
📖 Introduction
내가 아는 MIME 이라고는 인터넷에서 나도는 그 밈밖에 몰랐는데...
최근 우연히 개발 관련 오픈 채팅방에 들어갔는데, 어떤 분께서 HTTP Request Header의 필드인 Content-type 에 대해서 질문을 주셨다. 요지는 application/json 이 뭘 의미하는 거에요? 였는데.. 지금까지 나는 요청을 보낼때 "아, 나 지금 json 파일 보낸거니까 이거 보고 체크해~" 정도로만 알았지 정확히 이 친구가 뭘 의미하는지를 몰랐었다.
따라서 기왕 이렇게 된거 아주 끝을 보자는 마인드로 관련된 자료를 쭉 찾아보았다. 항상 무언가를 탐구하고 이해하는 과정에서 많은 피로감과 어려움을 느끼지만 그래도 이걸 왜 쓰는지를 비로소 알게 되면 눈이 맑게 개이는 느낌이 아주 좋다. 이렇게 말을 하니까 나도 참 정상인은 아닌가보다. 사서 고생한다는 게 딱 이럴때 쓰는 말인가.
✒️ MIME Type
1. MIME (Multipurpose Internet Mail Extensions) 이란?
- 오직 텍스트만 보낼 수 있었던 SMTP의 단점을 보완하여, 메세지 내부에 다른 파일을 전송할 수 있도록 하는 전자메일 프로토콜.
- MIME으로 인코딩한 파일은
Content-type필드를 헤더에 담게 되며, 이를 통해 전송된 자원의 형식을 명시할 수 있다. - 현재는 단순히 전자메일에 국한되지 않고, 웹을 통해 여러 형태의 파일을 전송하는데 두루 쓰임.
2. MIME 을 쓰는 이유는 무엇인가?
- 과거에는 ASCII 문자로 이루어진 파일만을 전송하는 것을 전제로 데이터를 교환하는 시스템이 설계되어짐.
- 하지만 네트워크를 통해 텍스트 파일이 아닌,
바이너리 파일을 전송하는 경우가 잦아짐. - 인터넷을 통해 전송 가능한 문자는 오로지 ASCII 표준이기 때문에, 다른 데이터를 이로 변환하는 과정이 필요해졌음.
- 따라서 바이너리 파일을 텍스트 파일로 변환하는 과정 (인코딩) 과 변환된 텍스트 파일을 다시 바이너리 파일로 되돌리는 과정 (디코딩) 과정이 추가됨.
- 초기에 사용된 인코딩 방식인
UUEncode은 단점이 존재했기에 이를 보강한 방식인MIME이 등장하게 됨. - 게다가
MIME의 경우 전송한 파일의 포맷에 대한 정보도 제공했기에, 더욱 큰 이점이 있다.
2-1. 바이너리 데이터를 왜 인코딩 해야 했을까?
- ASCII 의 경우 제어 문자에
0 ~ 32번을 할당시켰다, 제어 문자의 경우 폰트의 변경이나 전송의 끝을 알리는 문자처럼 특수한 작업을 하기에 중요한 요소이다. - 따라서 ASCII의 영문과 숫자, 그리고 특수 문자는
33번부터 시작하여127번까지의 영역을 사용하였다. - ASCII의 경우 8 bit 가 아닌 7 bit 로도 충분히 모든 문자를 매핑할 수 있었기에 맨 앞의 비트는
0으로 고정됨. - 하지만 바이너리 파일의 경우, 이진수의 첫번째 자리가 0으로 비워지지 않은 8 bit 데이터임.
- 따라서 이들을 기존의
UUEncode방식으로 7 bit의 ASCII 문자 데이터로 바꾸어서 전달해야 했는데, 이 과정에서 문제가 발생함.
