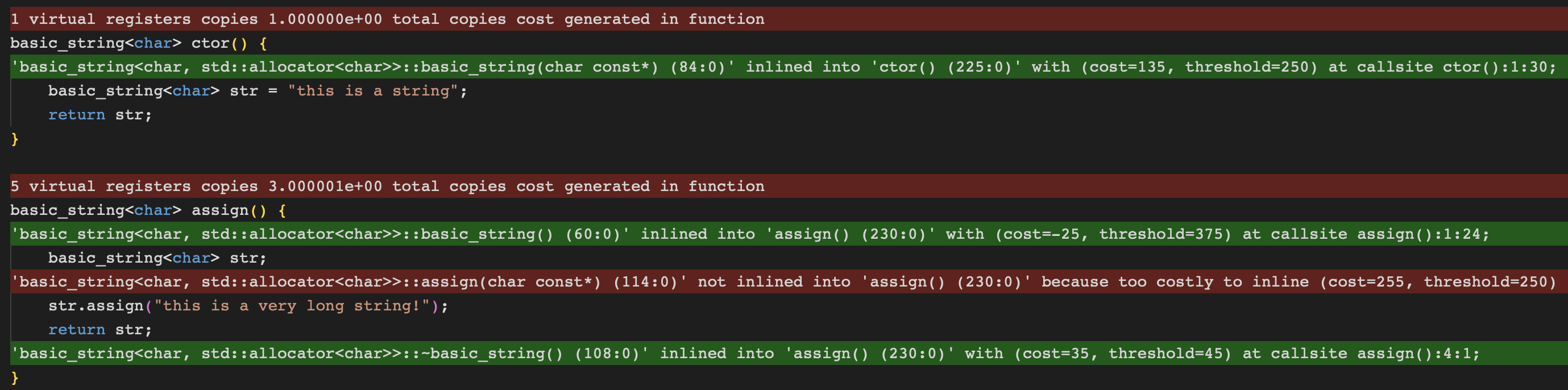
생성자의 경우 아무런 문제없이 inline 되었다
반면에 assign의 경우 높은 비용으로 인해 inline되지 않은 것을 확인할 수 있다
이를 확인해보기 위해서는 assign 함수 내부의 inline 여부도 확인해볼 필요가 있다
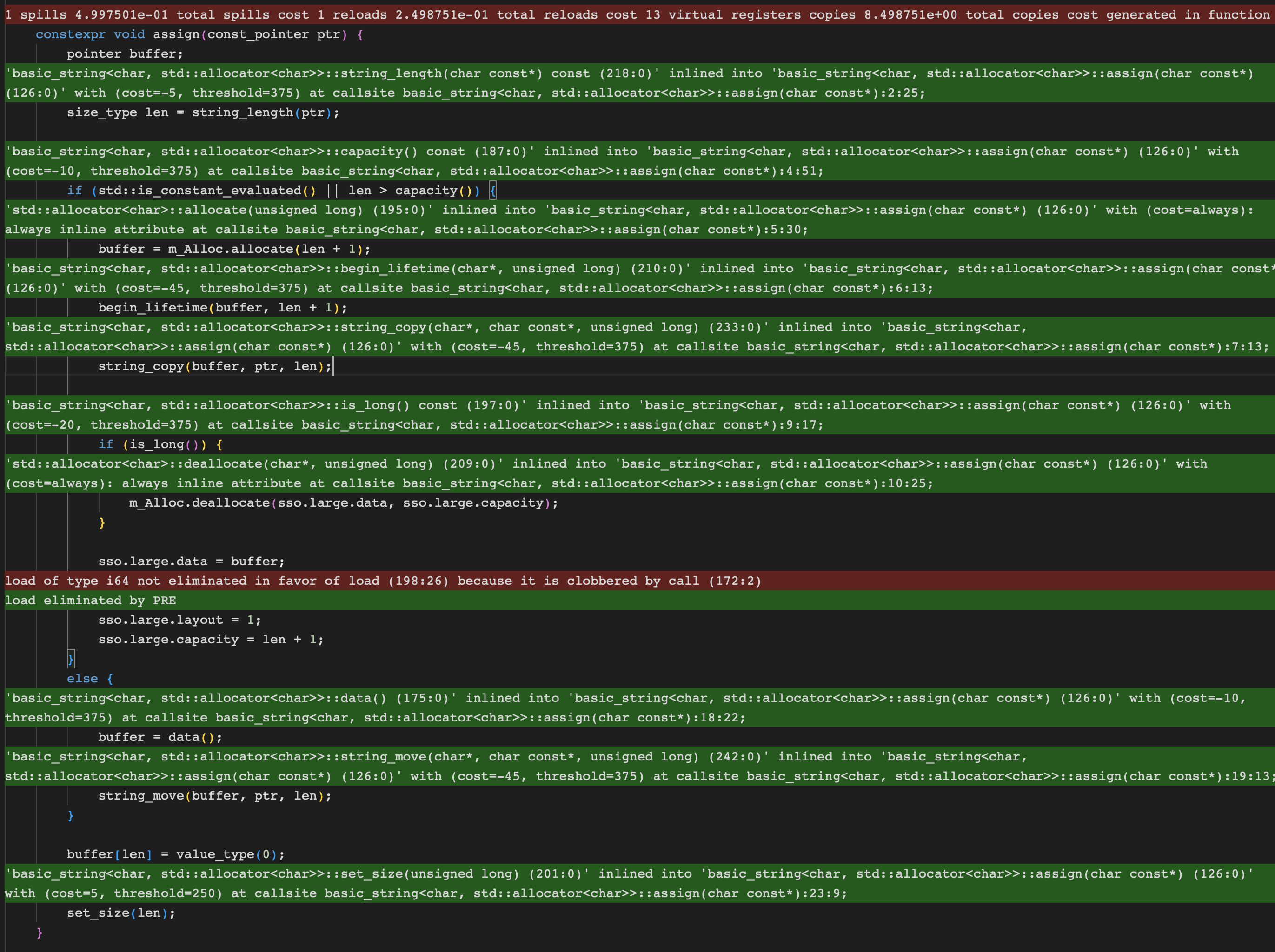
assign 내부를 관찰할 경우, 전체가 다 inline된 것을 확인할 수 있다
이것은 오히려 역효과를 일으키는데, allocation이 포함됨으로 인해 함수 전체의 비용이 증가하였다
즉, allocation이 inline되어 포함되는 바람에 오히려 assign이 inline되지 않은것이다
그렇다는 이야기는 해당 부분만 inline에서 제외시킨다면, 문제가 해결된다는 소리이다
따라서 allocation 부분만 떼서 새로운 함수로 만들어주었다
https://godbolt.org/z/T8WjT7cvP
constexpr void assign(const_pointer ptr) {
pointer buffer;
size_type len = string_length(ptr);
if (std::is_constant_evaluated() || len > SmallCapacity) {
buffer = assign_long(ptr, len);
}
else {
buffer = data();
string_move(buffer, ptr, len);
}
buffer[len] = value_type(0);
set_size(len);
}
constexpr pointer assign_long(const_pointer ptr, size_type len) {
pointer buffer;
if (len > capacity()) {
buffer = m_Alloc.allocate(len + 1);
begin_lifetime(buffer, len + 1);
string_copy(buffer, ptr, len);
if (is_long()) {
m_Alloc.deallocate(sso.large.data, sso.large.capacity);
}
sso.large.data = buffer;
sso.large.layout = 1;
sso.large.capacity = len + 1;
}
else {
buffer = data();
string_move(buffer, ptr, len);
}
return buffer;
}
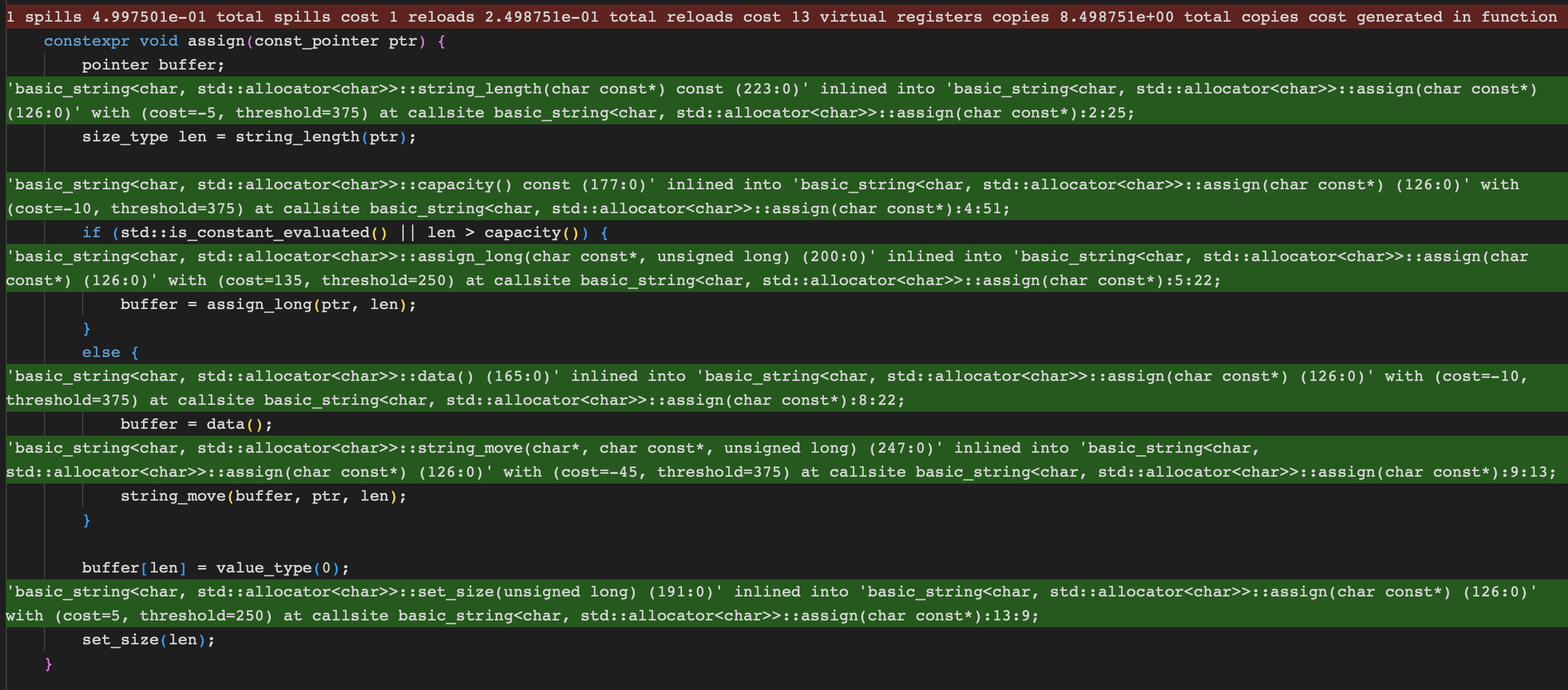
분명 함수를 분리 시켰는데 전혀 나아진게 없다
두 함수를 합치면 비용이 크지만, 쪼개놓으니 비용이 그다지 크지 않기 때문이다
따라서 컴파일러는 우선적으로 두 함수를 합쳐버린다 누가 컴파일러가 똑똑하다고 했어
