
EDA 정리
1. PANDAS
1) 데이터 읽기
- pandas import
import pandas as pd
- csv 파일 읽어오기, 불러오기
CCTV_Seoul = pd.read_csv("경로/파일이름.csv", encoding= utf-8)
- excel 파일 읽어오기, 불러오기
pop_Seoul = pd.read_excel("경로/파일이름.xls", header=2, usecols = "B,D,G,J,N")
header=2 : 액셀파일의 최상위2열 제외 후 불러오기
usecols = "B,D,G,J,N" : 액셀파일의 B,D,G,J,N 행을 컬럼으로 사용
- 컬럼명 재설정
CCTV_Seoul.rename(
columns = {"현재 컬럼명" : "바꿀 컬럼명"},
inplace =True #바뀐 내용 본문에 적용
)
- 최상위 5개 데이터 읽어오기
CCTV_Seoul.head()
- 최하위 5개 데이터 읽어오기
CCTV_Seoul.tail()- 인덱스의 마지막 번호를 알 수 있다.
- 데이터의 총 개수도 알 수 있다.
- 날짜 찍어내기("년월일",periode = 날짜일수)
dates = pd.date_range("20230714", periods = 6)
2) 데이터 프레임
- 데이터프레임 만들기
df = pd.DataFrame(사용할 값, index=사용할 인덱스, columns=[컬럼1, 컬럼2,...])- 사용할 값의 행은 컬럼의 수와 같아야 한다.
- 사용할 값의 열은 index와 같아야 한다.
2-1) 정렬
- 데이터 프레임 정렬
df.sort_values(by="B", ascending=True, inplace=True)
by=정렬 할 기준 컬럼
ascending = True : 오름차순, False : 내림차순
inplace=True : 본문에 적용
2-2) 데이터 선택
- df["A"]
A컬럼 데이터
- df["A","B"]
A,B컬럼 데이터
- df[0:3]
인덱스 0~2까지 데이터
- df["230710" : "230714"]
인덱스 230710~ 230714까지 데이터- 문자열로 슬라이싱 할 경우 끝번호 까지
loc : 데이터 선택
df.loc(index, columns)
- loc("230710":"230715", ["A","B"])
인덱스 230710~230715, 컬럼 A,B 데이터
iloc : 컴퓨터가 인식하는 인덱스번호로 데이터 선택
df.iloc(index, columns)
- df.iloc = [1:3,2:4]
열 인덱스 번호 1~2까지 행 인덱스 번호 2~3까지 데이터
- df.iloc = [[1,2,4],[0,2]]
열 인덱스 번호 1,2,4 번 행 인덱스 번호 0,2번
condition : 조건에 맞는 데이터 선택
- df["A">0]
컬럼 A에서 0보다 큰 데이터 추출
- df[df["A">0]]
컬럼 A에서 0보다 큰 데이터들을 데이터프레임형식으로 출력
2-3) 컬럼 추가
- 기존 컬럼이 있다면 수정
- 기존 컬럼이 없다면 추가
- df["E"] = ["1","2","3","4","5","6"]
E컬럼 추가 값은 1,2,3,4,5,6- 값의 수는 열의 수와 일치시키기
isin() : 특정 요소가 있는지 확인 , bool형식으로 출력
- df["E"].isin(["2","5","3"])
2-4) 컬럼 삭제
- del
- drop
- del df["E"]
E컬럼 삭제
- df.drop(["D"], axis = 1)
D컬럼 수직데이터(axis = 1) 지우기- df.drop(["D"], axis = 0)
D컬럼 수평데이터(axis = 0) 지우기
세로 = 1 ,수평 = 0(디폴트 값)
3) 두 데이터 병합하기
- pd.concat()
- pd.merge()
3-1)merge()
- 두 데이터 프레임에서 컬럼이나 인덱스를 기준으로 잡고 병합하는 방법
- 기준이 되는 컬럼이나 인덱스를 "키"값 이라고 합니다.
- 기준이 되는 키값은 두 데이터 프렘임에 모두 포함되어 있어야 한다.
- left DataFrame만들기
#딕셔너리 안의 리스트 형태 #열로 값이 들어감 left = pd.DataFrame( { "key" : ["K0","K4","K2","K3"], "A" : ["A0","A1","A2","A3"], "B" : ["B0","B1","B2","B3"] } ) left
- right DataFrame만들기
#리스트 안의 딕셔너리 형태 #행으로 값이 들어감 right = pd.DataFrame( [ {"key":"K0", "C":"C0", "D":"D0"}, {"key":"K1", "C":"C1", "D":"D1"}, {"key":"K2", "C":"C2", "D":"D2"}, {"key":"K3", "C":"C3", "D":"D3"}, ] ) right
- pd.merge(DF1,DF2, how="", on="")
DF1과 DF2를 합칠건데
how="inner" 공통된 데이터만 출력
how ="outer" 모든 데이터 출력
on = "기준 삼을 컬럼 or 인덱스"
4) 그 외
- 선텍 컬럼 인덱스로 지정하기
set_index("컬럼명")
- 중복되지 않고 한번 나온 데이터 출력
pop_seoul["구별"].unique()
- 상관계수
corr()
df.corr() : df의 컬럼들 사이의 상관계수를 계산해줌- 상관계수가 0.2이상 일 때 유의미한 관계가 있다 본다.
2. Matplotlib
모듈 import
import matplotlib.pyplot as plt
from matplotlib import rc
#한글 꺠짐 방지
rc("font", family="Malgun Gothic")
#마이너스 기호 깨짐 방지
rc("axes",unicode_minus=False)
#주피터 노트북 안에 그래프를 그리겠다.