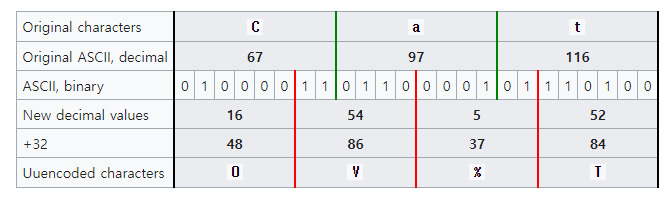
2-2. UUEncode 는 어떤 방식으로 동작할까?
- 바이너리 데이터의 MSB부터
3 Bytes(24 bits) 씩 가져와 이를6 bit로 4분할 한다. - 이후, 가장 앞에
00을 추가하여 각 섹션을 8 bit로 맞춰준다. ASCII 는 MSB가0이기 때문이다. - 마지막으로 각 섹션에
32(100000) 를 더하여 최소 값을 32 이상으로 해 화면에 보이는 문자로만 인코딩되게끔 한다.
2-3. UUEncode는 어떤 점이 문제였을까?
- 인코딩된 데이터를 복호화 하는 과정에서 종종 공백이 발생하는데, 이를 변환하지 않고 무시하는 시스템에서는 문제가 발생.
- base64에서는 이런 문제를 막기 위해 끝을 알리는 특수 문자인
=을 사용. - 더 자세한 조사가 필요해보임. 아직 궁금증이 해결되지 않았다..
✒️ MIME Type & Content-types
1. MIME Type (Media Type) 은 대체 뭘까?
- 인터넷에 전달되는 파일 포맷 및 포맷 컨텐츠를 위한 식별자.
- IANA 에서 이를 표준화하고 출판하는 공식 기관으로서의 역할을 하고 있음.
2. MIME Type (Media Type) 의 구조
- 기본적으로는
type/subtype구조로 이루어져 있다. type은 파일의 종류를 의미하며,subtype은 파일의 포맷을 의미한다.application/json의 경우, 바이너리 파일 (application) 중 json 포맷의 파일을 의미하는 식별자로서 기능한다.- 또한 추가 세부정보를 보내기 위해 파라미터를 사용할 수도 있다.
- 웹이 점차 보편화되면서 MIME type 또한 Media type 이라는 이름으로 확장되었다.
[type]/[subtype];[parameter=value]
text/plain;charset=us-asciitype의 종류
기본적으로 MIME type의 type 은 크게 두 가지 분류로 나뉜다.
discrete(개별) 타입은 IANA에서 지정한 단일 문서의 카테고리다.- text : 텍스트를 포함하는 모든 문서 [plain, html, css, javascript]
- image : 모든 종류의 이미지 파일 [gif, png, jpeg, bmp, webp]
- audio : 모든 종류의 오디오 파일 [midi, webm, ogg, wav]
- video : 모든 종류의 비디오 파일 [webm, ogg]
- model : 3D 오브젝트 관련 모델 데이터 [3mf, vrml]
- font : 모든 종류의 폰트 데이터 [woff, ttf, otf]
- application : 모든 종류의 바이너리 데이터 [pdf, json, octet-stream]
multipart타입은 다른 MIME type을 지닌 메세지들로 이루어진 하나의 복합적인 메세지이다.- form-data
- mixed
- alternative
3. Content-type 이란?
- 웹 서버에서 HTTP 통신을 통해 전달받은 요청의 Header 내에서, 해당 요청의 Body에 든 데이터 타입에 대한 정보를 나타낸다.
- 즉, Request Body에 들어가는 데이터 타입을 HTTP Header가 명시할 수 있는데, 이때 사용하는 필드를
Content-type이라 한다. - MIME 표준 헤더 필드에 담긴
Content-type과의 맥락은 다르지만, 사용 용도는 어느 정도 일맥상통한다.
3-1. MIME type과 Content-type의 다른 점은?
Content-type과MIME type의 목적성은 데이터의 타입을 명시하는 것에 있다.- 하지만
Content-type의 경우 단순히 웹에 국한되어 사용되지만,MIME type의 경우 인터넷 프로토콜에서 사용되므로 더 상위의 개념이다. - 한마디로, HTTP Request의 Header에 있는 Content-type 필드에는 Request Body에 담긴 데이터의 MIME type을 추가한다고 이야기할 수 있다.