이 상황을 해결하기 위해서는 컴파일러의 행동을 어느정도 직접 제어할 필요가 있다
Noinline Attribute
이러한 상황에 딱 맞는 금기시되는 attribute가 있으니 바로 noinline이다
이름에서 알 수 있듯, 함수를 inline 하지말라고 직접적인 힌트를 주는 역할을 한다
물론 말이 힌트지 3대 컴파일러들은 모두 해당 attribute에 대하여 inline 여부를 강제한다
다만 이 attribute는 c++ standard가 아닌 컴파일러 extension이라 추가 작업이 필요하다
아래와 같이 컴파일러 별로 매크로 지정해주면 noinline attribute를 사용할 수 있다
#if defined(__clang__) || defined(__GNUC__)
# define NOINLINE __attribute__((noinline))
#elif defined(_MSC_VER)
# define NOINLINE __declspec(noinline)
#endifnoinline attribute를 달아주고 다시 결과를 확인해볼 경우, 우리가 원하던 결과를 얻을 수 있다
https://godbolt.org/z/vehhzzrn1

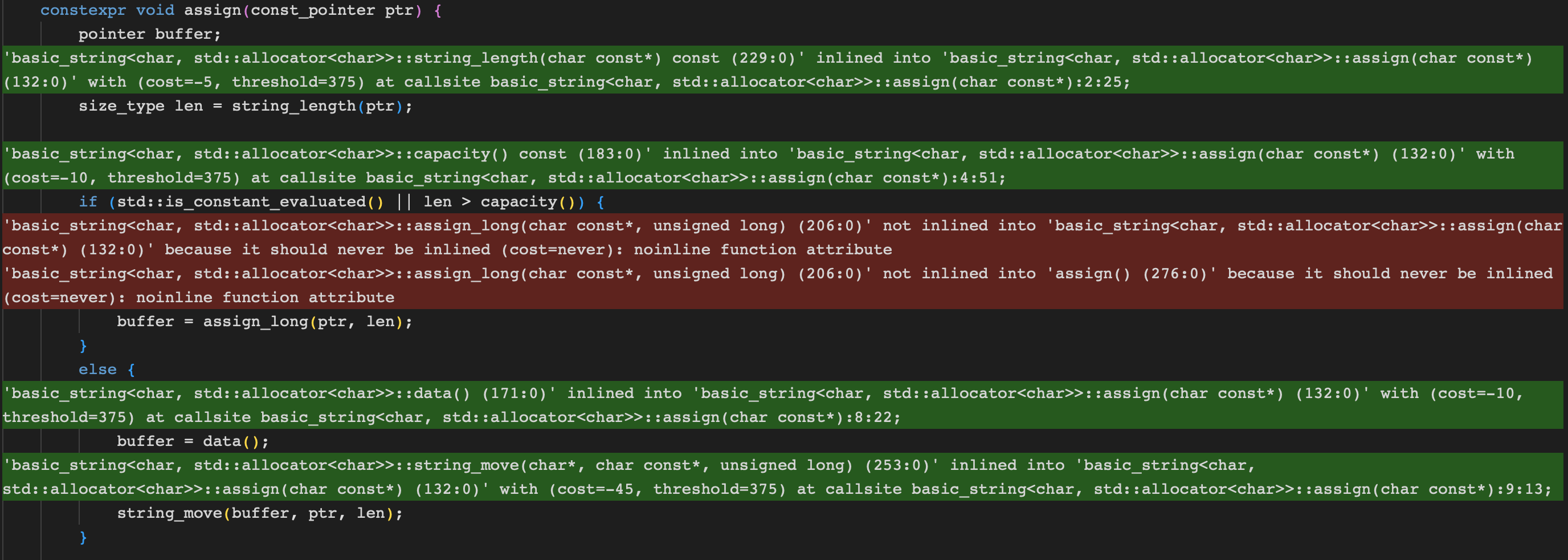
이와 같은 방법으로 allocation이 필요한 함수들을 직접 inline에서 제외시킬 수 있다
그리고 이러한 제어는 대부분의 상황에서 constant folding에 아주 큰 도움이 된다
그 차이는 string literal이 사용되는 경우와, 그렇지 않은 경우를 비교해보면 바로 알 수 있다
https://godbolt.org/z/z9rcT4YP5
basic_string<char> ctor() {
basic_string<char> str = "this is a string";
return str;
}
// compiled result
ctor():
mov rax, rdi
mov byte ptr [rdi], 32
movups xmm0, xmmword ptr [rip + .L.str]
movups xmmword ptr [rdi + 1], xmm0
mov byte ptr [rdi + 17], 0
retbasic_string<char> ctor(char const* src) {
basic_string<char> str(src);
return str;
}
// compiled result
ctor(char const*):
push r15
push r14
push r13
push r12
push rbx
mov r14, rsi
mov rbx, rdi
mov rdi, rsi
call strlen@PLT
mov r15, rax
cmp rax, 23
jb .LBB1_3
