[Paper Review] A Contrastive Framework for Neural Text Generation
A Contrastive Framework for Neural Text Generation

A Contrastive Framework for Neural Text Generation
- URL: https://arxiv.org/pdf/2202.06417.pdf
- Code: https://github.com/yxuansu/simctg
- Year: 2022
Motivation
- Conventional approach of training a language model trains with maximum likelihood estimation (MLE) and decodes the most likely sequence
- Despite its simplicity, it leads to the problem of degeneration;
- Generated texts from the language model tend to be dull and contain undesirable repetitions at different levels (e.g., token-, phrase-, and sentence-level)
- To alleviate this problem, previous solutions modify the decoding strategy by sampling from less likely vocabularies.
- Nucleus Sampling (a.k.a Top-p sampling)
- Compute the cumulative distribution and cut off as soon as the CDF exceeds P
- While nucleus sampling reduces the generated repetition, it introduces another critical problem of semantic inconsistency ;
The sampled text tends to diverge from or even contradict to the original semantics defined by the human-written prefix
- Nucleus Sampling (a.k.a Top-p sampling)
- Another approach addresses the degeneration probelm by modifying the model’s output vocabulary distribution with unlikelihood training

Observation
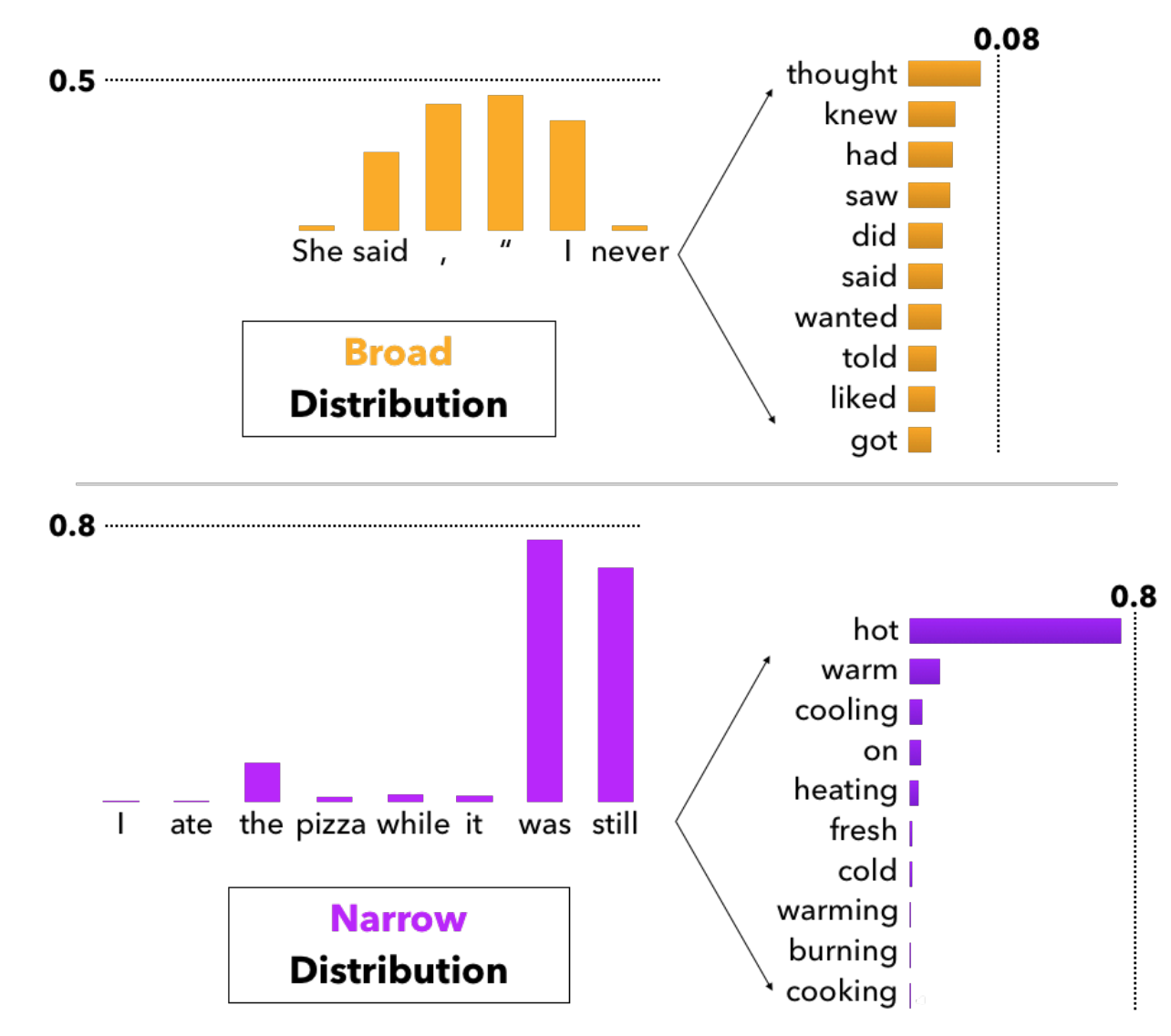
- Humans often choose words that surprise language models (Holtzman et al 2019)
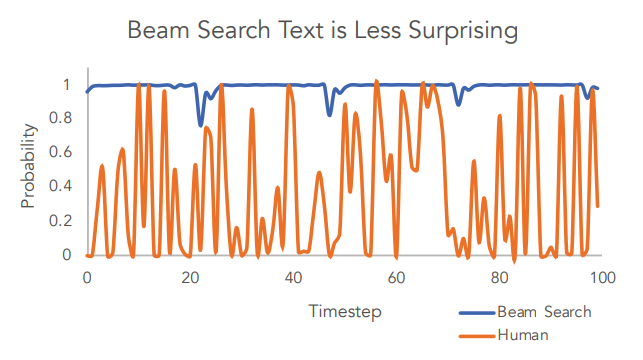
Probability assigned to tokens generated by Beam Search and humans, given the same context
- Furthermore, it is observed that the cosine similarities between tokens within a sentence are over 0.95, meaning that these representations are close to each other as shown in Figure 1(a)
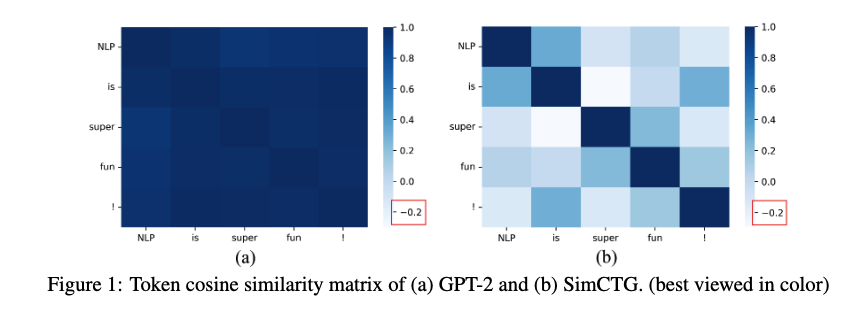
- Such high similarity in undesirable as it can naturally cause the model to generate repetitive tokens at different steps, leading to degeneration
- In an ideal setting,
- the token representations of the model should follow an isotropic distribution, i.e. the token similarity matrix should be sparse and the representations of distinct tokens should be discriminative as shown in Figure 1(b)
- Moreover, during decoding, the sparseness of token similarity should be preserved to avoid model degeneration.
Approach
Contrastive Training
- Based on the above motivations, SimCTG (a simple contrastive framework for neural text generation) is proposed to encourage the model to learn discriminative and isotropic token representations.
