
카프카의 탄생
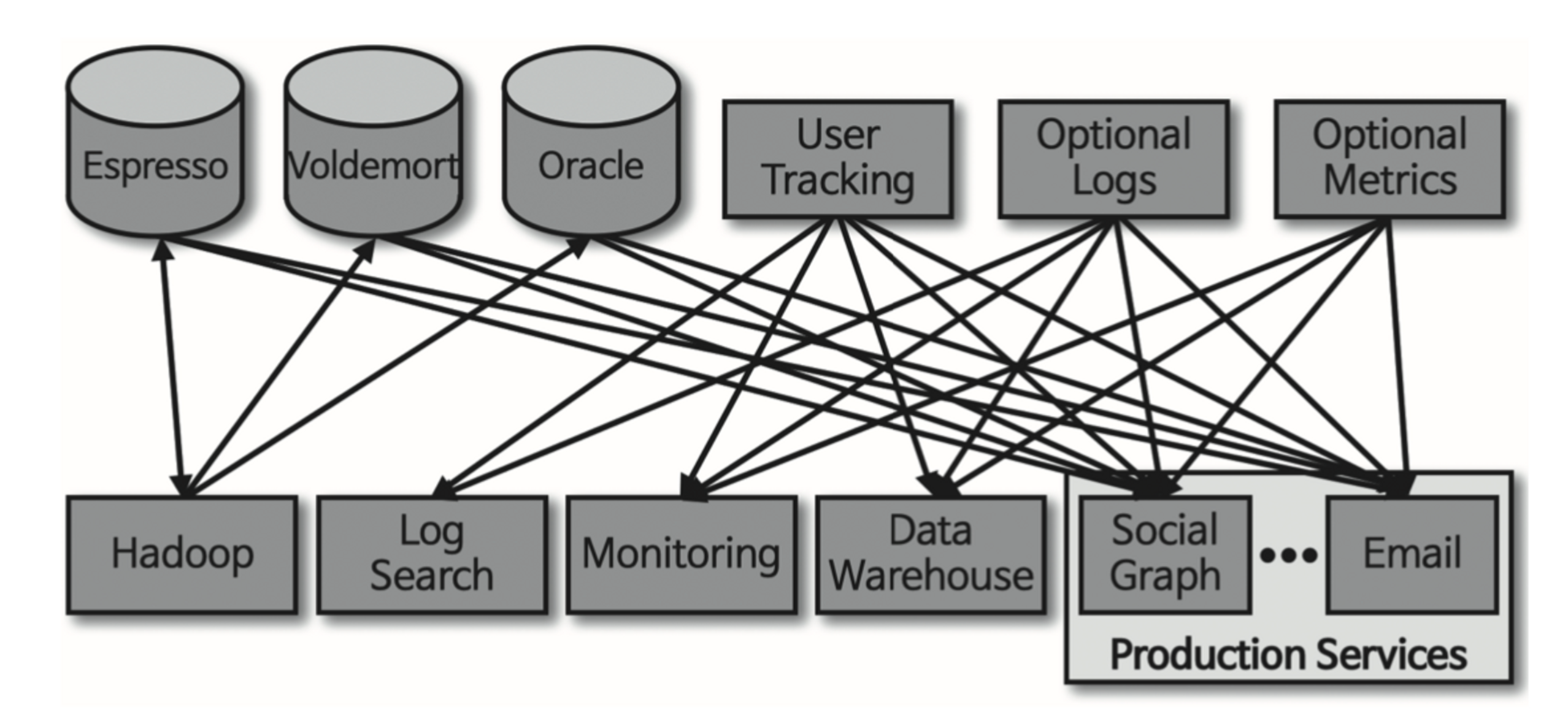
- 파편화된 데이터 수집 및 분배 아키텍처를 운영하는데 어려움이 있었다.
- 데이터를 생성하고 적재하기 위해서는 아래 2가지 Application이 연결되어야 한다.
- 데이터를 생성하는
Source Application - 데이터가 최종 적재되는
Target Application
- 데이터를 생성하는
- 초기에는 단방향 통신을 통해 직접 연결
- Source Application, Target Application 개수가 점점 많아지면서 문제 발생
- 파이프라인 개수가 많아지면서 버전 관리에 이슈 발생
- 장애 발생시, 그대로 다른 Application에 전파됨
Apache Kafka
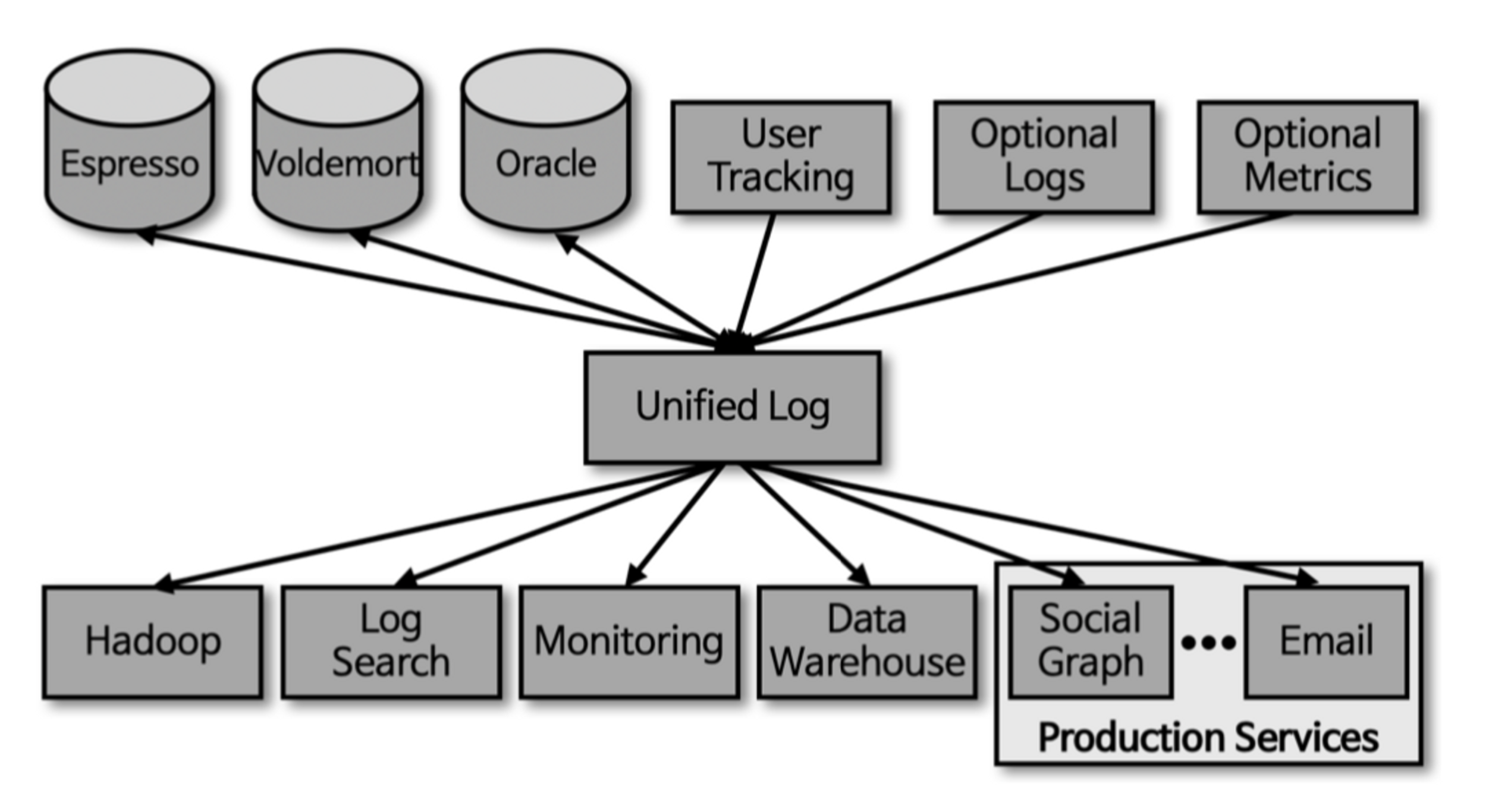
Kafka는 각각의 Application끼리 연결하여 데이터를 처리하는 것이 아니라 한 곳에 모아 처리할 수 있도록 중앙집중화했다.
- Kafka를 중아에 배치함으로써 Source Application과 Target Application 사이의 의존도를 최소화
- Coupling 완화
- Kafka에 데이터를 보내는 것이
Producer - Kafka에서 데이터를 가져가는 것이
Consumer
데이터 포맷
- Kafka를 통해 전달할 수 있는 데이터 포맷은 사실상 제한이 없다.
- 직렬화, 역직력화를 통해 ByteArray로 통신
- 따라서, Java에서 선언 가능한 모든 객체를 지원
- Kafka Client가 기본적으로 아래 타입들에 대응한 직렬화, 역직렬화 클래스 제공
ByteArrayByteBufferDoubleLongString
- Custom 직렬화, 역직렬화 클래스 설정 가능
Serializer<T>Deserializer<T>
