몇달전 C++ 23의 신기능들을 구경하다가 재미있어 보이는 Header을 발견했다
https://en.cppreference.com/w/cpp/header/flat_map
이것이 무엇인지 검색하던 중 관련해서 재미있어 보이는 글을 StackOverflow에서 찾을 수 있었다
https://stackoverflow.com/questions/21166675/boostflat-map-and-its-performance-compared-to-map-and-unordered-map
글 자체가 흥미롭기도 하고 좀 오래되기도 해서 제 나름대로 해석해서 벤치마크를 돌려봤다
글에서는 STL 말고도 다양한 라이브러리의 Container을 사용하여 측정하였는데, 귀찮은 관계로 STL container만 측정했다
Cache Flush
우선 내가 테스트하고 싶은 상황은 다음과 같았다
- insertion과 search가 빈번하게 일어난다
- insertion과 search의 시점은 정해져있지 않다
- insertion의 index는 정해져 있지 않다
- iteration을 사용한다
- iteration은 전체 범위를 가정하고 수행된다
- 다양한 Data type에 대응해야 한다
- 다양한 size에 대응해야 한다
- Pointer type에 대응해야 한다
위 상황을 정확하게 테스트하기 위해서 Cache를 고려해야 함을 깨달았다
그래서 또 뒤적이다가 clflush 함수를 사용하여 매 측정 이전에 cache pipe-line을 flush 하였다
기본적으로 Container에 대한 모든 원소를 flush 하기 위해 모든 element에 접근, flush 하는 방식을 취했다
template <
typename _Iterator
>
inline void
__clflush_iter(const _Iterator &begin,
const _Iterator &end) {
_Iterator iter = begin;
while(iter != end) {
_Iterator next = std::next(iter);
__clflush_(*iter);
iter = next;
}
}Vector의 경우, 각 원소마다 접근하여 flush하는 것이 비효율적일 수 있어 시작지점과 크기값을 통해 flush하는 방식을 취했다
다만, Data type이 포인터인 경우에는, 매 원소마다 flush 한 후, vector 자체에 대한 flush를 다시 수행하였다
template <
typename _DataType
>
inline void
__clflush_range(const _DataType &begin,
const std::size_t &count) {
static constexpr int __l_size = 64;
const char* __ptr = (const char*)&begin;
uintptr_t __last = (uintptr_t)&begin + (sizeof(_DataType) * count) - 1;
__last = __last | (__l_size - 1);
do {
_mm_clflush(__ptr);
__ptr += __l_size;
}
while (__ptr <= (const char*)__last);
}기본적으로 접근가능한 주소는 모두 flush하였지만, 일부는 flush하지 못하였다.
(예시로 std::unordered_map의 bucket 단위는 flush하지 못했다)
insertion과 search에 대해서는 임의의 순간을 가정하였기에 매번 flush 하였다
iteration의 경우 전체 순회를 가정하였기에 시작하기 직전에 한번 flush 하였다
추가적으로 Cache가 재대로 flush되었는지 확인하기 위해, 1~3번 연속 실행한 결과를 비교하였다
예측 가능성을 완전히 배재하기 위해 50개의 원소중 무작위 5개를 찾는 과정을 진행하였다
이때, 무작위 원소는 랜덤하게 주어지기에 완전히 동일한 조건에서 진행되지는 않았다
Cache Flush Validation
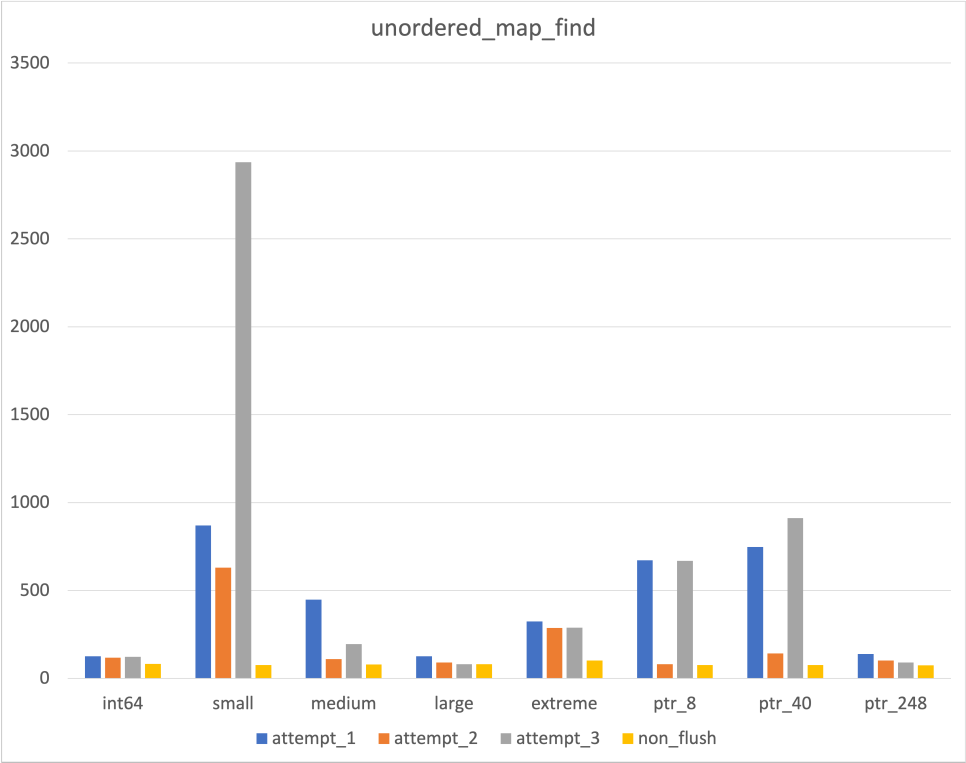 |  |  |
|---|
Map과 Vector의 경우 Cache line이 재대로 flush됨을 확인할 수 있었다
Unordered map의 경우 일부 경우에서 flush 하지 않은 결과하고 비슷하거나 같게 나옴에 따라 의문이 들었다
Unordered map의 경우 시간복잡도가 O(1)이기에 Cache가 flush되었다고 하더라도 비교적 영향을 덜 받긴 한다
(차이가 많이 나는 부분은 Hash 충돌로 인하여 실행시간이 증가한 것으로 추정)
사실 위에서도 언급하였듯이 Unordered map에서 Bucket이 들어있는 Table이나 Bucket은 접근이 불가하였다
Hash 충돌이 발생하지 않고, 위 항목들에서 Cache miss가 발생하지 않는다면 Flush한 의미가 없어지긴 한다..
이 부분은 일단 뒤로 미루고 진행하였다
Time Measurement
시간 측정에 있어서 처음에는 Chrono 라이브러리를 사용할 생각이었으나, RDTSC로 바꿔서 측정하였다
RDTSC는 Clock Cycle 단위로 측정하기에, 가변 Clock에 영향 받지 않고 측정할 수 있다
다만, RDTSC의 경우 몇가지 문제점이 존재하였는데 해결 방법을 모르겠어 일단은 배제한채 진행하였다..