- Introduce a contrastive objective during pre-training of the language model
- Mathematical Expression
- Mathematical Expression


Contrastive Search
- Also present a novel decoding strategy, contrastive search, which aims at -
- At each decoding step, the output should be selected from the set of most probable candidates predicted by the model to better maintain the semantic coherence
- The sparseness of the token similarity matrix of the generated text should be preserved to avoid degeneration
- Mathematical Expression
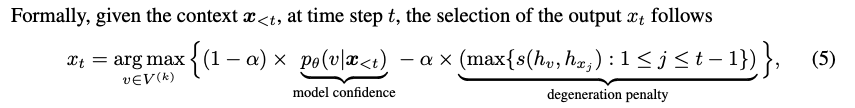
- is the set of most-probable candidates predicted by the language model (usually set 3~10)
- This implies that
- While selecting one of most probable tokens (model confidence)
- needs to be as dissimilar as possible from (degeneration penalty)
Experiment
Evaluate GPT2 base model (117M) with different training objectives - MLE, Unlikelihood and SimCTG - on two tasks with a wide range of metrics
Task1. Document Generation
Evaluate on Wikitext-103 dataset
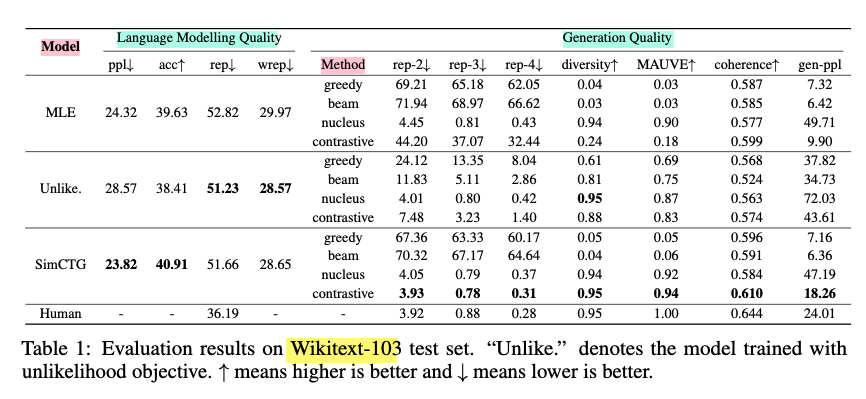
- Language Modeling Quality
- SimCTG achieves the best score on both perplexity (ppl) and next token accuracy (acc)
- SimCTG can make discriminative representations between generated text hence it is less confusing when making next token prediction
- Unlikelihood yields the best result on degeneracy metric (rep, wrep), but at the expense of unfavorable performance drops in ppl and acc
- SimCTG achieves the best score on both perplexity (ppl) and next token accuracy (acc)
- Generation Quality
- “SimCTG + contrastive search” is the optimal combination
- “{MLE, Unlikelihood} + contrastive search” could boost the result compared with greedy/beam search
Task2. Open-ended Dialogue Generation
Evaluate on LCCC (Chinese) and Daily Dialogue (english)
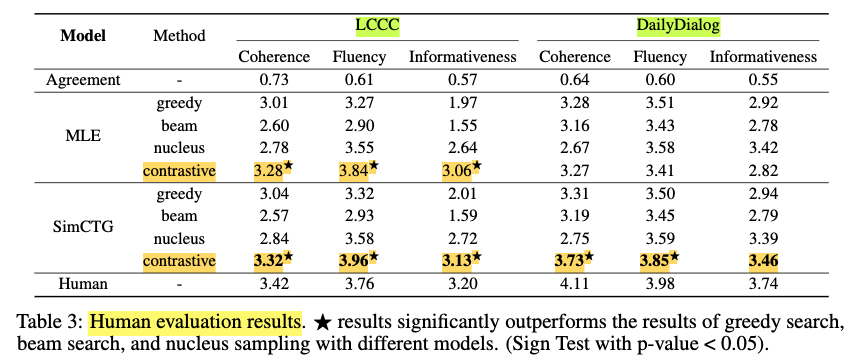
- “SimCTG + contrastive search” is once again the best combination
- “MLE+ contrastive search” is can be a better option than SimCTG + @
Ablation
-
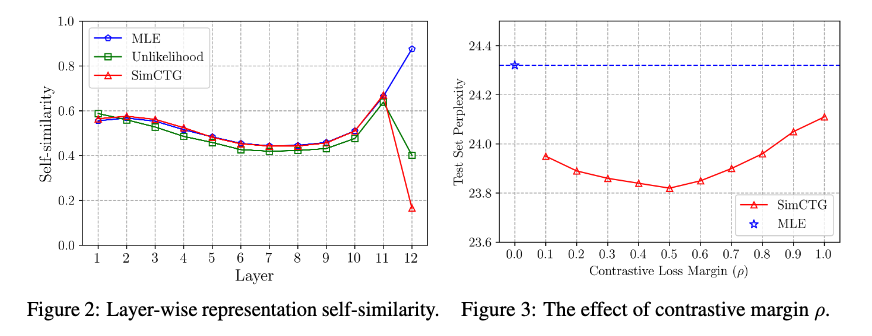
Self-Similarity (Figure 2)
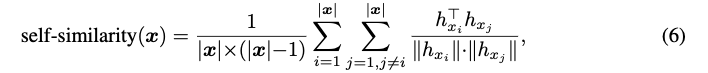
- In the intermediate layers(0~11), the self-similarity scores of different models are relatively the same.