KIP (Kafka Improvement Proposal)
카프카의 주요 변경사항을 제안하는 방법 중 하나이다.
Kafka Improvement Proposals - Apache Kafka - Apache Software Foundation
빅데이터 파이프라인에서 카프카의 역할
Data Lake
- Data Warehoue와는 다르게 필터링되거나 패키지화되지 않은 데이터를 저장
- 즉, 운영되는 서비스로부터 수집 가능한 모든 데이터를 모은다.
서비스에서 발생하는 데이터를 Data Lake로 어떻게 모을까?
- 웹, 앱, 백엔드 서버, DB에서 발생하는 데이터를 직접 End to End 방식으로 가능
- ❌ 하지만, 서비스가 커지면 복잡도가 올라가고 유지보수가 많이 요구됨
- 데이터를 추출(
Extracting)하고 변경(Transforming), 적재(Loading)하는 과정을 묶은 데이터 파이프라인을 구축해야한다.- 참고: ETL (카프카 나오기 이전에 사용되던 툴)
Kafka의 장점
높은 처리량
- Producer가 Broker로 데이터를 보낼 때와 Consumer가 Broker로부터 데이터를 받을때, 모두 묶어서 전송한다.
- 동일한 양의 데이터를 보낼 때, 네트워크 통신 횟수를 최소한으로 줄임
- 동일 시간 내에 더 많은 데이터를 전송 가능
- 대용랑의 실시간 로그데이터 처리하는데 적합
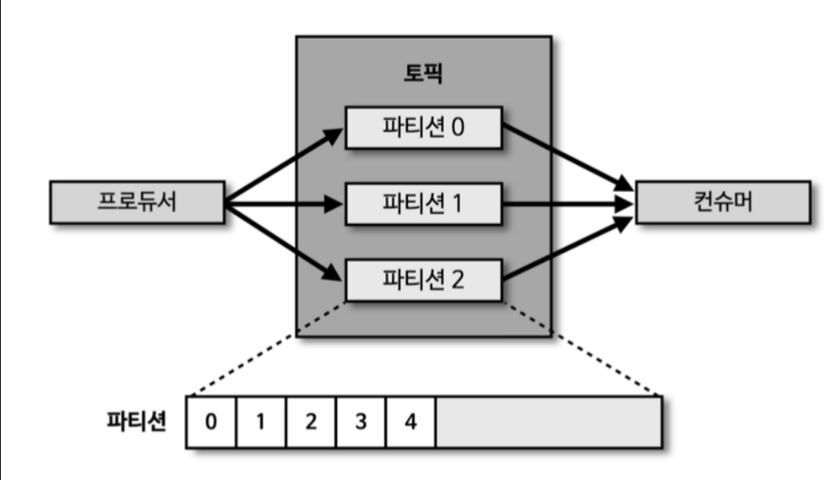
- 또한, 파티션 단위를 통해 동일 목적의 데이터를 여러 파티션에 분배하고, 데이터를 병렬 처리할 수 있음
확장성 (Scalability)
- 클러스터의 브로커 개수를 Scale-In, Scale-Out 가능
영속성
- 카프카가 비정상적으로 종료되더라도, 재시작하여 안전하게 데이터를 다시 처리할 수 있다.