(위 스오플 글에서도 이 부분을 지적하며 intel의 benchmark guide를 제공하였는데, 뭔 소린지 모르겠다..)
duration function(_ContainerType &container,
const std::vector<std::size_t> &order)
{
duration dur(0);
for (int i = 0; i < order.size(); i++) {
clflush_container<_DataType, _Container>(container); // container cache flush
volatile time_point start_time = __rdtsc(); // measure start time
__inner_function<_DataType, _Container>(container, ...); // single run
volatile time_point end_time = __rdtsc(); // measure end time
dur += end_time - start_time; // measure time difference
}
VALIDATE("insert", container.size()) // validate the benchmark, make compiler not to skip the loop
return dur;
}RDTSC로 변경하면서 프로그램의 실행 순서가 뒤바뀌지는 않았을까 혹여나 의심이되었다
따라서 assembly로 compile한 결과를 확인해 보았다
(코드 및 전체 assembly가 궁금하면 아래 링크로 들어가면 된다)
https://godbolt.org/z/b19TET8Gn
.LBB1_6: # in Loop: Header=BB1_1 Depth=1
clflush byte ptr [rsp]
rdtsc
shl rdx, 32
or rdx, rax
mov qword ptr [rsp + 32], rdx
mov r14, qword ptr [rsp + 8]
cmp r14, qword ptr [rsp + 16]
je .LBB1_11
mov dword ptr [r14], r13d
add r14, 4
mov qword ptr [rsp + 8], r14
.LBB1_23: # in Loop: Header=BB1_1 Depth=1
rdtsc
...
.LBB1_11: # in Loop: Header=BB1_1 Depth=1
mov rbx, qword ptr [rsp]
sub r14, rbx
...
lea rdi, [4*rbp]
call operator new(unsigned long)@PLT
mov r15, rax
mov dword ptr [r15 + 4*r12], r13d
test r14, r14
jle .LBB1_20
.LBB1_19: # in Loop: Header=BB1_1 Depth=1
mov rdi, r15
mov rsi, rbx
mov rdx, r14
call memmove@PLT
.LBB1_20: # in Loop: Header=BB1_1 Depth=1
lea r14, [r15 + 4*r12]
add r14, 4
test rbx, rbx
je .LBB1_22
mov rdi, rbx
call operator delete(void*)@PLT
.LBB1_22: # in Loop: Header=BB1_1 Depth=1
mov qword ptr [rsp], r15
mov qword ptr [rsp + 8], r14
lea rax, [r15 + 4*rbp]
mov qword ptr [rsp + 16], rax
jmp .LBB1_23Full optimization으로 compile된 결과라 이걸 일일히 해석하고 있는 것은 너무 시간 낭비 같아, 중요 포인트만 짚어봤다
전체 코드에서 operator new와 memmove는 딱 한 번씩만 호출된다