mov r13, r15
inc r13
js .LBB1_5
mov rdi, r13
call operator new(unsigned long)@PLT
mov r12, rax
mov qword ptr [rbx + 8], r13
lea rax, [2*r15 + 1]
mov qword ptr [rbx], rax
mov qword ptr [rbx + 16], r12
jmp .LBB1_4
.LBB1_3:
lea r12, [rbx + 1]
lea eax, [r15 + r15]
mov byte ptr [rbx], al
.LBB1_4:
mov rdi, r12
mov rsi, r14
mov rdx, r15
call memcpy@PLT
mov byte ptr [r12 + r15], 0
mov rax, rbx
pop rbx
pop r12
pop r13
pop r14
pop r15
ret
.LBB1_5:
call std::__throw_bad_alloc()@PLT윈래는 assign으로 비교할려다가 함수가 너무 길어서 포기하고 생성자로 가져왔다
어찌되었건 생성자만 보아도 그 차이가 굉장하다는 것을 바로 알 수 있다
분명 동일한 함수를 호출하는데도 불구하고 당장 생성된 asm 길이부터 6~7배 차이난다
뿐만 아니라 위 경우에서는 분기는 물론 mem alloc과 memcpy까지 사라진것을 확인할 수 있다
이는 컴파일러가 short string임을 알고 분기와 메모리 할당 자체를 삭제해버린 것이다
또한 복사의 경우, x86에서 더 빠른 movups(SIMD 명령어)로 대체한 것을 확인할 수 있다
이는 short string에만 해당하는 것은 아니고, long string도 동일하게 동작한다
기껏해봐야 movups 한번더에 operator new 호출이 추가되는 것 정도이다 직접해보면 알 수 있다
이처럼 inline에 대한 직접적인 제어로 더 많은 최적화를 누릴 수도 있다
그리고 놀랍게도 이게 현재 libc++이 string을 구현하는 방식이다
(아래 링크에서 assign 함수 선언앞에 _LIBCPP_NOINLINE 매크로)
https://github.com/llvm/llvm-project/blob/llvmorg-20.1.6/libcxx/include/string#L2619
Benchmark
이제 모든 구현이 끝났으니, 성능을 비교할 차례이다
물론 작성중이던 코드를 완성해서 비교하면 좋겠지만, 그러기에는 시간이 너무 부족했다
따라서 이미 한달동안 만들어두었던 다른 코드를 사용해 벤치마크를 진행하였다
https://github.com/ross1573/mini_engine/blob/main/engine/source/core/string/string.cxx
quick-bench와 동일하게 google-bench를 사용하였고, 대략 15가지 함수들을 비교해보았다
