1. 카프카란
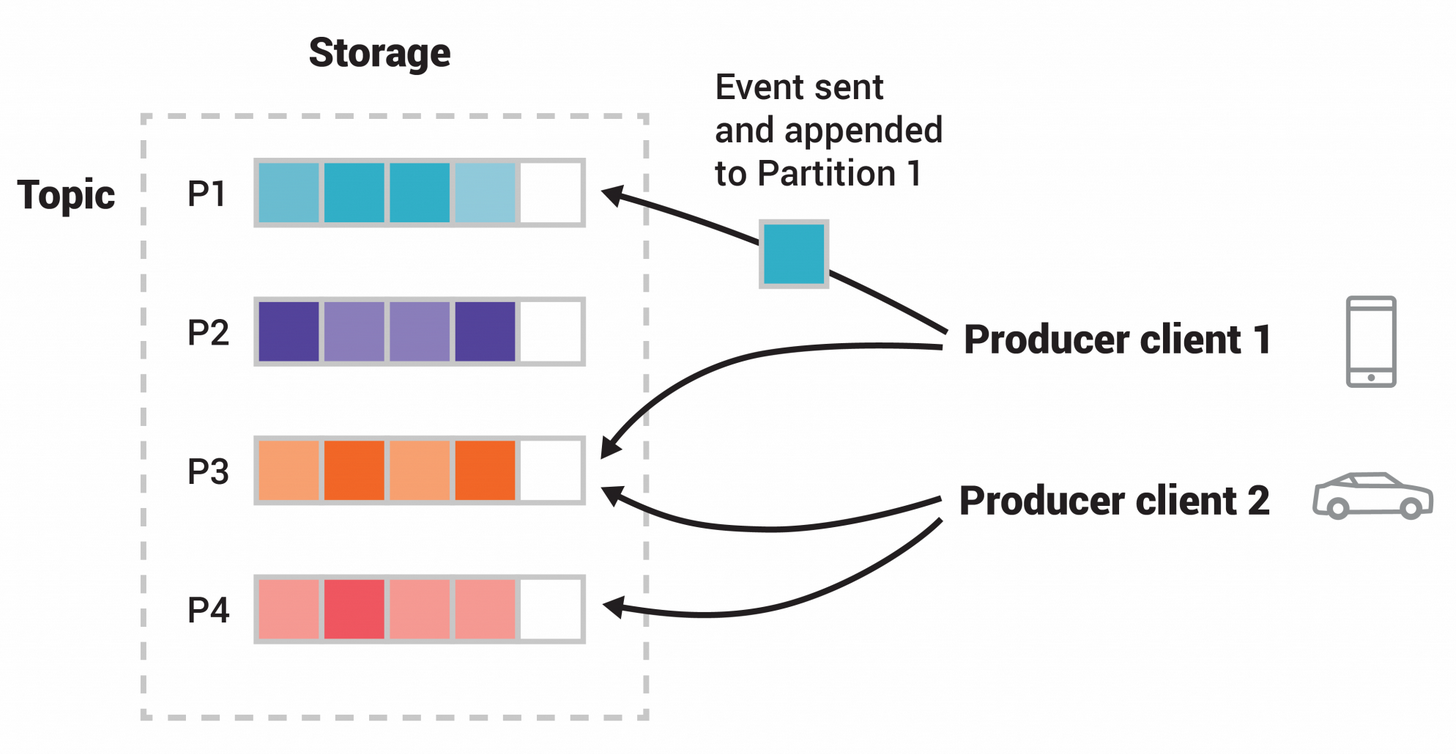
카프카는 실시간, 이벤트 기반 애플리케이션 개발을 가능하게 하는 오픈 소스 분산 스트리밍 플랫폼입니다. 그렇다면 이것이 무엇을 의미할까요?
오늘 날 수 많은 데이터 소스가 지속적으로 데이터 레코드 스트림을 생성하며 이에는 이벤트 스트림도 포함됩니다. 이벤트는 발생한 행동과 그 시간을 기록한 디지털 레코드입니다. 일반적 으로 이벤트는 프로세스의 일부로 다른 액션을 유발하는 액션입니다. 고객이 주문을 하는 것, 비행기 좌석을 선택하는 것, 등록 양식을 제출하는 것 모두 이벤트의 예입니다. 이벤트에는 반 드시 사람이 관련될 필요는 없습니다. 에어컨이 특정 시간의 온도를 보고하는 것도 이벤트입니다.
