AWS에서 사용 가능한 DB
- Postgres
- MySQL
- MariaDB
- Oracle
- Microsoft SQL server
- Aurora
DB의 프로비저닝은 완전히 자동화되어 있고 기본 운영 체제 패치 또한 자동이고 지속적 백업과 특정 타임스탬프도 복구 가능 이를 PITR 지정 시간 복구라고 한다.
스냅샷 : 사용자가 수동으로 발동시키는 백업으로 백업 보관기간을 사용자 임의로 설정 가능
읽기 전용 복제본을 최대 5개 까지 생성할 수 있다.
주된 RDS DB인스턴스와 두 읽기 전용 복제본 사이에 비동기식 복제가 발생한다.
비동기식 복제 : 애플리케이션에서 데이터를 복제하기 전 읽기 전용 복제본을 읽어들이면 모든 데이터를 얻을 수 있다.
읽기 전용 복제본은 SELECT만 가능하고 INSERT, UPDATE, DELETE는 불가하다.
AWS에서는 하나의 AZ에서 다른 AZ로 데이터가 이동할 때 비용이 발생한다.
같은 AZ에서는 읽기 전용이기 때문에 비용이 발생하지 않지만 다른 리젼일 때에는 비용이 발생한다.
재해 복구를 대비해서 읽기 전용 복제본을 다중 AZ로 설정할 수 있을까요?
네, 가능합니다.
단일 AZ에서 다중 AZ로 전환할 때에 데이터베이스를 중지할 필요가 없다.
RDS Security - 암호화
사용하지 않는 데이터인 미사용 데이터 암호화는 AES 256비트 암호화를 사용하는 AWS의 키 매니지먼트 서비스인 AWS KMS로 마스터 데이터베이스와 읽기 전용 복제본을 암호화할 수 있다.
- 마스터 DB를 암호화하지않으면 복제본도 암호화할 수 없다.
늘 SSL 인증서가 필요한 전송 중 암호화도 있고 이는 데이터 전송 중에 RDS로 암호화를 사용하는데 클라이언트에서 DB로 전송 중인 것이다.
모든 클라이언트가 SSL을 사용하도록 하려면
- PostgreSQL : rds.force_ssl=1 // 매개변수 그룹
- MySQL : DB 내부에서 GRANT USAGE ON.TO 'mysqluser'@'%' REQUIRE SSL;
-
RDS 백업을 암호화하는 방법
암호화 되지 않은 RDS 데이터베이스에서 스냅샷을 생성하려면 스냅샷 자체는 암호화 ❌
암호화된 RDS 데이터베이스에서 스냅샷을 생성하면 모든 스냅샷이 기본으로 암호화되는데 이는 항상 기본 값은 아니다. 그래서 암호화되지 않은 스냅샷을 암호화된 스냅샷으로 복제해야 합니다. -
암호화되지 않은 RDS 데이터베이스의 암호화 방법
- 암호화되지 않은 DB의 스냅샷을 생성
- 스냅샷을 복제하여 암호화 설정
- 암호화된 스냅샷으로 복구
- 암호화되지 않은 DB를 암호화된 DB로 전송
Network & IAM
네트워크 보안의 RDS 데이터베이스는 대게 퍼블릭 서브넷이 아닌 프라이빗 서브넷에서 배포된다.
따라서 DB가 www 에 노출되지 않도록 해야한다.
IAM 정책은 AWS RDS를 관리하는 사람만 제어할 수 있다.
IAM 인증을 사용한 RDS 연결법
MySQL과 PostgreSQL에서만 실행되고 암호 대신 인증 토큰이 필요하다.
RDS API 호출을 사용하해서 IAM으로 직접 얻을 수 있다.
인증토큰의 수명은 15분이다.
EC2가 API 호출을 실행해서 인증 토큰을 다시 받을 수 있다는 것이다.
이러한 접근의 장점
- 네트워크 안팎이 SSL로 암호화
- IAM은 DB 내부에서의 사용자 관리 대신 중앙에서의 사용자 관리에 사용한다.
-
미사용 데이터 암호화는 DB 인스턴스를 처음 생성할 때만 실행되며 암호화되지 않았으면 스냅샷을 생성해야 합니다.