# %matplotlib inline
get_ipython().run_line_magic("matplotlib", "inline")사인 그래프 그리기
import numpy as np
t = np.arange(0,12, 0.01)
y = np.sin(t)
def drawGraph():
plt.figure(figsize=(10,6))
plt.plot(t, np.sin(t), label="sin")
plt.plot(t, np.cos(t), label="cos")#그래프를 그릴 때 이곳에서 label=" "해주면 legend는 호출만 하면 된다.
plt.grid(True)#격자
plt.legend(loc = "lower right") #범례, 표시되는 위치설정도 가능하다.
plt.title("Example of sinewave")#제목
plt.xlabel("time")#x제목
plt.ylabel("Amplitude")#진폭 y제목
plt.show() #그린 그래프 보여주기
점 그래프 그리기
t= np.arange(0,5,0.5)
plt.figure(figsize=(10,6))
plt.plot(t,t, "r--") #빨간 점선
plt.plot(t,t**2,"bs")# 파란 네모(Blue Square)
plt.plot(t,t**3,"g^")# ^방향으로 된 초록 삼각형
plt.show()
그래프 그리기
#t=[0,1,2,3,4,5,6]
t=list(range(0,7))
y= [1,4,5,8,9,5,3]
def drawGraph():
plt.figure(figsize=(10,6))
plt.plot(
t,
y,
color="green",
linestyle="dashed",
marker="o",
markerfacecolor ="blue",
markersize=15,
)
plt.xlim([-0.5,6.5])
plt.ylim([0.5,9.5])
plt.show()
drawGraph()
scatter 그래프 그리기
colormap =t #colormap을 적용할 축 설정
def drawGraph():
plt.figure(figsize=(10,6))
#x축, y축, 찍히는 점의 사이즈(s), colormap적용(c), 마크 모양(marker)
plt.scatter(t,y, s=50, c=colormap, marker=">")
plt.colorbar() #colorbar 표시
plt.show()
drawGraph()
내가 설정한 색상 colormap 적용하고 상위 5개 하위 5개 데이터 text로 그래프에 출력시키기
# 경향과 비교해서 데이터의 오차가 너무 나는 데이터를 계산
df_sort_f = data_result.sort_values(["오차"], ascending=False) #내림차순 ,
df_sort_t = data_result.sort_values(["오차"], ascending=True) #오름차순from matplotlib.colors import ListedColormap
#colormap을 사용자 정의(user drfine)로 세팅
color_step = ["#e74c3c","#2ecc71","#95a9a6","#2ecc71","#3498db","#3498db"]
my_cmap = ListedColormap(color_step)def drawGraph():
plt.figure(figsize=(14,10))
plt.scatter(data_result["인구수"], data_result["소계"], s=50, c=data_result["오차"], cmap=my_cmap)
plt.plot(fx, f1(fx), ls="dashed", lw=3, color="g")
for n in range(5):
#상위 5개
plt.text(
df_sort_f["인구수"][n]*1.02, #x좌표
df_sort_f["소계"][n]*0.98, #y좌표
df_sort_f.index[n], #title
fontsize = 15
)
#하위 5개
plt.text(
df_sort_t["인구수"][n],
df_sort_t["소계"][n],
df_sort_t.index[n],
fontsize=15
)
plt.xlabel("인구수")
plt.ylabel("CCTV")
plt.colorbar()
plt.grid(True)
plt.show()
drawGraph()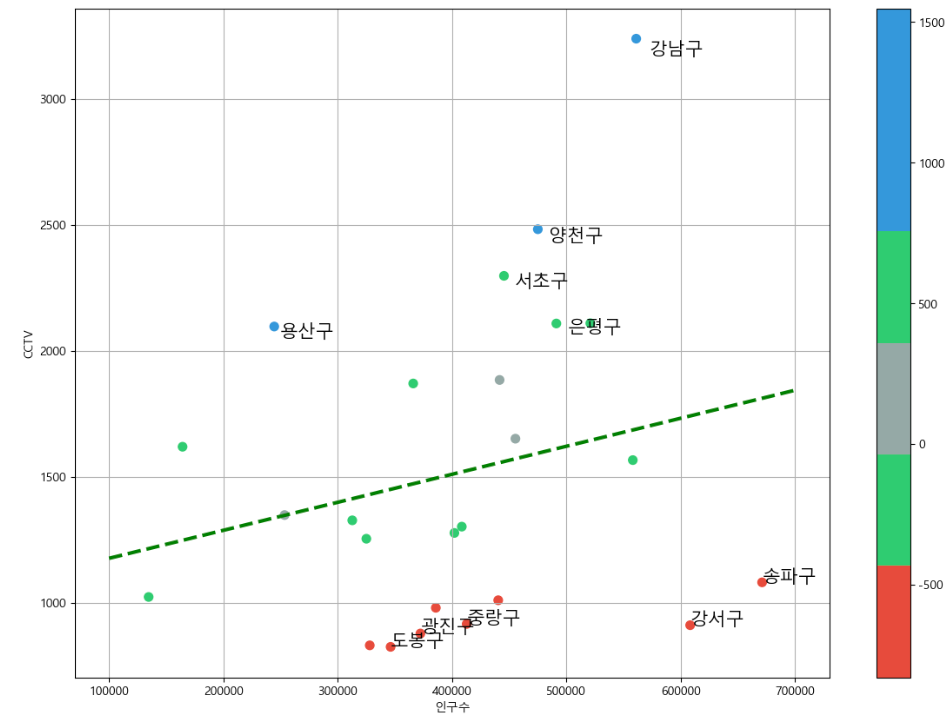

취업공부
저도 개발자인데 같이 교류 많이 해봐요 ㅎㅎ! 서로 화이팅합시다!