이러한 스트림들은 실시간으로 데이터나 이벤트에 반응하는 애플리케이션에 기회를 제공합니다. 스트리밍 플랫폼을 통해 개발자들은 이러한 스트림들을 지속적으로 소비하고 극도로 빠른 속도로, 발생 순서에 기반한 높은 수준의 정확성과 정밀성으로 처리하는 애플리케이션을 구축할 수 있습니다.
개념적으로 이벤트에는 키, 값, 타임스탬프, 선택적 메타데이터 헤더가 있습니다. 다음은 이벤트의 예시입니다.
이벤트 키: "OSYRYW"
이벤트 값: "OSYRYW 배송이 취소됨"
이벤트 타임스탬프: "2023년 11월 28일 오후 2시 6분"퍼블리셔는 카프카에 이벤트를 게시(쓰기)하는 클라이언트 애플리케이션이고, 컨슈머는 이러한 이벤트를 구독(읽기 및 처리)하는 애플리케이션입니다. 카프카에서 프로듀서와 컨슈머는 완전히 분리되어 서로에 대해 독립적으로 구현이 됩니다. 이는 카프카가 자랑하는 높은 확장성을 달성하기 위한 핵심적인 설계 요소입니다. 생산자는 소비자를 기다릴 필요가 없습니다. 카 프카는 이벤트를 한 번에 정확하게 처리할 수 있는 기능 등 다양한 보장 기능을 제공합니다.
이벤트는 토픽으로 정리되어 영구적으로 저장됩니다. 토픽은 파일 시스템의 폴더와 비슷하며 이벤트는 해당 폴더에 있는 파일들입니다. 예를 들어 토픽 이름은 "배송"이 될 수 있습니다. 토 픽은 항상 여러개의 퍼블리셔 및 여러개의 퍼블리셔로 구성이 됩니다. 토픽에는 이벤트를 작성하는 생산자가 0명, 1명 또는 다수일 수 있으며, 이러한 이벤트를 구독하는 소비자도 0명, 1명 또는 다수일 수 있습니다. 토픽의 이벤트는 필요한 만큼 자주 읽을 수 있으며, 기존 메시징 시스템과 달리 이벤트는 소비 후 삭제되지 않습니다. 대신, 토픽별 구성 설정을 통해 Kafka가 이벤 트를 얼마나 오래 보관할지 정의할 수 있으며, 그 이후에는 오래된 이벤트가 삭제됩니다. Kafka의 성능은 데이터 크기와 관련하여 사실상 일정하므로 데이터를 장기간 저장해도 문제가 없 습니다.
토픽은 분할되어 있어 하나의 토픽이 서로 다른 Kafka 브로커에 있는 여러 개의 "버킷"에 분산되어 있습니다. 이렇게 데이터를 분산 배치하면 클라이언트 애플리케이션이 동시에 여러 브로 커에서 데이터를 읽고 쓸 수 있기 때문에 확장성에 매우 중요합니다. 새 이벤트가 토픽에 게시되면 실제로는 토픽의 파티션 중 하나에 추가됩니다. 동일한 이벤트 키(예: 고객 또는 차량 ID) 를 가진 이벤트는 동일한 파티션에 기록되며, 카프카는 특정 토픽 파티션의 모든 소비자가 항상 해당 파티션의 이벤트를 기록된 순서와 정확히 동일한 순서로 읽을 수 있도록 보장합니다.
2. 왜 카프카를 선택했는가?
1. 전사 공용 카프카
전사 공용 카프카의 존재로 카프카를 유지 보수하고 관리하는 리소스가 별도로 필요하지 않았습니다.
2. 실시간 데이터 처리
이번에 연동하게 되는 연동사는 지속적으로 주문 목록을 풀링하며 옵저빙을 하다 새로운 주문 혹은 주문의 변경사항이 생기면 이를 버티컬쪽으로 전파해야 되는 요구사항이 있었습니다.
이때 비동기적으로 분산 처리를 통해 작업을 진행하면 좋겠어서 프로도와의 이야기를 통해 카프카를 적용하기로 하였습니다.
3. 내결함성 및 신뢰성
카프카는 높은 내결함성을 제공합니다. 데이터 복제를 통해 하나의 노드에 장애가 발생해도 데이터 손실 없이 운영을 지속할 수 있습니다. 메시지들은 구성된 기간 동안 Kafka 서버에 안정적으로 저장되어, 시스템 장애 시에도 데이터를 보호합니다.