- In contrast, at the output layer (layer 12), SimCTG’s self-similarity becomes notably lower than other baseline
-
Effect of Margin (Figure 3)
Margin loss with 0.5 shos the best result
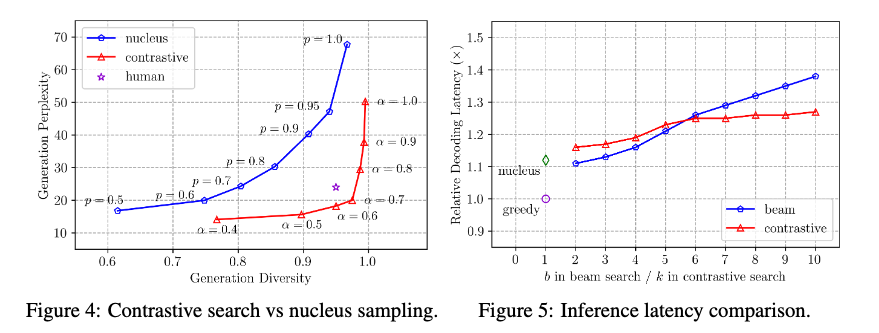
- Contrastive Search vs Nucleus Sampling (Figure 4)
- Human performance marked with purple
- Nucleus Sampling
- To meet human-level diversity, it requires high , but it leads to high ppl and vice-versa
- Contrastive Search
- leads to hum-level performance
- Latency (Figure 5)
- Contrastive Search is more or less as efficient as beam search
Visualization
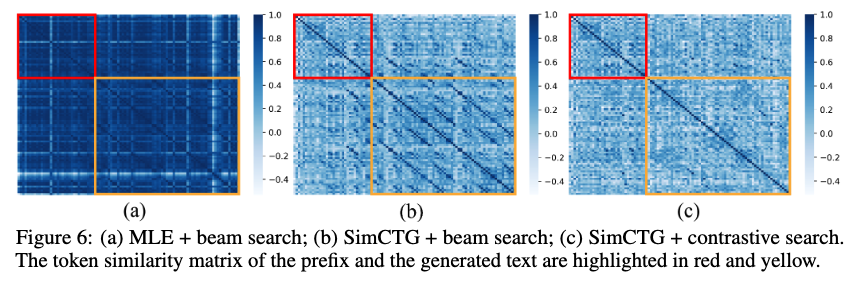
a. Very dense similarity matrix → token representations are not discriminative
b. A lot more sparse but still finds some dense regions along diagonal
c. The entire matrix is sparse and isotropic, “successfully solve degeneration”

The key to successful self-care is to find activities that help you to de-stress and relax. This could be anything from going for a walk to taking a relaxing bath. It could be reading a book or watching a movie. It could be spending time with friends or taking up a hobby. Whatever it is, make sure it is something that brings you a sense of joy and peace. Embroidery