- 카프카는 전송받은 데이터를 메모리에 저장하지 않고, 파일 시스템에 저장한다.
- 파일 I/O 성능 향상을 위해 페이지 캐시(Page Cache) 영역을 메모리에 따로 생성하여 사용
고가용성 (High Availability)
- 3개 이상의 서버들로 운영되는 Kafka Cluster는 일부 서버에 장애가 발생하더라도, 무중단으로 안전하고 지속적으로 데이터를 처리할 수 있다.
- Replication을 통해 고가용성의 특징을 가짐
- 프로듀서로 전송받은 데이터를 1대의 브로커에만 저장하는 것이 아니라, 다른 브로커에도 저장한다.
- 1대의 브로커가 장애가 발생하더라도, 복제된 데이터가 나머지 브로커에 Replication되어 있으므로 지속적으로 데이터 처리 가능
- Kafka Cluster를 브로커 3대 이상으로 구성해야 하는 이유
min.insync.replicas- 브로커에 데이터가 완전히 복제됨을 보장하는 최소 브로커 수
- 2로 설정하면 최소 2개이상의 브로커에 데이터가 완전히 복제됨을 보장함
min.insync.replicas설정 값보다 작은 수의 브로커가 존재할 때는 토픽에 데이터를 넣을 수 없다.
- 따라서 3대 이상으로 운영해야한다.
카프카의 미래
카프카는 데이터 파이프라인을 안전하고 확장성 높게 운영할 수 있도록 설계되었다.
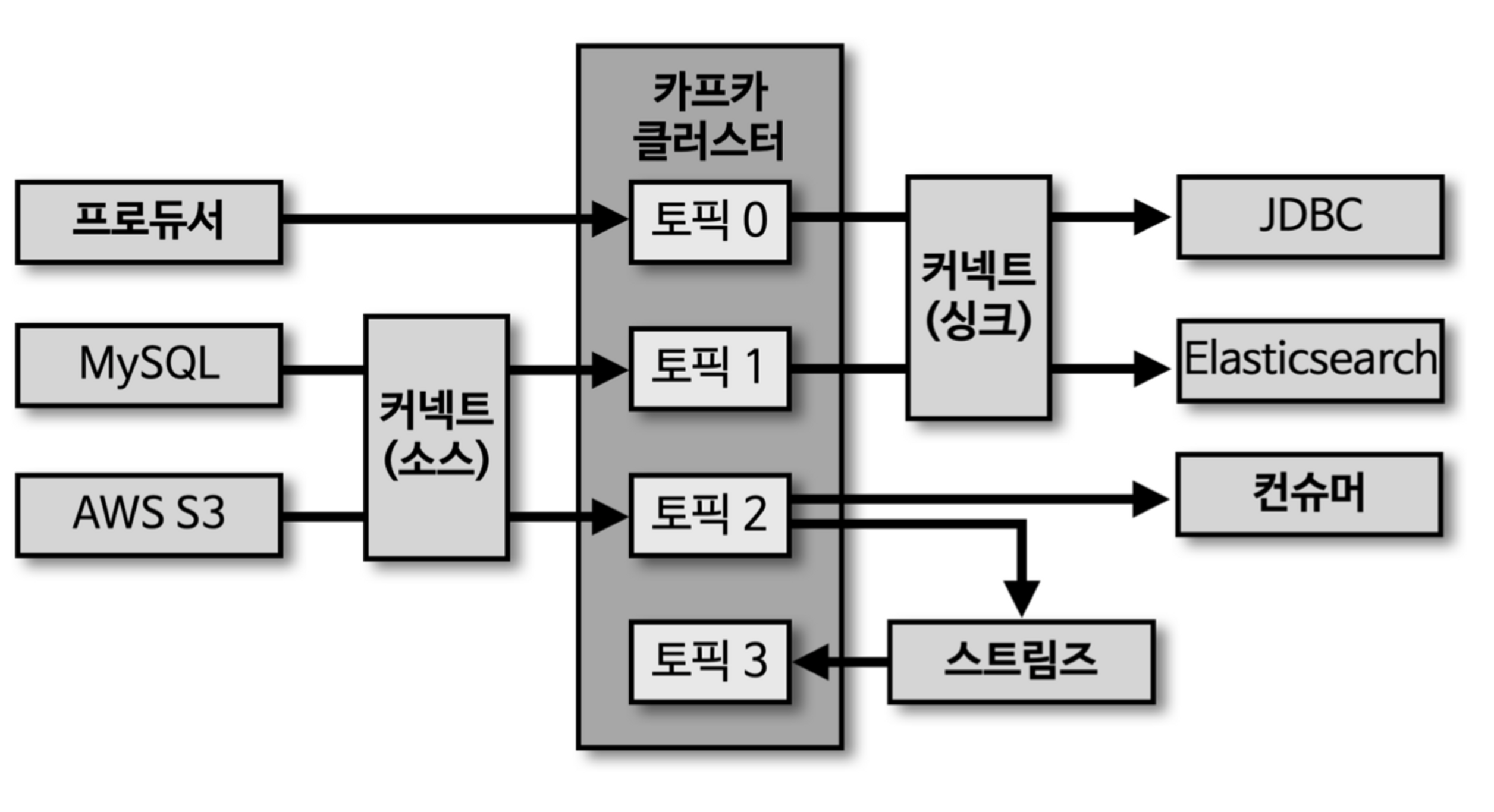
- 카프카 주변 생태계를 지탱하는 Application
- 커넥트
- 소스
- 싱크
- 스트림즈
- 커넥트
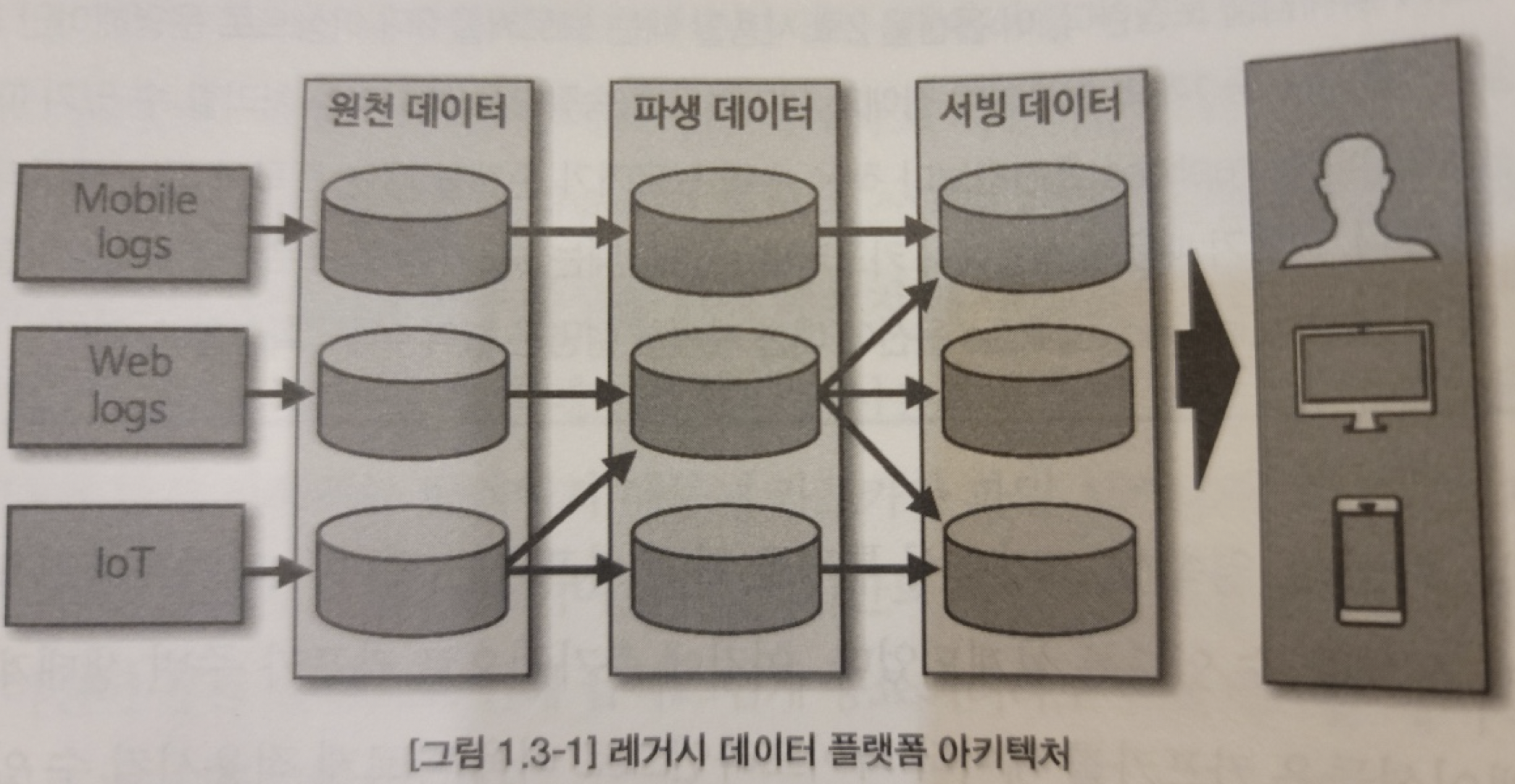
레거시 데이터 플랫폼 아키텍처
- 👎 데이터를 배치로 모으는 구조는 유연하지 못함
- 👎 실시간 생성되는 데이터들에 대한 인사이트를 서비스 Application에 빠르게 전달하지 못함
- 👎 원천 데이터로부터 파생된 데이터의 히스토리 파악하기가 어려움