3. GOA에서의 카프카 적용
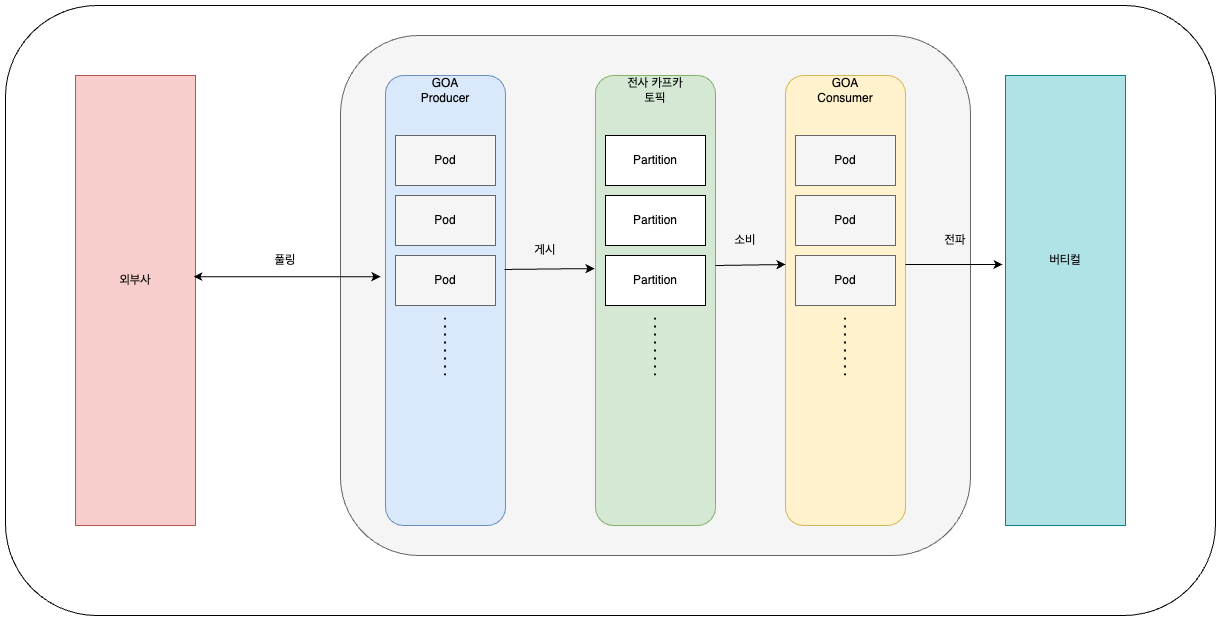
우선 아키텍처에는 크게 네 부분이 있습니다.
외부시스템, 카프카 프로듀서, 카프카 클러스터, 카프카 컨슈머.
1. 외부 시스템:
- 데이터의 원천입니다.
1. 카프카 배치 프로듀서:
- 카프카 프로듀서는 배치를 통해 지속적인 풀링을 하다 외부 시스템에서 발생한 데이터를 카프카 클러스터로 전송하는 역할을 합니다.
- 각 Pod는 독립적으로 작동하며, 분산 시스템에서 발생하는 데이터를 카프카 토픽의 적절한 파티션에 효율적으로 배분합니다.
3. 카프카 클러스터:
- 카프카 클러스터는 메시지를 내구적으로 저장하는 여러 카프카 브로커들로 구성됩니다.
- 각 브로커는 하나 이상의 파티션을 관리하며, 이 파티션들은 토픽을 논리적으로 구분합니다.
- 파티션은 데이터의 병렬 처리를 가능하게 하며, 카프카의 확장성과 내결함성을 높여줍니다.
- 클러스터는 토픽에 대한 메시지를 저장하고, 컨슈머가 필요로 하는 데이터를 제공합니다.
3. 카프카 컨슈머:
- 카프카 컨슈머 Pod는 카프카 클러스터에서 데이터를 구독하고 처리합니다.
- 컨슈머도 마찬가지로 Pod 형태로 구성되어 확장성 및 탄력성을 갖추고 있습니다.
- 데이터가 처리되면 이 결과를 버티컬을 향해 전파(생성,수정) 합니다.
위 아키텍처의 카프카 적용은 다음과 같은 장점을 제공합니다.
- 확장성: Kafka는 수평적 확장이 가능하여, 데이터의 처리량이 증가해도 시스템을 쉽게 확장할 수 있습니다.
- 내결함성: 데이터는 복제된 파티션에 저장되어, 단일 점의 장애에도 데이터 손실 없이 시스템이 계속 작동할 수 있습니다.