그리고 그 호출은 vector의 push_back에서 일어난다
따라서 .LBB1_11에서 .LBB1_22까지가 vector의 push_back 과정임을 유추해볼 수 있다
위 관점에서 바라본다면, clflush가 완료되자마자 rdtsc instruction으로 현재 Clock cycle을 받아온다
이후 vector의 push_back이 수행되고(inline되어) .LBB1_23으로 다시 돌아와 rdtsc instruction을 수행한다
따라서 프로그램이 의도한 대로 실행된다고 판단하였다
Container
Container의 경우 3가지 Container 상황에서 test 하였다
Vector 또한 insert로 비교를 해보고 싶었지만, 너무 오래걸리는 것을 보고 push_back과 비교하였다
(Function에서 std가 붙어있지 않은 경우 member function을 의미한다)
| insertion | find | iteration | |
|---|---|---|---|
| std::vector | push_back | std::find_if | std::for_each |
| std::map | insert | find | std::for_each |
| std::unordered_map | insert | find | std::for_each |
Data Type
측정에 사용된 Data type은 다음과 같다
이때 Size가 data의 총합보다 더 크게 나오는데, 그 이유는 compiler optimization으로 추정되었다
(std::string의 최소크기가 24byte인 것으로 추정, std::bitset의 경우 1byte씩 할당 받은 것으로 추정)
| Size(byte) | Content(length) | |
|---|---|---|
| int64 | 8 | std::size_t |
| small | 40 | std::size_t std::size_t std::string(5) |
| medium | 88 | std::size_t std::size_t std::string(6) std::string(6) std::string(6) |
| large | 152 | std::size_t std::size_t std::string(6) std::string(6) std::string(6) std::array<double, 8> |
| extreme | 248 | std::size_t std::size_t std::string(6) std::string(6) std::string(6) std::array<double, 8> std::array<long, 4> std::bitset<3> std::array<double, 7> |
| int64* | 8 | int64 |
| small* | 8 | small |
| extreme* | 8 | extreme |
Result
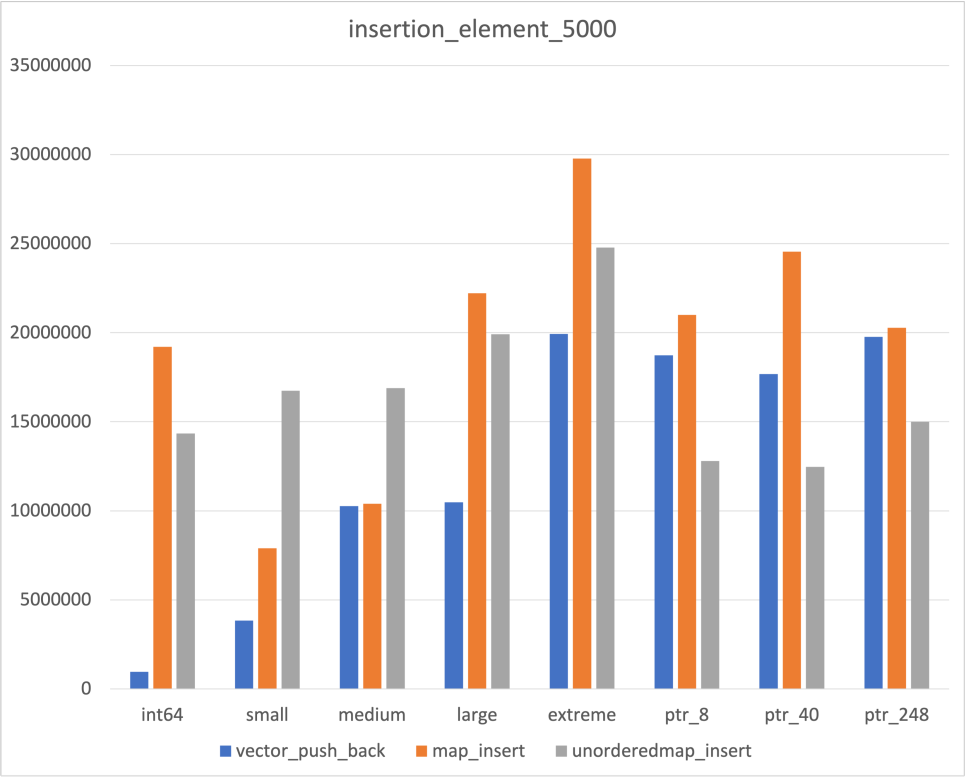
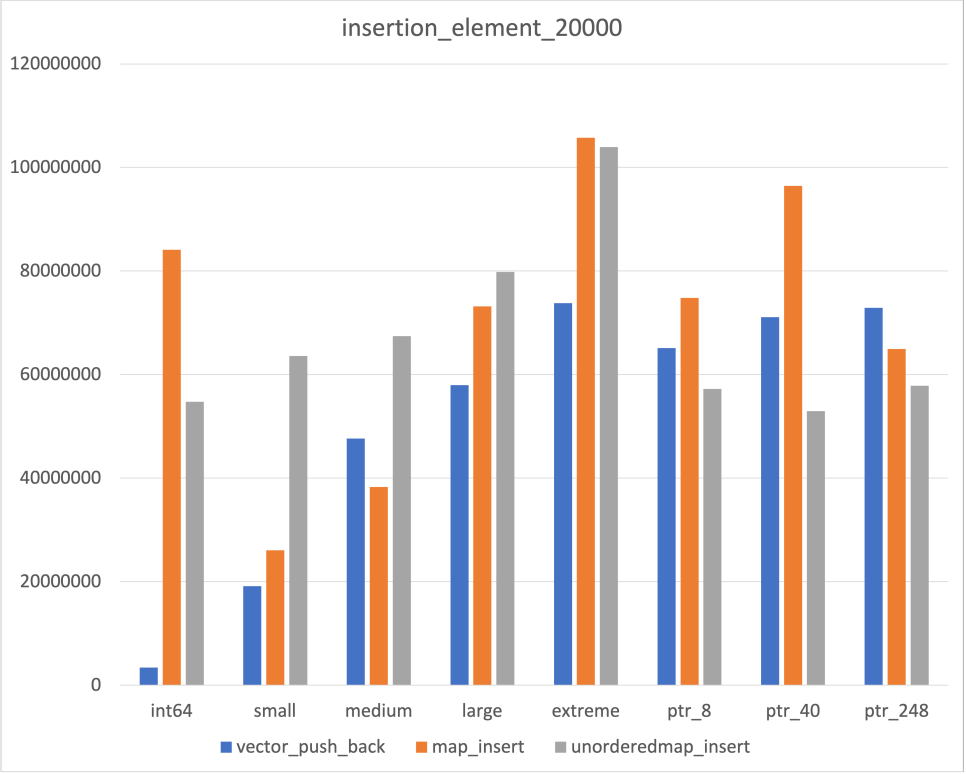
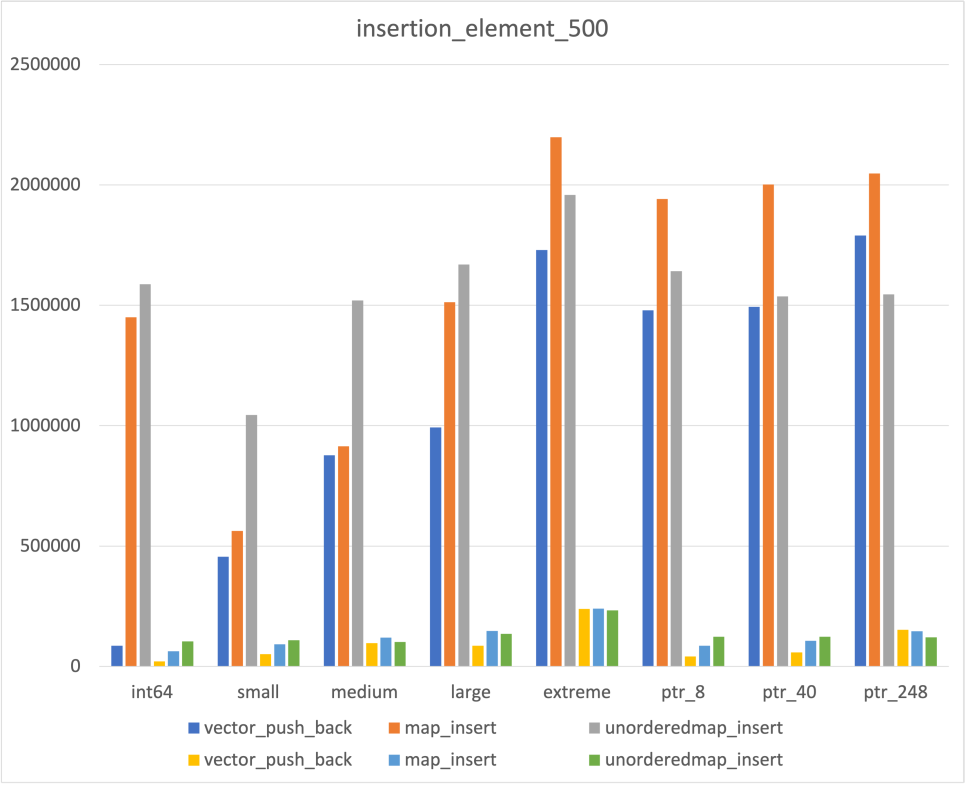
Insertion
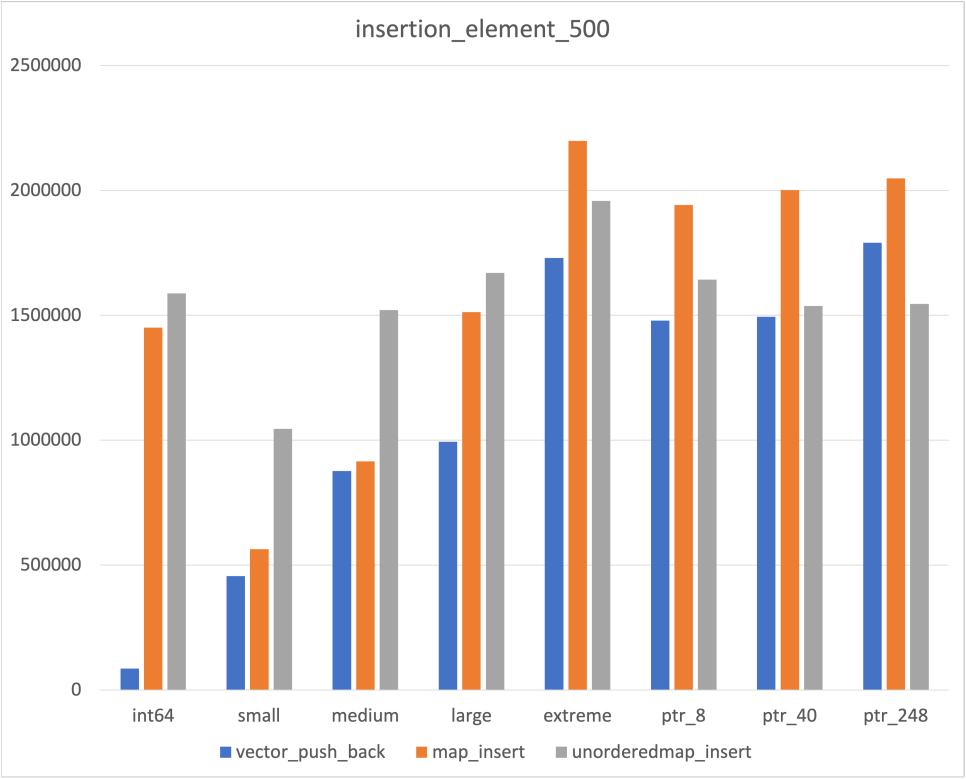 |  |  |
|---|
우선 Insert의 경우 어느 정도 예상되는 결과가 도출되었다
- Data size에 비례해서 시간이 증가하는 Vector
- Data size에 상관없이 비교적 일정한 Unordered map
다만 map의 경우 예상과 다른 부분들이 몇가지 존재하였다
- Data size에 비례해서 시간이 증가하기는 하나, Int64에서만 유독 약한 모습
- Pointer Type의 경우 두번 allocation 되는 것임에도 불구하고, 일반 type보다 빠른 결과
위 두가지는 좀더 공부해야 이해가 될 것 같다..