- 👎 데이터가공으로 인해 데이터가 파편화되면서
Data Governance(데이터 표준 및 정책)를 지키기 어려움
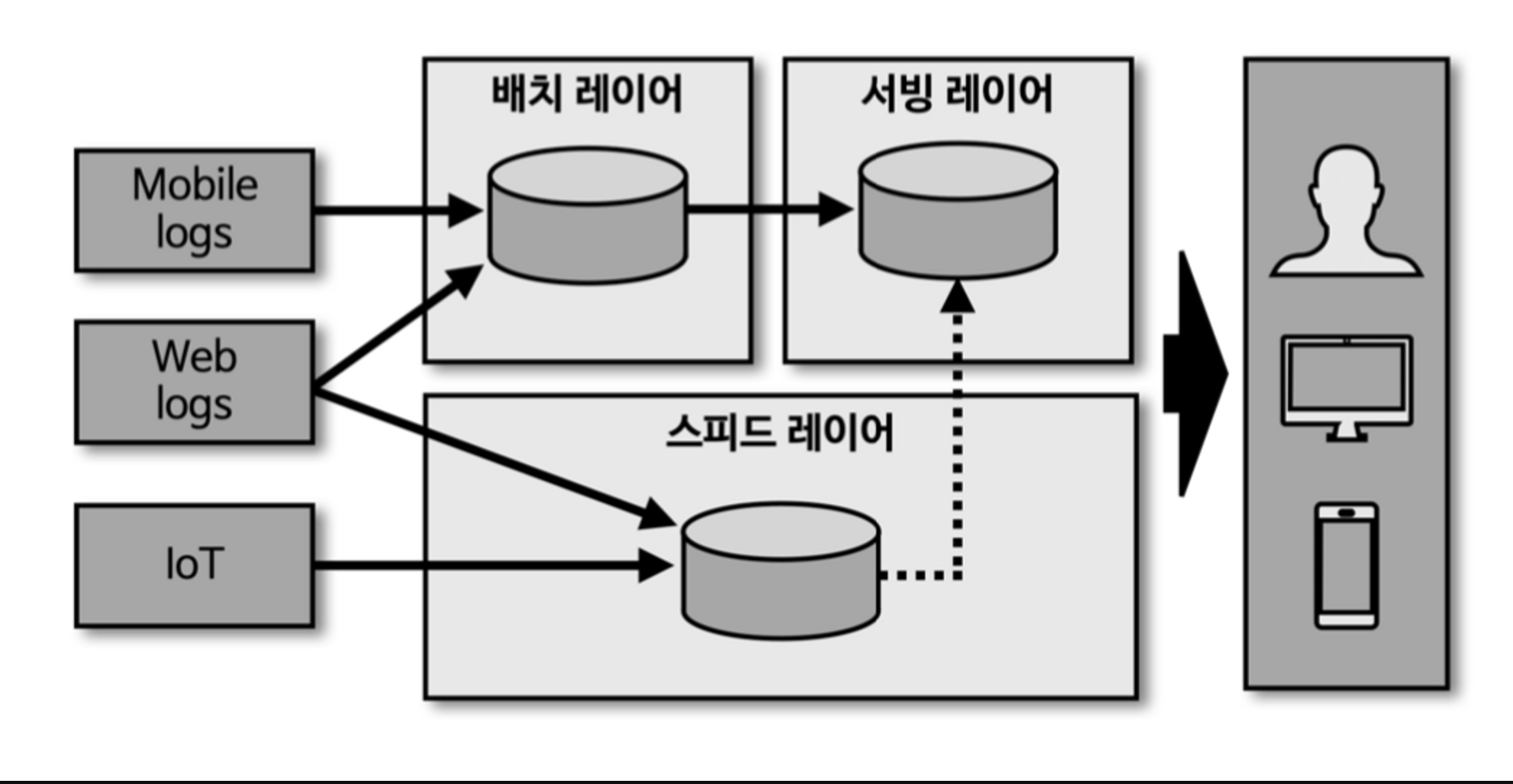
람다 아키텍처
- 스피드 레이어라고 불리는 실시간 데이터 ETL작업 영역을 추가로 정의한다.
배치 레이어 (Batch Layer)
- 배치 데이터를 모아서 특정 시간, 타이밍마다 일괄 처리
서빙 레이어 (Serving Layer)
- 가공된 데이터를 데이터 사용자, 서비스 Application이 사용할 수 있도록 데이터가 저장된 공간
스피드 레이어 (Speed Layer)
- 서비스에서 생성되는 원천 데이터를 실시간으로 분석
- 배치 데이터에 비해 낮은 지연으로 분석이 필요한 경우에 스피드 레이어를 통해 데이터를 분석한다.
- 스피드 레이어에서 가공, 분석된 실시간 데이터는 사용자 또는 서비스에서 직접 사용할 수 있음