_std가 붙은게 libc++의 구현체이고, 안붙은것이 직접 구현한 버전이다
https://github.com/ross1573/mini_engine/blob/main/bench/container/string.cpp
Running bin/bench/bench.string
Run on (16 X 24 MHz CPU s)
CPU Caches:
L1 Data 64 KiB
L1 Instruction 128 KiB
L2 Unified 4096 KiB (x16)
Load Average: 2.35, 2.70, 2.61
----------------------------------------------------------
Benchmark Time CPU Iterations
----------------------------------------------------------
NoOp 0.251 ns 0.251 ns 2766820291
CtorEmpty 0.263 ns 0.263 ns 2611657694
CtorEmpty_std 0.269 ns 0.269 ns 2606396843
CtorCh 0.532 ns 0.531 ns 1310027323
CtorCh_std 0.400 ns 0.400 ns 1747535974
CtorShort 0.621 ns 0.621 ns 1135184224
CtorShort_std 0.617 ns 0.617 ns 1134301270
CtorLong 13.6 ns 13.6 ns 51550188
CtorLong_std 12.8 ns 12.8 ns 54876137
CtorCopy 0.347 ns 0.347 ns 2018215840
CtorCopy_std 0.347 ns 0.347 ns 2021689844
CtorMove 0.619 ns 0.619 ns 1123793928
CtorMove_std 0.616 ns 0.616 ns 1133805212
CtorIter 1.62 ns 1.62 ns 432125440
CtorIter_std 0.623 ns 0.623 ns 1100836636
AssignOther 19.6 ns 19.6 ns 35574890
AssignOther_std 23.8 ns 23.8 ns 29441206
AssignCopy 0.347 ns 0.347 ns 2018565031
AssignCopy_std 1.06 ns 1.06 ns 653802328
AssignMove 2.02 ns 2.02 ns 346388896
AssignMove_std 1.27 ns 1.27 ns 550972861
AssignShort 0.625 ns 0.625 ns 1124118771
AssignShort_std 0.622 ns 0.622 ns 1109069016