3-2. Content-type의 multipart에 대해 알아보자.
- HTTP Request의 Header 필드인
Content-type에multipart타입이 들어왔다면, 이는 Body에 여러 종류의 단일 데이터가 결합된 형태의 데이터가 존재한다는 의미다. - 추가적인 자료 조사가 필요해보인다. 추후 이어서 준비해보자.
✒️ Encoding
1. Encoding 이란?
- 컴퓨터가 이해할 수 있는 형식으로 데이터를 변경해주는 프로세스.
- 내용에는 전혀 변화가 없으며, 디코딩 방식이 정해져 있기에 암호화로는 부적격하다.
-
ASCII Encoding : 영문자 및 일부 특수 문자를 컴퓨터가 해석 가능한 숫자로 변환시킴.
- 7bit를 사용하여 총 128개의 문자로 구성되었음.
-
URL Encoding : ASCII 코드에 없는 언어와 특수문자를 ASCII 코드로 표현하기 위해 사용.
- 기존 문자열의 HEX (16진수) 값 앞에
%를 붙여 사용. (%XX) - URL 내부에
&,=,/특수문자가 들어갈 경우, 이를 그대로 보내면 문자 그대로의 의미가 전달되지 않음. - 이럴 경우, ASCII 코드에 포함된 문자여도 이를 Escape 처리 해주기 위해 인코딩을 진행해야 함.
- 기존 문자열의 HEX (16진수) 값 앞에
-
HTML Encoding : HTML 내에 사용된 문자를 브라우저에서 올바르게 보여주기 위해 사용.
- HTML 문서 내부에는 특수한 기능을 하는 문자들이 포함되어 있음.
- 이를 그대로 사용할 경우 예상치 못한 결과가 나올 수 있기 때문에, 이를 방지하기 위해 인코딩을 해야 함.
- 예를 들어
<와>특수 기호를 HTML 내에 그대로 삽입할 경우, HTML은 이를 태그 로 인식. - HTML Encoding의 경우, 코드의 앞에 보통
%#문자가 붙는다. - XSS 보안 문제를 해결할 수 있다.
- HTML 내의 일부 특수문자는 아래와 같은 값을 가짐.
공백: <:<>:>&:&':'":"
-
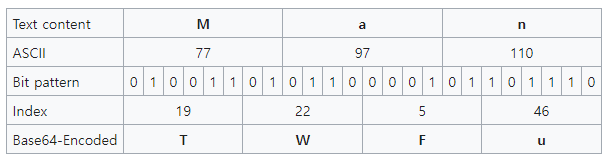
base64 Encoding : 바이너리 데이터를 문자 코드에 영향을 받지 않는 (안전한) 공통 ASCII 영역의 문자로 변환시키는 방식.
- MIME 에서 사용하는 바이너리 데이터 인코딩 방식.
- base64는 64진법이며, 이는 ASCII 문자들을 표현할 수 있는 가장 큰 진법임.
- 기본적으로 알파벳과 숫자만을 사용하고, 나머지 2개의 기호는
+,/를 쓴다.- ASCII 코드의 문자 중 일부는 하드웨어나 OS에 따라 인코딩 형태가 달라질 수 있다.
- 하지만 base64에서 사용하는 문자들 (
A-Z,a-z,0-9,+,/) 의 경우 항상 같은 인코딩을 보장한다.
=특수 기호의 경우 끝을 알리는 코드로 쓰인다.- 24Bit Buffer에 MSB부터 1 Byte 씩 총 3 Byte를 넣는다.
- 이후 Buffer의 위쪽부터 6 bit 단위로 잘라 값을 읽은 후, 사전에 정렬시킨 64개의 문자 중에서 매칭되는 것을 고른다.
- 만약 3 Byte가 다 들어오지 않았다면, 빈 Byte 만큼
=으로 패딩된다.
📖 References

항상 왜 이걸 써야하는지가 궁금한 사람