- 필요한 경우에는 서빙 레이어로 데이터를 보내서 저장하고 사용함
람다 아키텍처의 단점
- 데이터 배치 처리하는 레이어와 실시간 처리하는 레이어를 분리
- 레이어가 2개로 분리되었다는 단점이 존재
- 결국에는 로직이 2개로 따로 존재해야됨. (로직의 파편화)
- 서밍버드
- 배치 레이어와 스피드 레이어 로직을 추상화하여, 1개 로직으로 배치 레이어와 스피드 레이어 구현가능하게 하는라이브러리
- 하지만 결국엔 디버깅과 배포는 분리됨
- 디버깅, 배포, 운영이 분리됨.
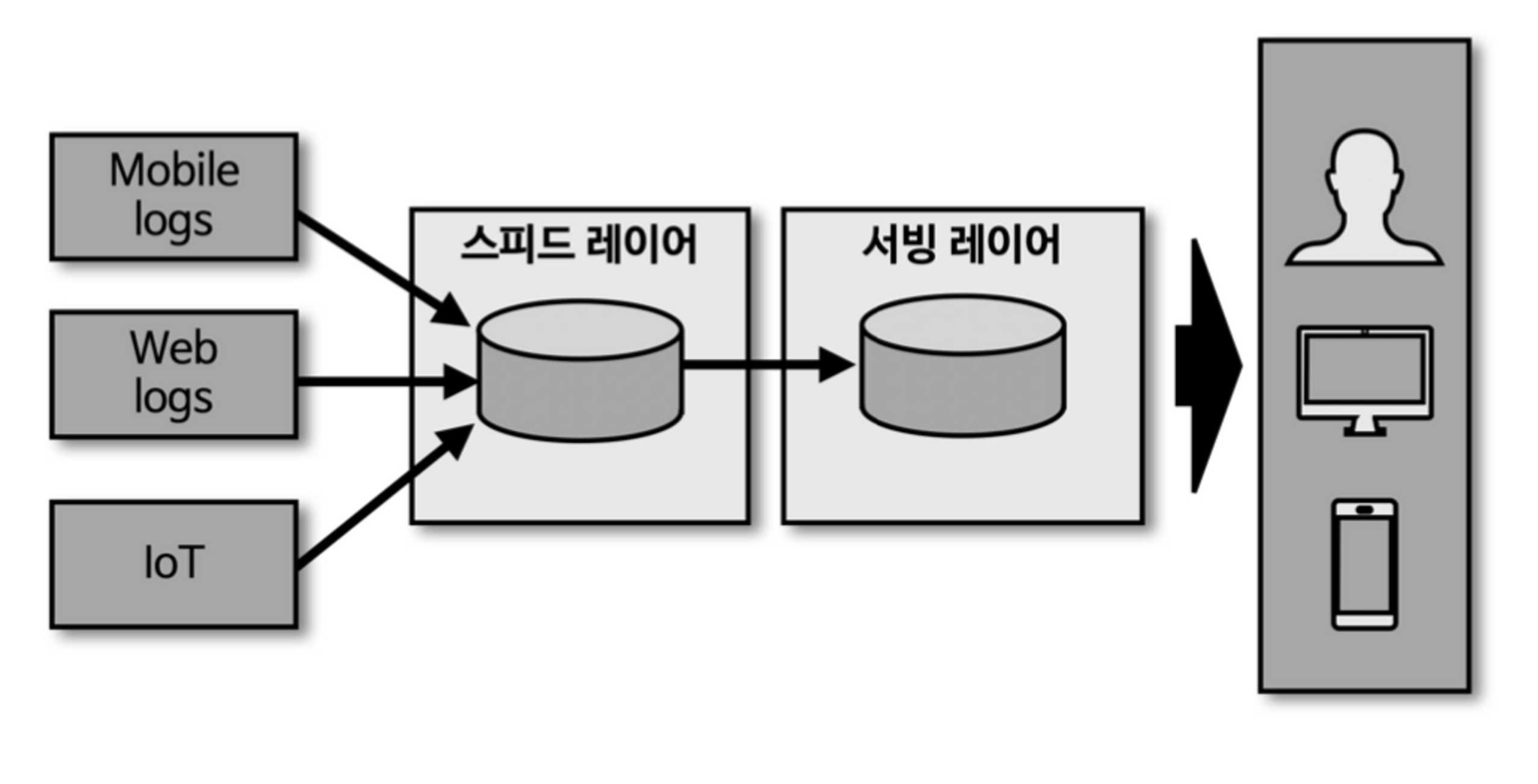
카파 아키텍처
- 람다 아키텍처에서 단점으로 부각되었던 로직의 파편화, 디버깅, 배포, 운영 분리에 대한 이슈를 해결하기 위해 배치 레이어를 제거한 카파 아키텍처를 제안하였다.
- 스피드 레이어에서 데이터를 모두 처리
배치 데이터 vs 스트림 데이터
- 배치 데이터
- 초,분, 시간, 일 등 한정된 기간 단위 데이터