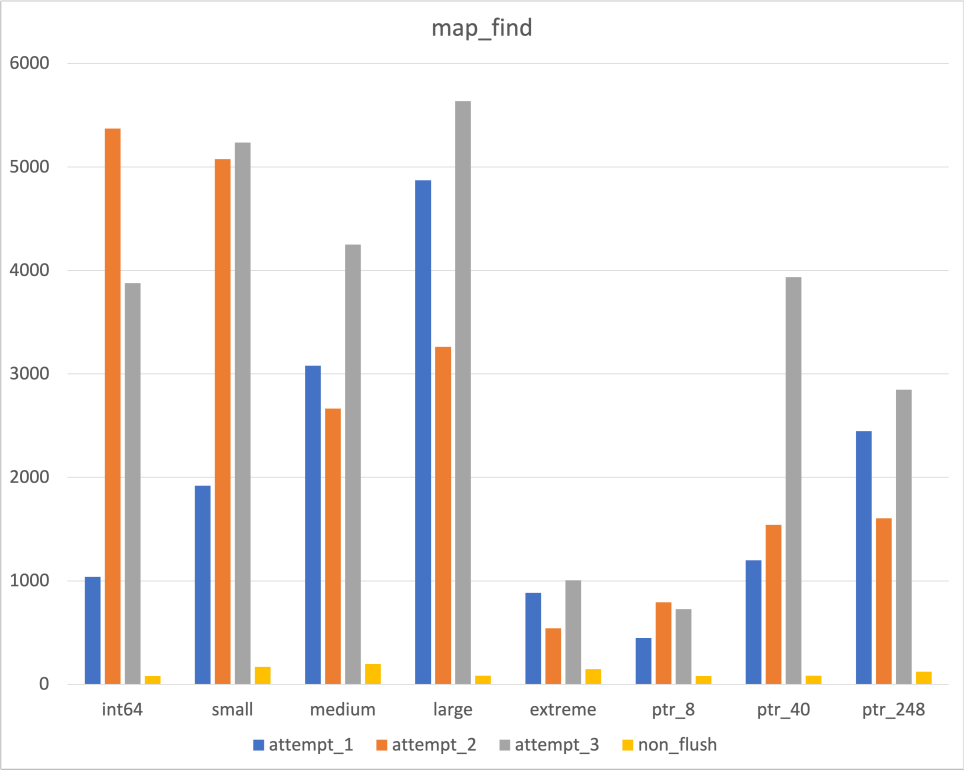
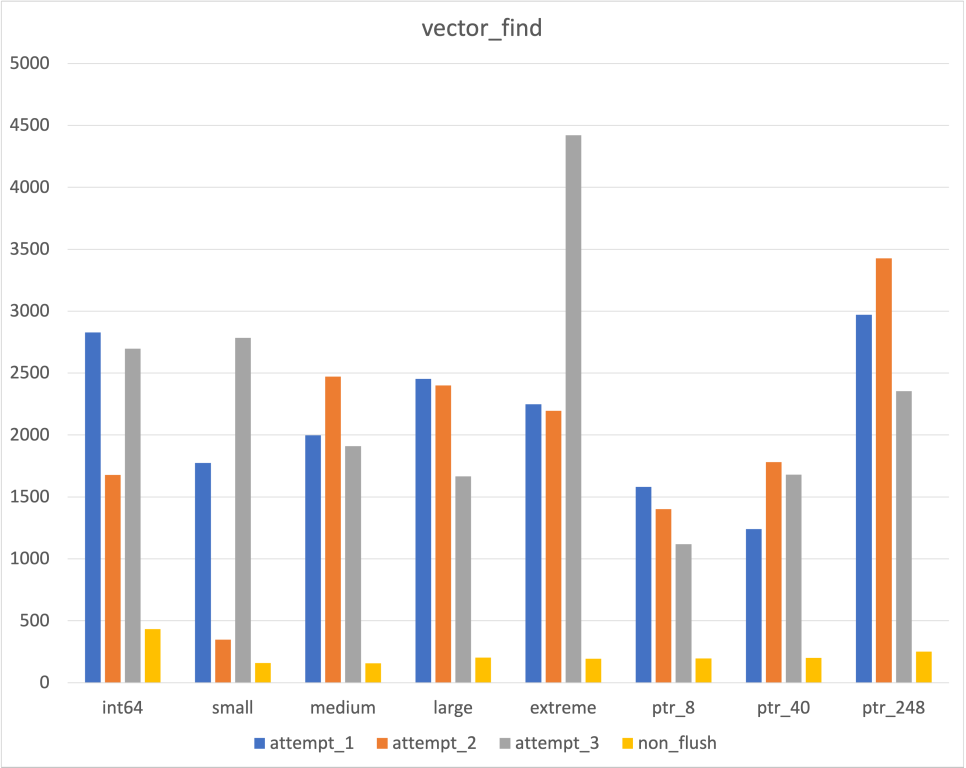
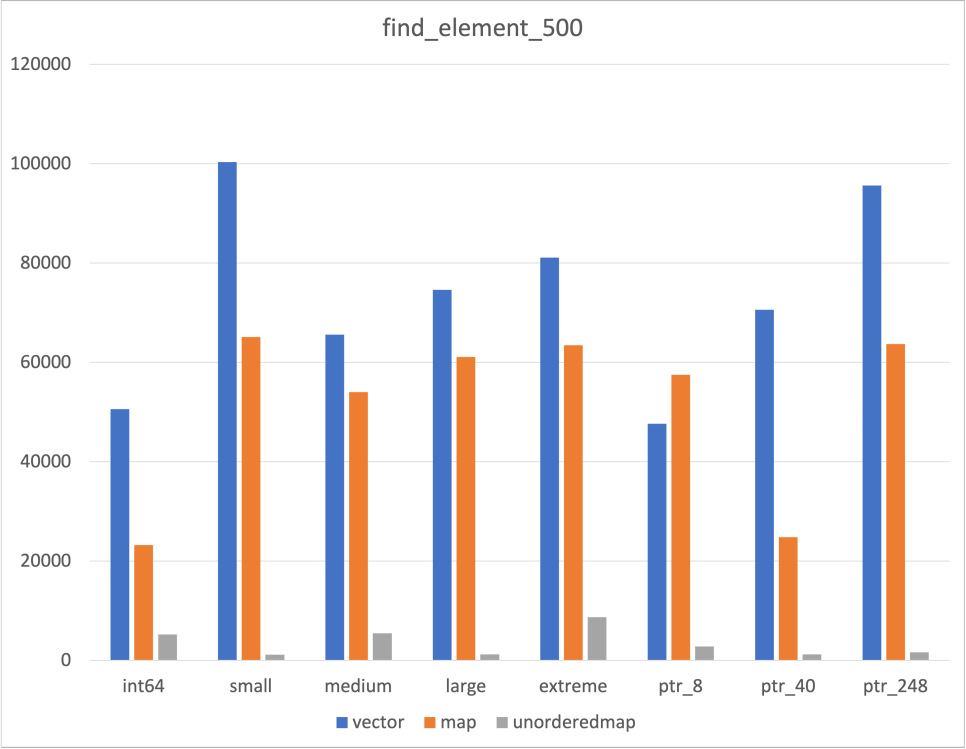
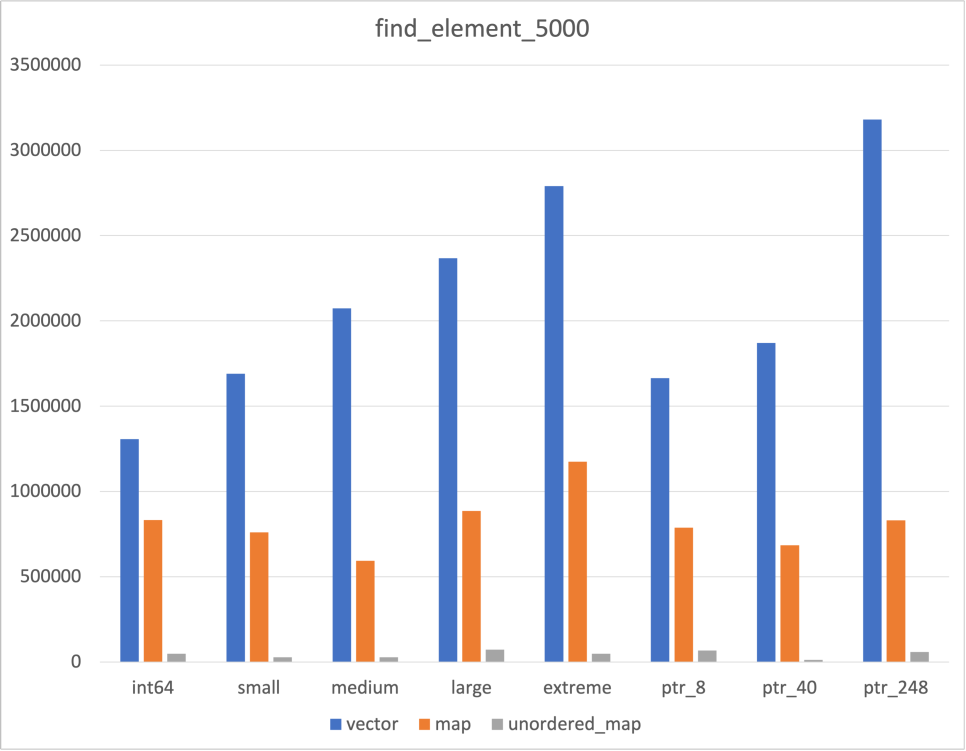
Search
 |  | 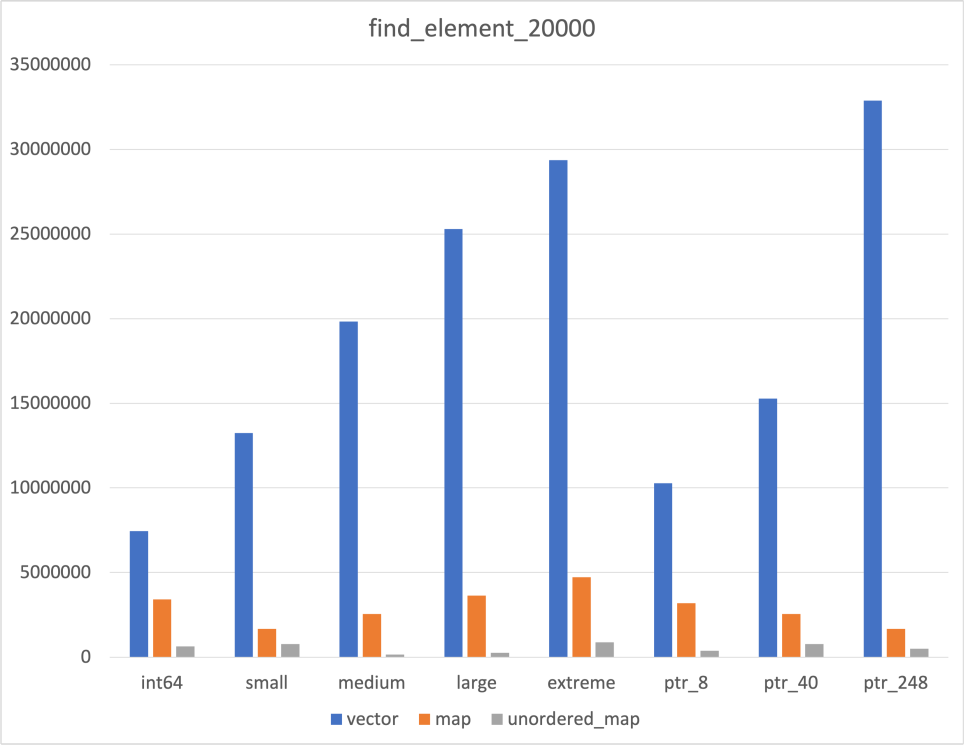 |
|---|
위에서 언급하였듯, Unordered map의 Cache flush 여부와 관련하여 이 데이터를 믿어야할지 말아야할지를 고민되었다
후술할 flush하지 않은 결과와 비교해보았고, 어느 정도는 믿을만한 데이터라고 생각하였다
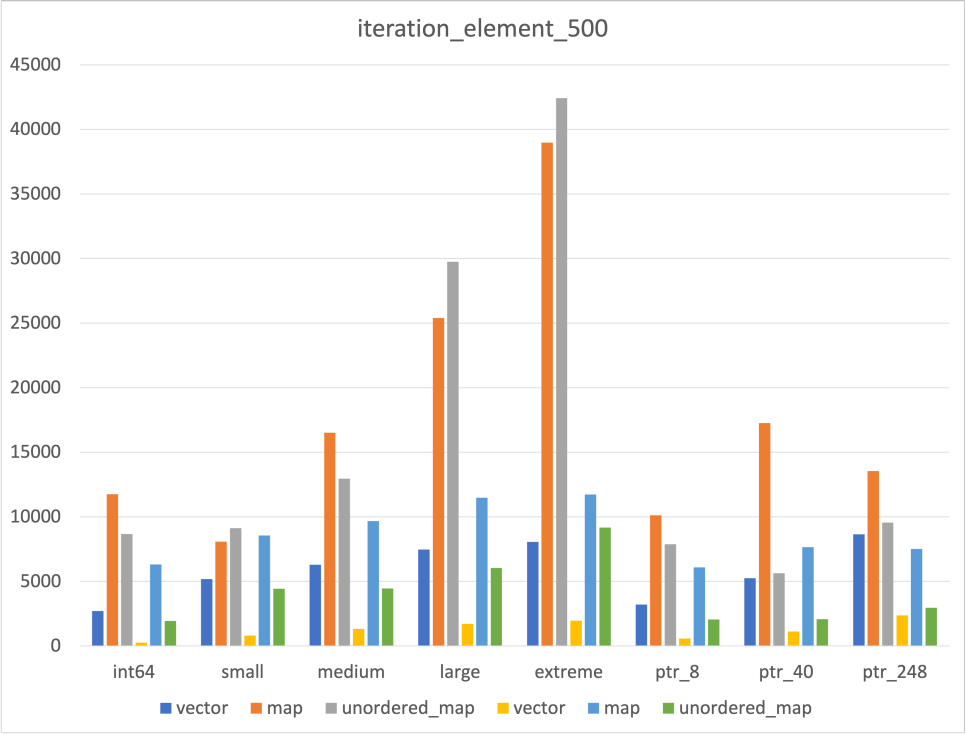
Iteration
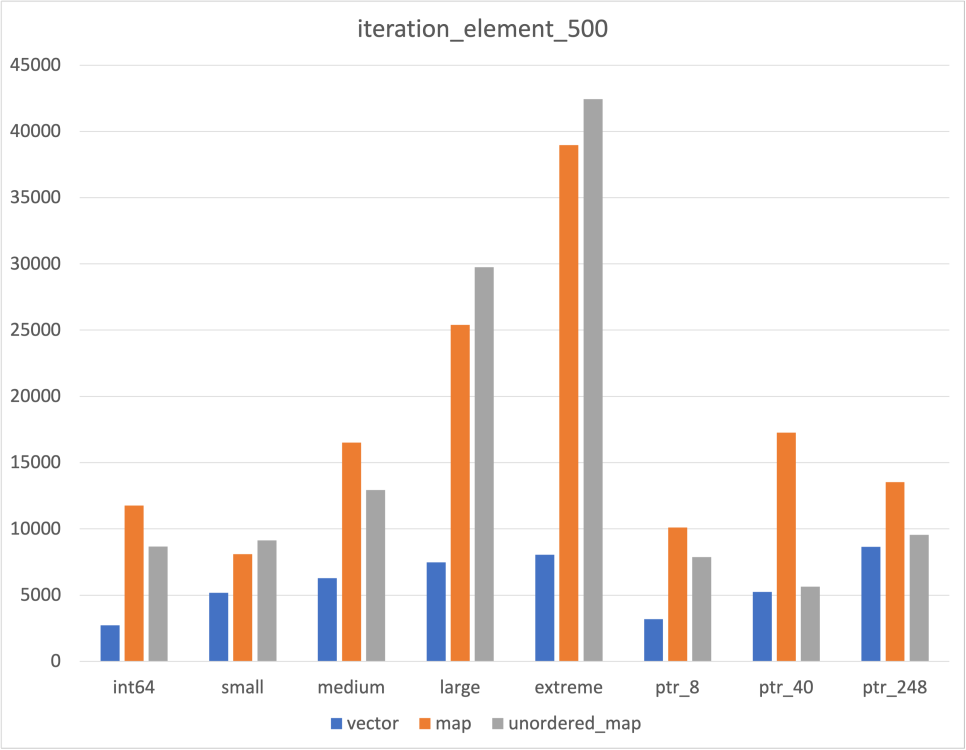 | 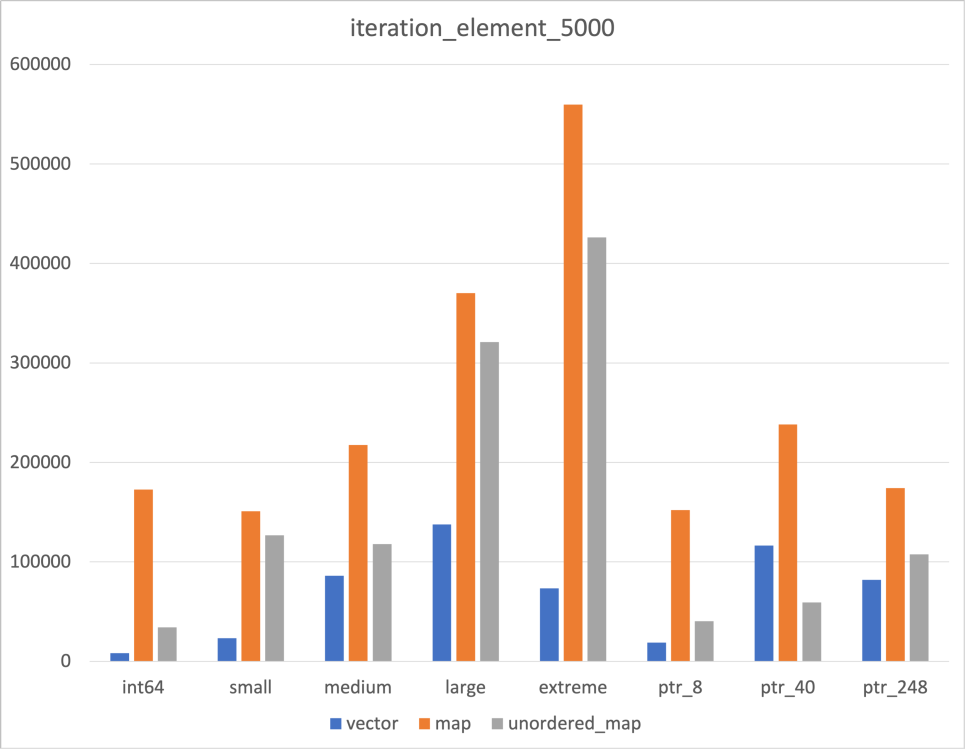 | 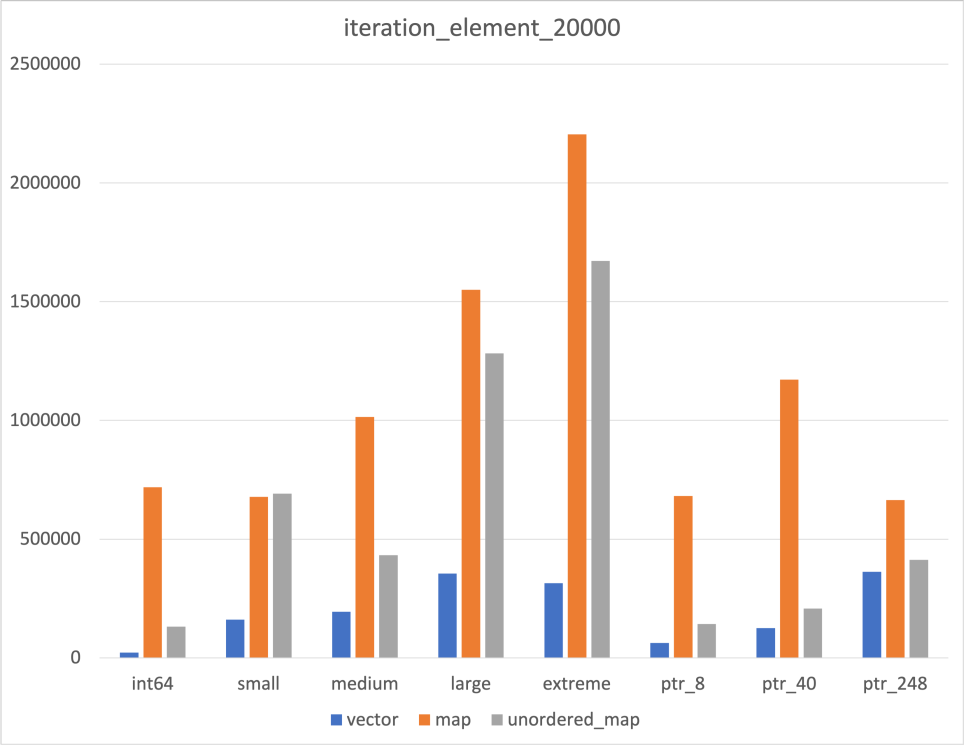 |
