1. 성능 데이터 모델링
1) 정의
- DB 성능 향상을 목적으로 설계단계의 데이터 모델링 때부터 성능과 관련된 사항이 데이터 모델링에 반영될 수 있도록 하는 것.
2) 수행절차
- 정확한 정규화 수행
- DB 용량 산정
- DB에서 발생되는 트랜잭션 유형 파악
- 용량과 트랜잭션 유형에 따라 반정규화 수행
- 이력모델, PK/FK, 슈퍼/서브타입 조정 수행
- 성능관점에서 데이터 모델 검증
2. 정규화 (Normalization)
1) 정의
- 데이터 분해, 중복 제거 과정
- 독립성 확보, 변화에 따른 대응력(유연성) 향상
- 입출력 데이터 양 줄여서 성능 향상시킴
2) 절차
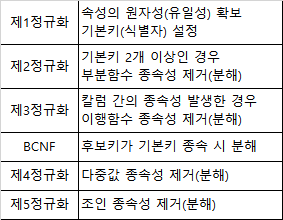
3) 문제점
- 데이터 조회 시 조인, 중첩루프(Nested Loop) 유발 (CPU, 메모리 많이 사용)
해결 > 인덱스, 옵티마이저, 반정규화 실행
3. 반정규화 (De-Normalization)
1) 정의
- 데이터 중복 허용 (조인 줄여 성능 향상시킴)
- 조회 속도 향상 (but, 모델의 유연성 낮아짐)
2) 문제점
- 한 행의 크기가 블록의 크기(입출력 단위)를 넘어가면,
디스크 입출력 증가하고 성능이 저하됨
3) 기법
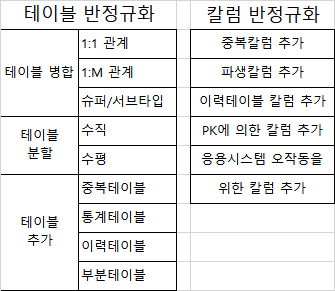
4. 분산 데이터베이스
1) 정의
- 물리적으로 떨어진 DB에 네트워크로 연결 (단일DB)
- 분산된 작업 처리 수행
- 시스템의 네트워크 분산 여부 인식 X
- 자신만의 DB 사용하는 것처럼 사용 가능
** 중앙 집중형 DB : 물리적 시스템(1개)-사용자(여러명)
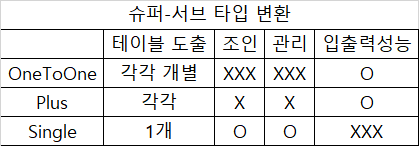
2) 투명성 종류

3) 설계방식
- 상향식 : 지역 > 전역
- 하향식 : 전역 > 지역 사상
4) 장점
- DB의 신뢰성, 가용성이 높다
- 병렬처리 수행 (빠른 응답)
- 시스템 용량 확장 쉬움
5) 단점
- 보안/무결성 관리, 통제 어려움 (네트워크로 분리되어 있음)
- 설계가 복잡함
rose