- 리얼타임 처리: Kafka는 실시간으로 대량의 데이터를 처리할 수 있어, 지연 시간이 짧은 애플리케이션에 적합합니다.
- 유연한 데이터 흐름: 프로듀서와 컨슈머 사이의 분리는 시스템의 유연성을 증가시키며, 데이터 흐름을 효율적으로 관리할 수 있습니다.
- 리얼타임 처리: Kafka는 실시간으로 대량의 데이터를 처리할 수 있어, 지연 시간이 짧은 애플리케이션에 적합합니다.
- 내결함성: 데이터는 복제된 파티션에 저장되어, 단일 점의 장애에도 데이터 손실 없이 시스템이 계속 작동할 수 있습니다.
4. 프로듀서와 컨슈머의 주요 개념
1. 컨슈머
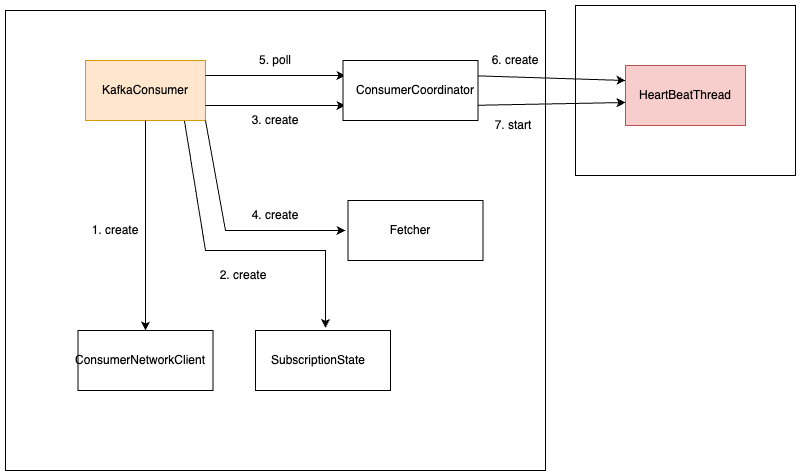
Fetcher와 HeartBeatThread
Kafka에서 데이터를 효율적으로 처리하기 위해서는 Fetcher와 HeartBeatThread가 제일 중요합니다. Fetcher의 역할
Fetcher는 이름에서 알 수 있듯이 Kafka 토픽에 저장된 데이터를 가져오는 역할을 합니다. 이 과정에서 데이터의 크기와 레코드의 개수는 크게 두 가지 설정 옵션에 의해 결정됩니다: fetc h.min.bytes와 max.partition.fetch.bytes입니다. fetch.min.bytes는 최소한 가져올 데이터의 크기를 정의하며, max.partition.fetch.bytes는 파티션에서 한 번에 가져올 수 있는 최대 데이터 크기를 정의합니다.
그러나 데이터의 크기와 더불어 중요한 것은 가져오는 레코드의 개수입니다. max.poll.records 설정은 한 번의 poll 요청으로 가져올 수 있는 레코드의 최대 개수를 정합니다. 기본값은 500개이지만, 이 값을 조절함으로써 데이터 프로세싱의 효율성을 높일 수 있습니다.
max.poll.records 설정
이 설정은 Consumer의 polling 간격에 직접적인 영향을 주며, 데이터 처리 지연은 Consumer가 클러스터에서 제외될 수 있는 max.poll.interval.ms 설정에 영향을 미칩니다. HeartBeatThread의 중요성은?
이전 Kafka 버전에서는 데이터 프로세싱 중에만 Consumer의 생존을 확인할 수 있었기 때문에, 데이터 프로세싱에 오랜 시간이 걸릴 경우 Consumer의 생존 여부를 즉각적으로 확인하 기 어려웠습니다.
이 문제를 해결하기 위해 도입된 것이 바로 HeartBeatThread입니다. 이 별도의 스레드는 Kafka 클러스터에 Consumer가 여전히 활동 중임을 주기적으로 알려주며, 데이터 프로세싱 과는 독립적으로 작동합니다. 이를 통해 max.poll.interval.ms 설정과 관계없이 Consumer의 생존 여부를 확인할 수 있으며, Kafka 클러스터의 Consumer Group 관리에 큰 도움을 줍니다.
2. 프로듀서
Apache Kafka의 Producer는 메시지의 효율적인 전송을 위해 네 가지 주요 전략을 구사합니다.
첫째, 직렬화(Serializer)를 통해 데이터를 Kafka가 이해할 수 있는 형식으로 변환합니다.
둘째, 데이터 압축(Compression)을 사용하여 네트워크 대역폭과 스토리지를 절약합니다.