|---|
한가지 의외였던 점은 Unordered map의 iteration 속도 였다
Hash Table로 구현되었다는 것만 알고 그 속이 어떻게 생겼는지 정확하게 알지 못해 map보다 빠르지 않을까 싶었다
그 갯수가 많아지자 map보다 빨라지긴 했지만, 갯수가 충분하지 않은 경우에는 map보다 느린 것을 확인할 수 있었다
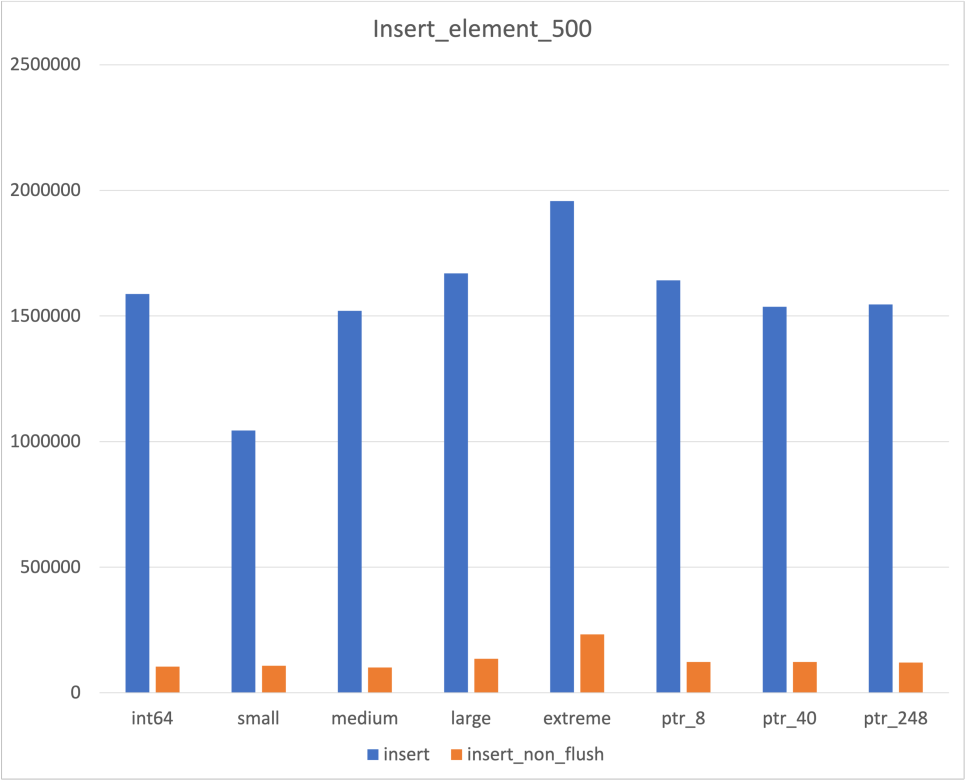
Non Flush
Flush하지 않은 결과도 뽑아보았다
 |  |  |
|---|
Conclusion
Container는 각자 특화된 기능이 있기에, 이렇게 결과를 뽑아놓고도 뭐가 좋다라고 이야기하기는 힘들다
다만 pointer type을 반드시 사용해야하는 경우, Unordered map이 대체적으로 좋다라고 말할수 있을듯하다
또한 Data type이 일정 크기 이상(위 데이터에서는 128byte 정도)이 되면 Pointer로 저장하는 편이 더 효율적으로 보였다