AssignLong 19.4 ns 19.4 ns 36070761
AssignLong_std 20.2 ns 20.2 ns 34673549
AppendShort 2.68 ns 2.68 ns 259156556
AppendShort_std 0.736 ns 0.736 ns 951164497
AppendLong 23.9 ns 23.9 ns 29349613
AppendLong_std 23.7 ns 23.7 ns 29654483
InsertShort 9.58 ns 9.58 ns 73103996
InsertShort_std 9.83 ns 9.83 ns 71172930
InsertLong 38.1 ns 38.1 ns 18125136
InsertLong_std 44.6 ns 44.6 ns 16012810macOS clang 말고도 궁금하여 추가적으로 msvc에서도 비교해보았다
Run on (8 X 3200 MHz CPU s)
CPU Caches:
L1 Instruction 192 KiB (x8)
L1 Data 128 KiB (x8)
L2 Unified 16384 KiB (x8)
----------------------------------------------------------
Benchmark Time CPU Iterations
----------------------------------------------------------
NoOp 2.44 ns 2.43 ns 373333333
CtorEmpty 1.05 ns 1.05 ns 640000000
CtorEmpty_std 1.09 ns 1.09 ns 746666667
CtorCh 1.07 ns 1.07 ns 640000000
CtorCh_std 1.08 ns 1.07 ns 640000000
CtorShort 1.09 ns 1.10 ns 640000000
CtorShort_std 1.08 ns 1.07 ns 640000000
CtorLong 31.5 ns 32.1 ns 22400000
CtorLong_std 31.3 ns 31.4 ns 22400000
CtorCopy 1.07 ns 1.07 ns 746666667
CtorCopy_std 1.07 ns 1.07 ns 640000000
CtorMove 1.08 ns 1.07 ns 640000000
CtorMove_std 1.08 ns 1.07 ns 640000000
CtorIter 5.38 ns 5.47 ns 100000000
CtorIter_std 5.31 ns 5.31 ns 100000000
AssignOther 35.1 ns 35.3 ns 20363636
AssignOther_std 41.3 ns 40.8 ns 17230769
AssignCopy 1.07 ns 1.07 ns 640000000