- 예시
- 1분간 주문한 제품 목록, 2023년 고객 목록
- 스트림 데이터
- 한정되지 않은 데이터
- 시작 데이터와 끝 데이터가 명확히 정해지지 않은 데이터
- 예시
- 웹 사용자의 클릭 로그, 주식 정보, 사물 인터넷의 센서 데이터
배치 데이터를 어떻게 스트림 프로세스로 처리할수 있을까?
- 모든 데이터를 로그(log)로 바라보는 것
- 여기서 로그는 데이터의 집합을 뜻함
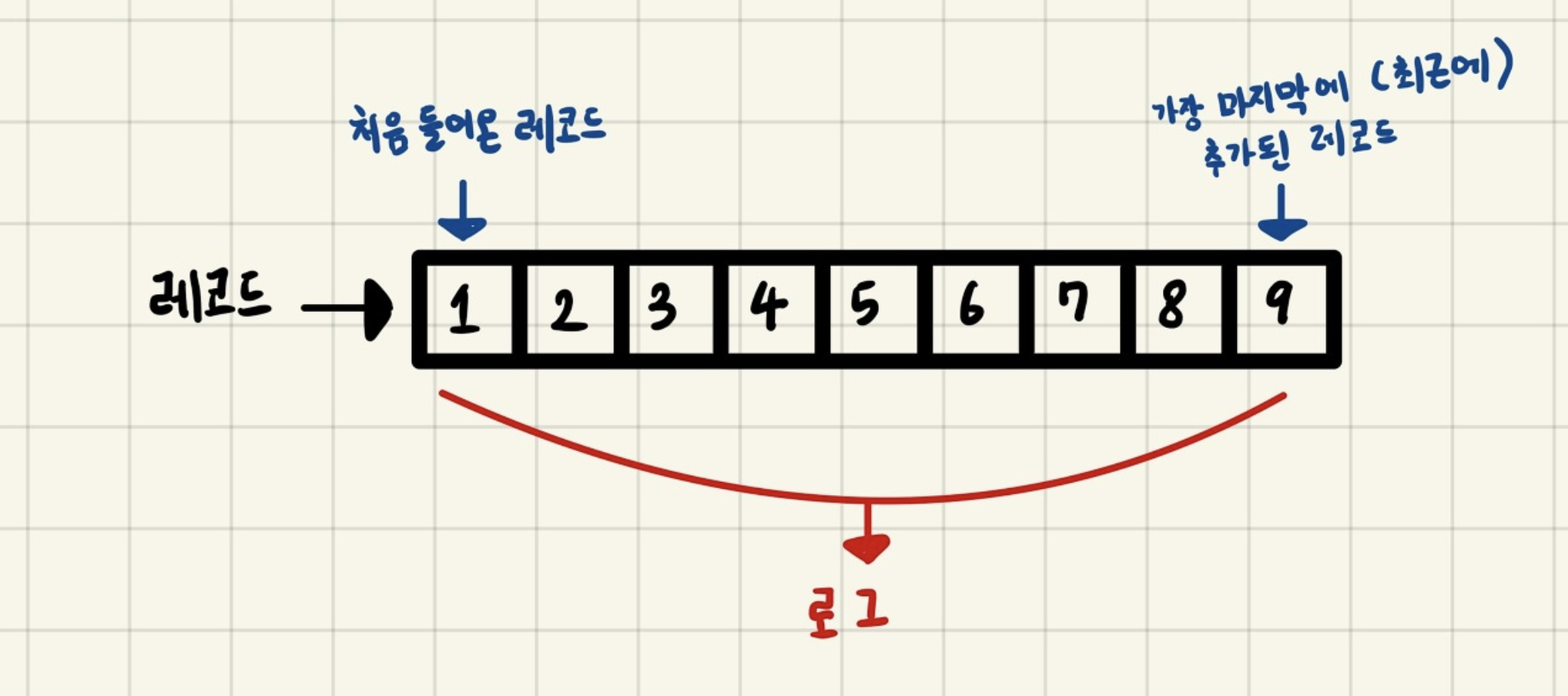
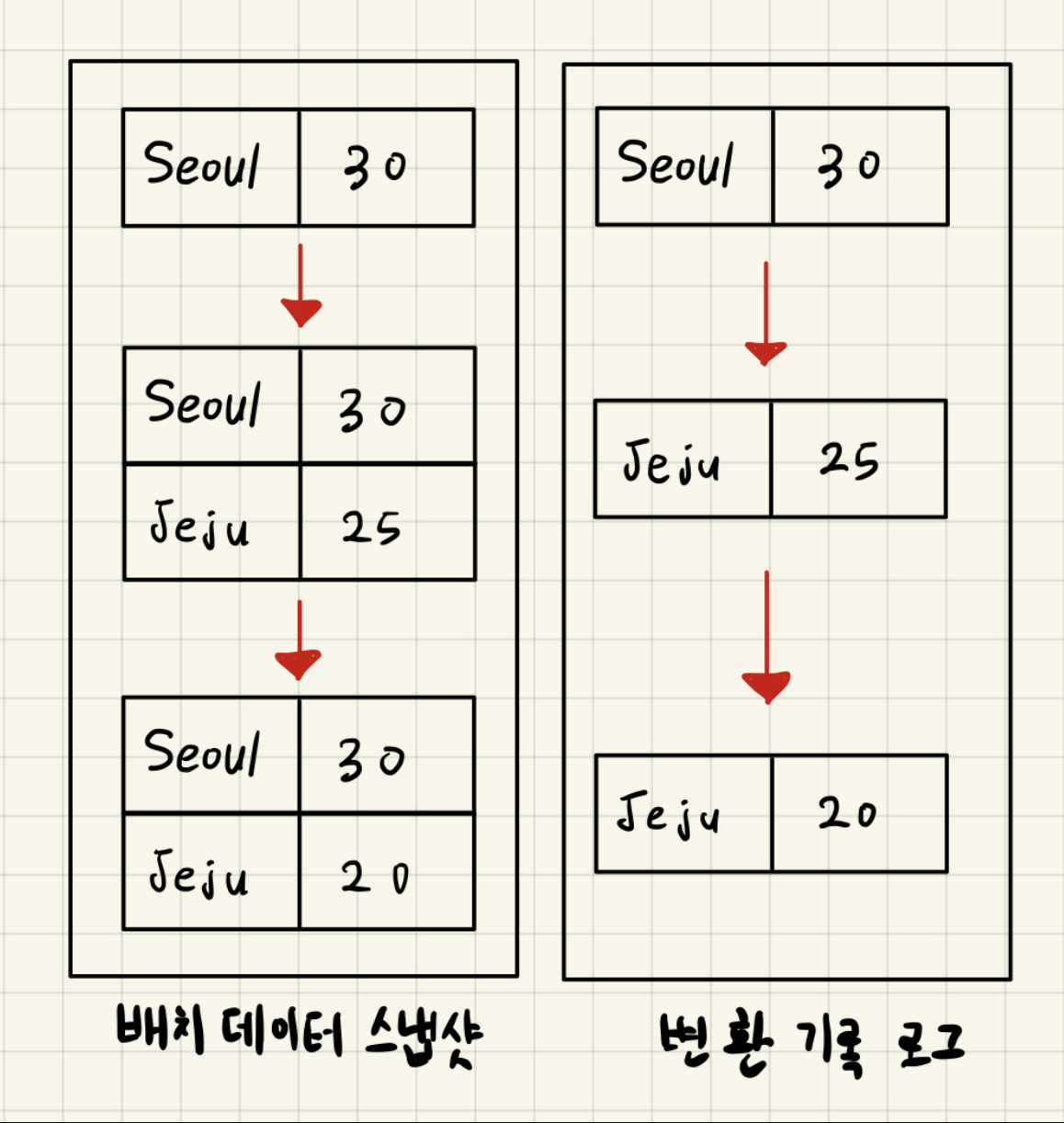
- 배치 데이터 스냅샷
- 배티 데이터를 표현할 때는 각 시점의 전체 데이터를 백업한 스냅샷 데이터를 뜻했다.
- 배치 데이터를 로그로 표현할 때는 각 시점의 배치 데이터의 변환 기록을 시간 순서대로 기록함
- 이를 통해 각 시점의 모든 스냅샷 데이터를 저장하지 않고도 배치 데이터를 표현할 수 있다.