Cache Flush를 수행하지 않은 데이터는 사실 Cache miss가 날 확률이 굉장히 적다
Test에 사용된 CPU의 총 Cache가 16mb인데 비해, 데이터는 가장 큰 경우에도 총합이 약 120kb이기 때문이다
따라서 해당 데이터는 '위 결과에 Cache가 영향을 안 미쳤다' 정도로 해석하기 위한 용도로 측정해보았다
가장 불안했던 Unordered map의 측정 결과만 따로 분리하면 다음과 같다
 | 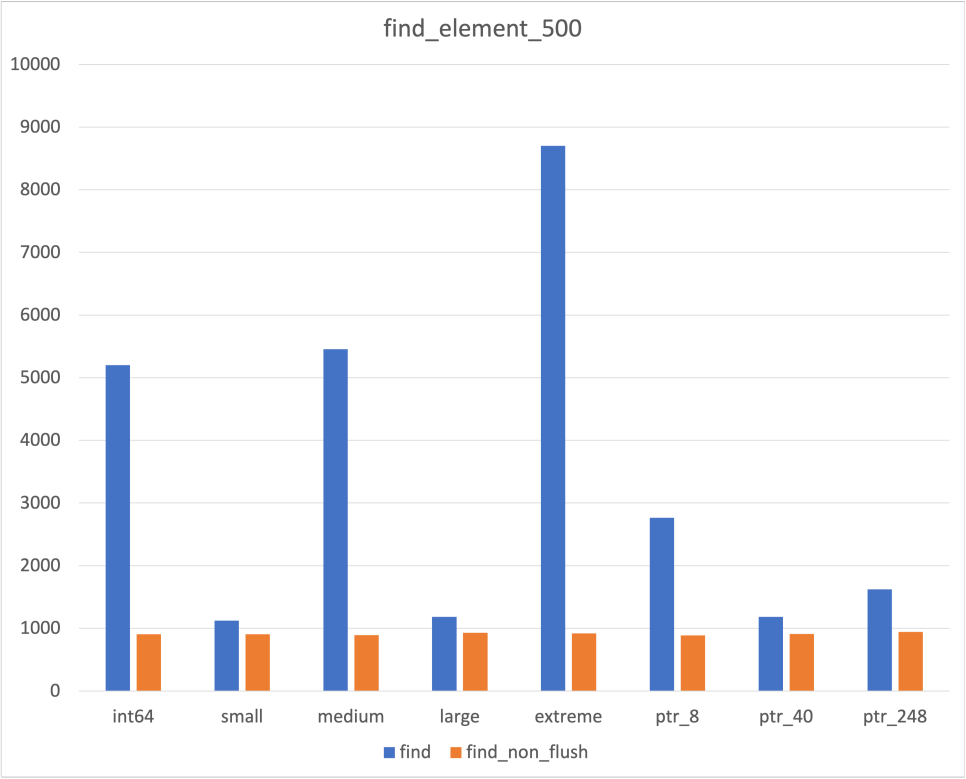 | 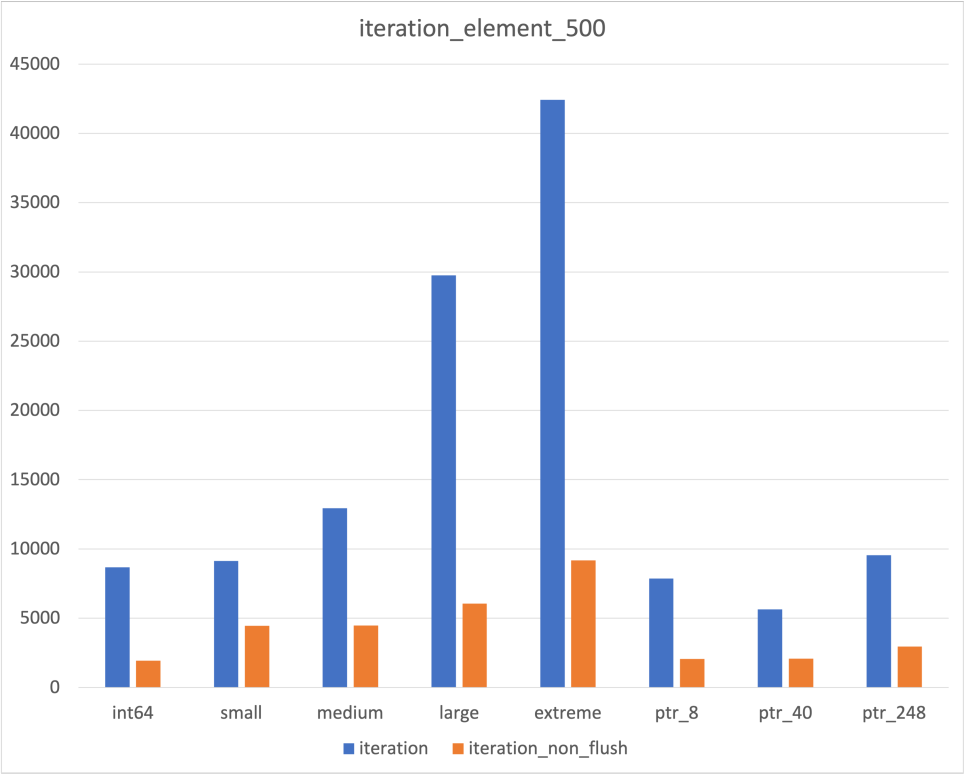 |
|---|
우선 insertion과 iteration 부분에서는 압도적인 차이를 보였다
Find의 경우 압도적인 차이를 보이기도 하였지만, 그렇지 못한 경우도 존재하였다
다만 한가지 다행이었던 점은, Hash Collision이 발생하지 않은 것처럼 보이는 경우에도 차이가 존재하였다는 것이다
이것이 Cache flush가 벤치마크에 영향을 미칠만큼은 되었다고 판단한 이유이기도 하다