셋째, 파티션 할당(Partitioning)을 통해 메시지가 적절한 목적지에 도달하도록 합니다.
마지막으로, 재시도 정책(Retry Policy)을 설정하여 메시지 전송 실패 시 자동으로 재전송되도록 하여 데이터 유실을 방지하고 전송의 신뢰성을 높입니다.
이 전략들은 Kafka를 사용하는 생산자가 데이터를 안정적이고 효과적으로 처리할 수 있는 기반을 마련해 줍니다.
5. 적용 시 주의점과 해결방법
1. 프로듀서 설정
먼저 주문 상태 변경 콜백에 카프카를 적용하였는데 카프카 장애로 인해 프로듀싱이 실패 했을 경우 Spring kafka에서 지원하는 콜백을 받아 기존에 존재하던 Feign Client로 보내도록 처리를 해두었습니다.
future.addCallback(object : ListenableFutureCallback<SendResult<String, Request>> {
override fun onSuccess(result: SendResult<String, Request>?) {
logger.info("Sent message=[$request] with offset=[${result?.recordMetadata?.offset()}]") }
override fun onFailure(ex: Throwable) {
logger.error("Unable to send message=[$request] due to : ${ex.message}") baeminClient.orderStatusUpdate(agencyCode, request.orderNo, request) }
})2. 컨슈머 설정
1. max.poll.records 설정
Fetcher의 역할
Fetcher는 이름에서 알 수 있듯이 Kafka 토픽에 저장된 데이터를 가져오는 역할을 합니다. 이 과정에서 데이터의 크기와 레코드의 개수는 크게 두 가지 설정 옵션에 의해 결정됩니다: fetc h.min.bytes와 max.partition.fetch.bytes입니다. fetch.min.bytes는 최소한 가져올 데이터의 크기를 정의하며, max.partition.fetch.bytes는 파티션에서 한 번에 가져올 수 있는 최대 데이터 크기를 정의합니다.
그러나 데이터의 크기와 더불어 중요한 것은 가져오는 레코드의 개수입니다. max.poll.records 설정은 한 번의 poll 요청으로 가져올 수 있는 레코드의 최대 개수를 정합니다. 기본값은 500개이지만, 이 값을 조절함으로써 데이터 프로세싱의 효율성을 높일 수 있습니다.
max.poll.records 설정
이 설정은 Consumer의 polling 간격에 직접적인 영향을 주며, 데이터 처리 지연은 Consumer가 클러스터에서 제외될 수 있는 max.poll.interval.ms 설정에 영향을미칩니다.
2. RetryTemplate 설정
한 메세지에대해 컨슘에 대한 재시도를 설정하고자 할때는 retryTemplate를 별도로 작성해서 kafkaListenerContainerFactory 작성시에 설정을 해주어야 합니다. GOA 컨슈머는 현재 아래와 같이 설정이 되어있습니다.
` `private fun retryTemplate(): RetryTemplate { val retryTemplate = RetryTemplate()
` `// 재시도시 30초 후에 재시도 하도록 backoff delay 시간을 설정 val fixedBackOffPolicy = FixedBackOffPolicy()
` `fixedBackOffPolicy.backOffPeriod = 30000L
` `retryTemplate.setBackOffPolicy(fixedBackOffPolicy)
` `// 최대 재시도 횟수 설정
` `val retryPolicy = SimpleRetryPolicy()
` `retryPolicy.maxAttempts = 3
` `retryTemplate.setRetryPolicy(retryPolicy) return retryTemplate
` `}또한 카프카의 recoveryCallback을 설정할 수 있는데, recoveryCallback의 경우 모든 재시도가 실패했을 경우 최후의 수단으로 실행되는 콜백 로직입니다. GOA 컨슈머는 리트라이 가 최종적으로 실패했을 경우 슬랙으로 알람을 보내고 dead letter topic에 별도로 저장하여 나중에 확인할 수 있도록 설정을 해두었습니다.