AssignCopy_std 5.92 ns 5.94 ns 100000000
AssignMove 3.32 ns 3.30 ns 213333333
AssignMove_std 1.72 ns 1.73 ns 407272727
AssignShort 6.06 ns 6.14 ns 112000000
AssignShort_std 1.08 ns 1.10 ns 640000000
AssignLong 33.5 ns 33.0 ns 20363636
AssignLong_std 31.7 ns 31.4 ns 22400000
AppendShort 6.40 ns 6.42 ns 112000000
AppendShort_std 6.10 ns 6.14 ns 112000000
AppendLong 41.2 ns 40.5 ns 16592593
AppendLong_std 40.6 ns 40.5 ns 16592593
InsertShort 10.2 ns 10.3 ns 74666667
InsertShort_std 10.4 ns 10.3 ns 74666667
InsertLong 46.1 ns 46.5 ns 15448276
InsertLong_std 45.9 ns 46.0 ns 14933333위 결과를 보면 알 수 있듯, 대부분의 경우에 libc++ 혹은 MSVC 구현체와 결과가 비슷하다
일부 상황에서 약간 아쉬운 모습을 보이기는 하지만, 이것은 당장에 해결하기는 힘든부분이라 냅뒀다
예를 들어 iterator를 사용하는 경우 contiguous_iterator에 대한 특수화를 하면 더 빨라질 수 있다
이런 부분들은 string에 연관된 부분이라 보기는 또 힘들어서, 나중에 시간나면 하나씩 수정해볼까 한다
약 한달간의 여정을 끝으로 나름 최적화가 잘된 string 구현체를 얻을 수 있었다
원래는 적당히하고 끝내려했는데, 오기가 생겨서 libc++과 비슷한 성능의 string이 되어버렸다
사실 중간에 libc++의 코드를 많이 컨닝하면서 비슷해진 감이있지 않나 싶긴하다
어찌되었건 원래의 목표를 한참 뛰어넘었으니 이제는 정말 만족하고 끝낼까한다
혹시라도 코드깎는 노인마냥 성능깎기에 도전하고 싶다면 한번쯤 해볼만한 짓거리라 생각한다
https://github.com/llvm/llvm-project
https://github.com/llvm/llvm-project/tree/llvmorg-20.1.6/llvm/tools/opt-viewer
https://www.youtube.com/watch?v=kPR8h4-qZdk
https://www.youtube.com/watch?v=rNl591__9zY
https://www.youtube.com/watch?v=qmEsx4MbKoc
https://www.youtube.com/watch?v=qq0q1hfzidg