여담
최근 게임 개발쪽을 공부하면서 생긴 다양한 궁금증 중 하나가 이것이었다
따라서 게임에서 빈번하게 사용되는 insertion, iteration과 더불어 pointer type을 측정하게 되었다
(Pointer type의 경우, 여러가지 type을 하나의 Container에 저장하기 위해 upcasting이 필수적으로 요구되기 때문)
한가지 재미있었던 점은, Warm cache 상태에서 성능 향상폭이 굉장히 컸다는 것이다
최근 AMD의 경우 3D cache 기술로 Cache 용량을 대폭 증가시켰고, 성능 또한 대폭 증가되었다
즉, 현대 CPU에서 Cache는 굉장히 중요한 역할을 하고 있다는 의미이기도 하다
이러한 역할을 말로만 듣다가 간접적으로나마 체험할 수 있지 않았나 싶다
https://www.youtube.com/watch?v=fHNmRkzxHWs
위 자료를 최초로 시도했을 당시에는 더 많은 Container, 그리고 더 많은 경우의 수를 고려했었다
하지만, 다양한 이유로 쳐내다보니 현재의 결과만 남게 되었다
추후에 시간이 된다면 STL 뿐만 아니라 다른 라이브러리의 Container들도 테스트해보고 추가해보고 싶다
(무엇보다 STL에 flat_map이 추가된다면 바로 돌려볼 생각이다)
벤치마킹이라는 것이 처음 스오플 글에서도 말하였듯이, 굉장히 변수가 많다
나도 내가 좋은 벤치마크를 수행했다고 생각하지는 않는다
상당히 많은 부분에서 변수를 통제하지 못하였고, 결과값을 믿을 수 있는가에 자신있게 대답하지 못하기 때문이다
다만, 일주일 가량 찾아보고 노력함으로써 제가 할 수 있는 선에서 대부분의 변수를 통제하였다고 생각한다
따라서 위 데이터를 완벽하게 믿고 사용하지는 못하더라도 추후에 참고정도는 해보려고 한다
또한 벤치마크용 코드를 한번 생성해보았으니, 추후에 언젠가 또 쓸일이 있지 않을까 싶다
위 벤치마크에 사용된 코드는 아래 Github에서 확인할 수 있다
https://github.com/ross1573/stl_container_compare