-
스냅샷을 복제해 암호화한 다음에 암호화된 스냅샷에서 새 DB를 생성하면 DB를 암호화
-
파라미터 그룹과 DB가 SSL 연결만 허용하도록 구성되어 암호화되는지 확인
-
SSH 액세스가 발생하지 않도록 하고 DB나 OS 패치를 할 필요가 없다. 왜냐면 AWS에서 해주기 때문이다.
Aurora
Aurora DB Cluster
마스터는 유일하게 스토리지에 기록할 수 있는 것으로 변경과 장애 조치가 가능하기 때문에 오로라는 Writer Endpoint를 제공하는데 이것은 DNS 이름으로 Writer Endpoint는 늘 마스터를 향해서 마스터 장애 시에도 클라이언트는 Writer Endpoint와 통신해 올바른 인스턴스로 자동으로 리디렉션된다.
Reader Endpoint 라는 것은 Writer Endpoint와 동일한 기능이 있는데 로드 밸런싱의 연결을 돕고 모든 읽기 전용 복제본에 자동으로 연결한다. 클라이언트가 Reader Endpoint에 연결할 때마다 읽기 전용 복제본 중 하나가 연결돼 이런 식으로 로드 밸런싱이 된다.
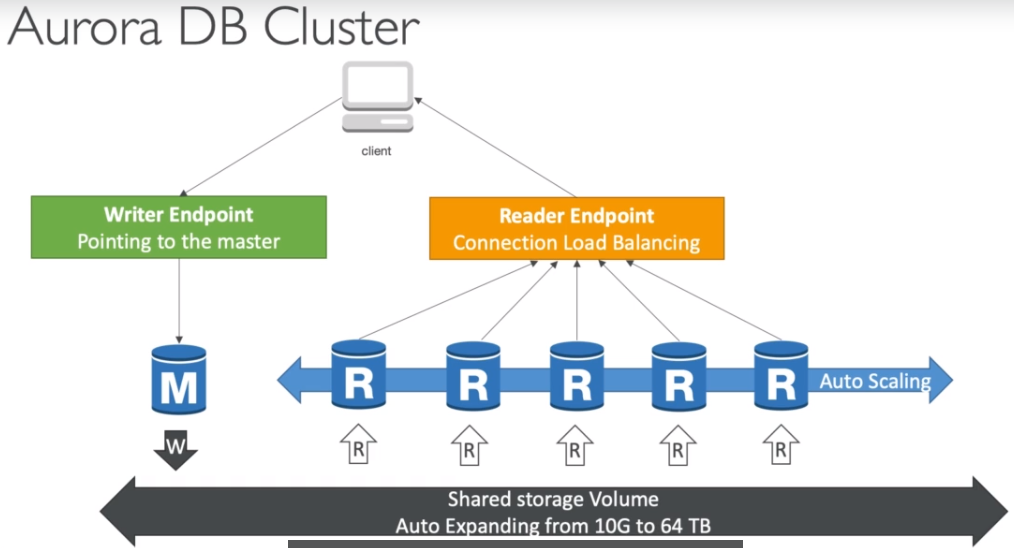
Reader Endpoint 로드밸런싱은 명령문 수준이 아니라 연결의 수준에서 발생
Aurora 기능
- 자동 장애 조치, 백업 및 복원
- 격리, 보안과 산업 규정 준수 기능
- 오토 스케일링을 통한 푸시 버튼식 스케일링
- 제로 다운타임의 자동 패치
- 백트랙 : 언제든지 데이터를 복원할 수 있는 기능이 있어 실제로 백업에 의존하지 않는다.
Aurora 보안
- RDS 와 같은 엔진을 사용하므로 보안은 비슷하다.
- Postgres와 MySQL이 있고 KMS로 미사용 데이터를 암호화
- 자동 백업과 스냅샷 그리고 복제본도 암호화되며 전송 중 암호화에는 SSL을 사용
- IAM 토큰을 사용한 인증도 있는데 RDS에서 본 것과 동일한 방식 이는, Postgres RDS와 MySQL의 통합으로 가능
- SSH를 인스턴스에 연결할 수 없다.
리더 클러스터에 더 많은 리더를 추가해 스케일링 용량을 추가할 수 있습니다.