` `fun recoveryCallback(kafkaTemplate: KafkaTemplate<String, String>): RecoveryCallback<Any> { return RecoveryCallback { context -> // 여기에 재시도 후에도 실패한 경우의 로직을 작성
val lastThrowable = context.lastThrowable
logger.error("Message processing failed after max attempts. Error: " + lastThrowable.message)
val retryCount = context.retryCount
val acknowledgment =
context.getAttribute("acknowledgment") as Acknowledgment?
val record = context.getAttribute("record") as ConsumerRecord<\*, \*>? val topic = "dlt-" + record!!.topic()
val value = record.value().toString()
val type = "CallBack"
val currentTime = ZonedDateTime.now().toString()
val messageContent = "[Failed to send callback] $topic - retryCount: $retryCount - value: $value"
val message = """
` `<!here>
\* [${environment.activeProfiles}] Failed to send callback.\*
` `type: $type
` `when: $currentTime
` `content: $messageContent
` `""".trimIndent()
` `runCatching {
` `// slack에 알람
` `notificationUseCase.notify(message)
` `// Dead Letter Topic에 메시지를 전송
` `kafkaTemplate.send(topic, value)
` `}.onFailure { e ->
` `logger.error("Failed to send notification", e) }.also {
` `acknowledgment?.acknowledge()
` `}
` `null
` `}
` `}3. 컨슘 도중 배포 이슈
위에 정의해둔 RecoveryCallback을 통해 알파에서 슬랙에 간헐적으로 실패 알람이 올라왔는데 키바나의 로그를 보면 공통점이 메시지가 컨슘 도중에 실패 알람이 울렸습니다. 확인해보 니 잦은 알파의 배포로 인해 컨슈머가 graceful하게 종료되지 못했습니다. 공식문서를 확인해보니 Kafka 리스너 컨테이너가 정상적으로 종료되기를 기다리는 최대 시간(밀리초 단위)인 shutdownTimeout 설정할수 있었습니다. 컨테이너를 종료할 때 Kafka 리스너가 현재 처리 중인 작업을 완료하고 리소스를 정리하는 데 걸리는 시간을 지정합니다.
따라서 shutdownTimeout의 값을 최대 15초로 조정함으로써 해결되었습니다. shutdownTim
4. 메세지 처리 방식
No gurantee 메세지 전송에 대해 보장하지 않는다. Consumer 는 Producer 가 보낸 메세지가 유실되거나 한번 또는 여러번 동일한 메세지를 처리할 수 있다 At most once 메세지 전송에 대해 최선으로 1번 처리할 것을 보장한다. 단 이때 중복가능성을 피하기 위해 메세지가 전송되지 않을 수도 있다.
At least once 메세지 전송에 대해 최소 1번 처리할 것을 보장한다. Consumer는 1번 또는 여러번 메세지를 처리할 수 있다
Exactly once 메세지 전송에 대해 '정확히' 1번 처리할 것을 보장한다.
콜백의 경우 메세지가 중복으로 처리되더라도 크리티컬 하지 않지만 주문 생성의 경우는 중복이나 생성되지 않는 경우는 매우 크리티컬 하므로 메세지 중복 처리에 대한 문제를 해결 해야합 니다. 메세지 중복의 문제는 프로듀서와 컨슈머 각각 따로 설정이 필요하므로 어떻게 설정했는지 하나씩 살펴보도록 하겠습니다. 어플리케이션 별로 메세지를 처리하는 방식이 다를 수 있기 에 맞는 방식을 사용하시기를 권장드립니다.
1. 프로듀서 설정
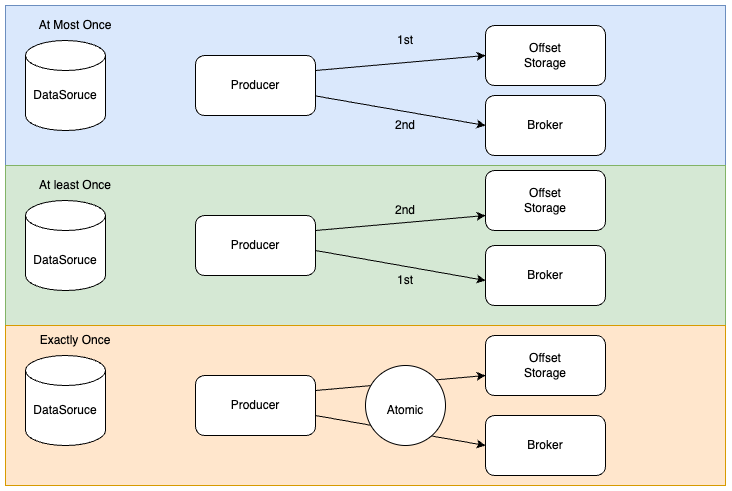
- Producer 가 메세지를 전송하다 실패하면 어떻게 될까요?