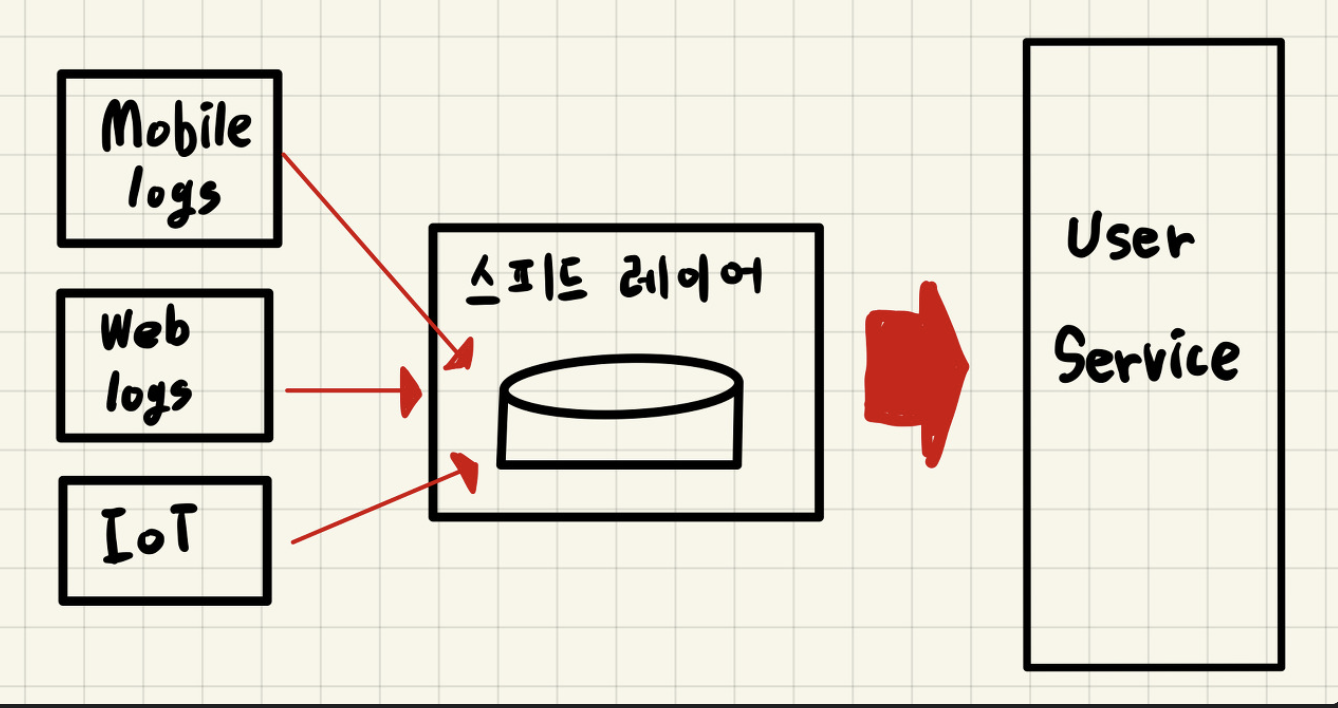
- 서비스에서 생성된 모드 데이터가 스피드 레이어에 들어오는 것을 감안하면, 스피드 레이어를 구성하는 데이터 플랫폼은
SPOF(Single Point Of Failure)가 될 수 있다. - 따라서 반드시
내결함성(High Availability)와장애 허용(Fault Tolerant)특징을 가져야 함.
스트리밍 데이터 레이크 아키텍처
- 서빙 레이어 데이터 플랫폼
- 하둡 파일 시스템 (HDFS)
- 오브젝트 스토리지 (S3)
- 카프카를 통해 분석하고 프로세싱한 데이터를 다시 서빙 레이어의 저장소에 저장할 필요가 있을까?
- 스피드 레이어로 사용되는 카프카에 분석과 프로세싱을 완료한 거대한 용량의 데이터를 오랜 기간 저장하고 사용할 수 있다면, 서빙 레이어는 제거되어도 된다.
- 운영 리소스를 줄여줌
- SSOT(Single Source Of Truth), 단일 진실 공급원
- 데이터의 중복, 비정합성과 같은 문제 해결
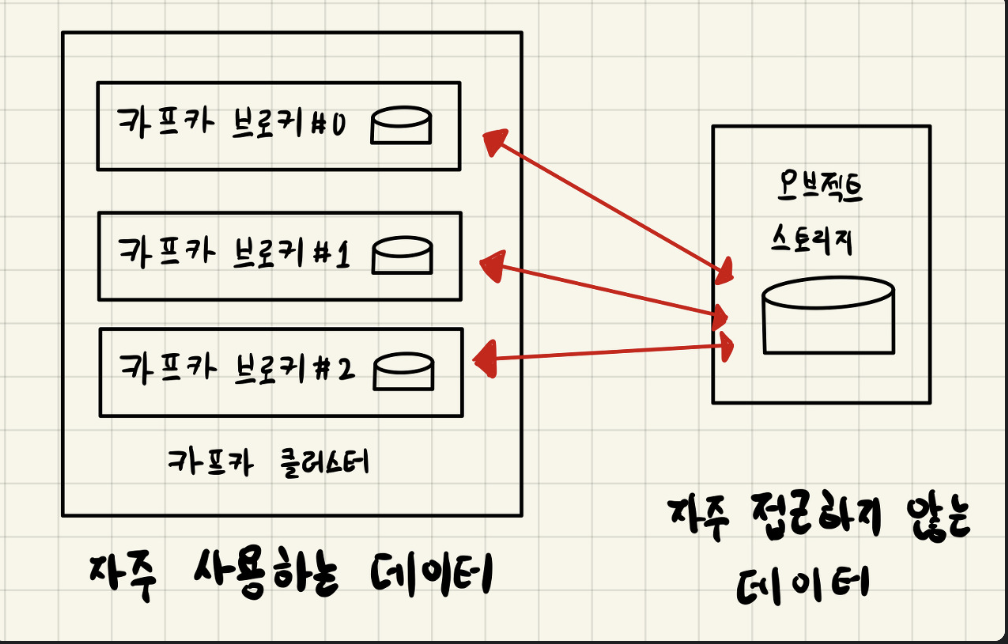
- 자주 접근하지 않는 데이터를 굳이 비싼 자원에 유지할 필요가 없다.
- 자주 사용하는 데이터만 브로커에서 사용하도록 기능 개발할 예정
- 데이터를 사용하는 고객이나 서비스에서 카프카의 데이터를 Query할 수있는 데이터 플랫폼이 필요
- ksqlDB - Event Streaming Database Built for Stream Processing
- 하지만 ksqlDB는 아직 타임스탬프, 오프셋, 파티션 기반 쿼리를 제공하지 않는다.
- ksqlDB - Event Streaming Database Built for Stream Processing

Hello velog!