- 어떻게 하면 메세지를 전송에 성공했다 라고 알 수 있을까요?
| Configuration | Default | Description |
|---|---|---|
| retries | 2147483647 | 오류로 인해 실패한 record 전송 이력에 대해 재시도하는 횟수. 단 무한정으로 재시도하는게 아니라 delivery.timeout.ms 내에서만 재시도 따라서 client 는 retries 설정값으로 튜닝하는게 아닌 timeout 값으로 튜닝할 것을 권고 |
| delivery.timeout.ms | 120000ms = 2min | Producer 의 send 호출이 성공 또는 실패로 보고하는 최대 시간의 임계값 delivery.timeout.ms >= linger.ms + request.timeout.ms 를 준수할것 |
| linger.ms | 0 | Producer 가 데이터를 전송하는데 대기하는 시간. 대기하는 시간만큼 batch size 만큼 데이터의 용량을 쌓아둘 수 있음 |
| request.timeout.ms | 30000 = 30second | Producer client 가 요청응답을 기다리는 최대시간 |
| acks | all | Producer 가 요청을 보내고 Partition의 Leader 가 Replication 의 수신을 확인해야되는 개수. - 0: Producer 는 통보만 하고 수신여부를 확인하지 않음 - 1: Leader 의 Partition 에는 기록했지만, Replication 에게는 이제 기록해야됨을 수신 확인으로 통보 - all: 모든 Partition 에게 기록되었는지 확인을 통보받음 |
흔히 retries 설정값을 통해서 재시도를 제어할려고 하지만, 사실은 delivery.timeout 의 설정값을 기반으로 세팅해야 됩니다. 예를 들면 network timeout 이슈가 발생했을 때 client 가 응답을 받지 못하면 재시도를 하기 때문에 아래와 같이 메세지가 중복으로 발행이 될수 있습니다.

그러면 어떻게 Producer의 멱등성을 보장할 수 있을까요? 바로 PID 라는 ProducerId 를 통해서 어떤 Producer 가 어떤 record 를 기록하게 되는지 체크하게 됩니다. Producer 가 PID 를 지정하여 보내게 되면 처리하는 Broker 에서 PID 값을 기반으로 Record 에 대한 쓰기 작업을 단 한번만 하도록 중복 체크가 가능하게 됩니다.
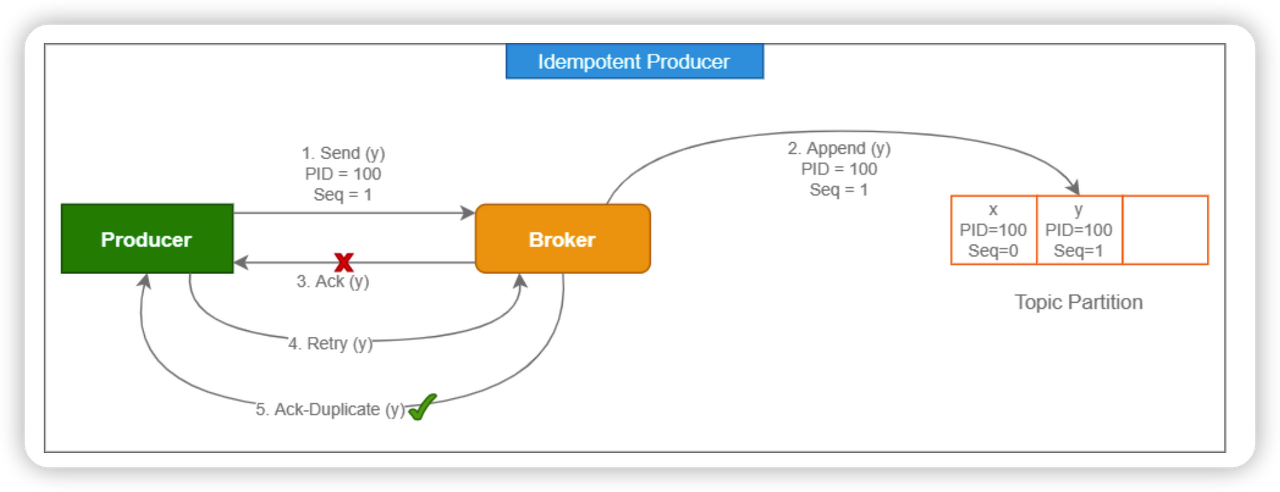
따라서 acks의 설정을 all로 enable.idempotence의 설정을 true로 설정을 해두면 멱등성을 보장 받을 수 있습니다.
2. 컨슈머 설정
컨슈머의 경우에는 프로듀서보다는 간단한데 enable.auto.commit의 설정을 메세지 처리방식을 결정합니다.
auto.commit = true일 경우 auto commit 정책 덕분에 application processing 에 지연이 생겨 fail 이 된다면, offset 은 commit 했지만, 메세지에 대한 비즈니스는 처리하지 못하게 됩니다. (at most once)
auto.commit = false 의 경우에는 수동으로 commit 을 하기 때문에 메세지를 중복처리하는 상황이 발생할 수 있습니다. 이번에는 Application 비즈니스를 먼저 수행하고, offset 을 commit 하기 때문에 발생하는 상황입니다. Application 단 비즈니스는 성공했지만, offset 을 commit 하는 과정에서 네트워크 이슈로 실패합니다. Consumer 는 다음번에 같은 offset 으로 메세지를 읽기 때문에, 메세지에 대해 중복으로 비즈니스를 수행하게 됩니다 (at least once)
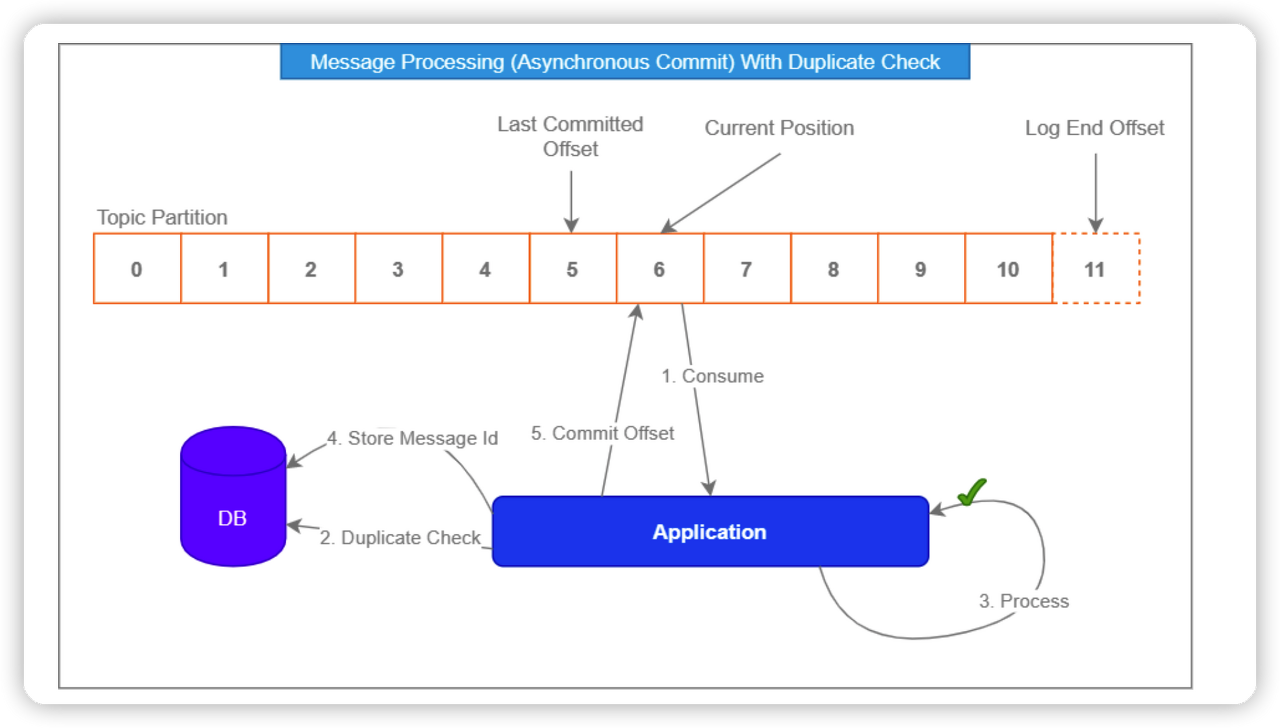
따라서 별도의 비즈니스 로직을 통해 처리를 해야합니다. Consumer 의 비동기 commit 인 auto.commit = true 를 활성화하고, 메세지에 대한 Consume 기록을 별도로 하는 방향입 니다. 그렇게 되면, Application 에서 Processing Fail 이 발생해도 안전하게 재시도가 가능하기 때문입니다. Application Processing 단계에 Kafka Consumer 가 exactly once 를 수행하는데에 있어서 방해가 되지 않도록 차단하게 됩니다.
참고.
https://kafka.apache.org/documentation/ https://www.confluent.io/blog/apache-kafka-producer-improvements-sticky-partitioner/ https://d2.naver.com/helloworld/6560422