다른 리전에 복제본을 얻으려면 리전 간 읽기 전용 복제본을 생성할 수 있습니다. 언제든지 복원할 수도 있습니다.
복제본 자동 스케일링를 추가할 수 있다. 정말 중요한 기능이고 정책을 생성할 수 있기 때문이며 오로라 복제본의 평균 CPU 사용량을 기반으로 하거나 오로라 복제본으로의 평균 연결 수를 기반으로 읽기 전용 복제본을 스케일링할 수 있다.
최소 1개 ~ 최대 15개 까지의 복제본을 얻을 수 있다.
전역 DB기능을 활성화 한 버전의 오로라를 선택한 경우에만 가능
오토 스케일링 복제본
Reader Endpoint에서 많은 읽기 요청이 있어서 오로라 DB의 CPU 사용량이 증가했다고 하자, 이 경우 오토 스케일링 복제본을 설정할 수 있다. 그렇게 되면 인스턴스가 자동으로 추가되고 Reader Endpoint가 이 새 복제본을 포함할 수 있도록 확장
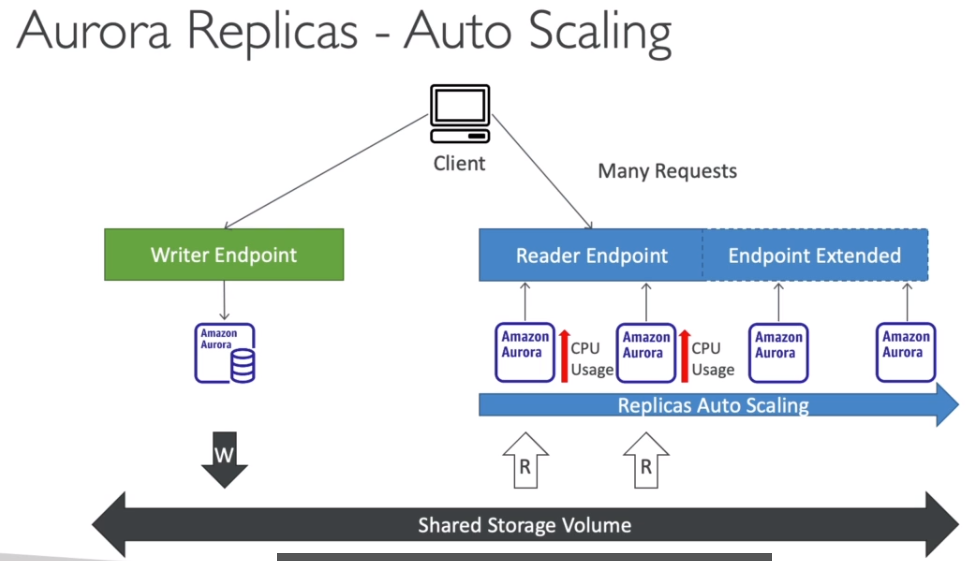
-
사용자 지정 엔드 포인트
오로라 인스턴스의 서브셋을 사용자 지정 앤드 포인트로 정의하기 위함이다.
이 두 개의 더 큰 오로라 인스턴스에서 사용자 지정 엔트 포인트를 정의한다.
왜냐하면 이 인스턴스가 더 강력하기 때문에 특정 복제본에 대한 분석 쿼리를 실행하는 것이 더 낫기 때문이다. -
다중 마스터
Writer Node에 대한 즉각적인 장애 조치를 원하는 경우 즉, Writer Node에 대한 높은 가용성을 원하는 경우에 쓴다.
오로라 클러스터에 있는 모든 노드가 읽기와 쓰기 작업을 합니다.
Amazon ElastiCache Overview
일래스틱 캐시는 레디스 또는 멤캐시트와 같은 캐시 기술을 관리할 수 있도록 한다.
캐시란 높은 성능과 낮은 지연시간을 가진 인 메모리 데이터베이스이다.
일래스틱 캐시를 사용하면 읽기 집약적인 워크로드의 부하를 줄이는데 도움이 된다.
일래스틱 캐시를 사용할 때 애플리케이션에 관한 몇 가지 어려운 코드 변경을 요청할 수도 있다.
히트캐시 : 이미 생성되어 일래스틱 캐시에 저장되었는지 확인하는 것
일래스틱 캐시에서 바로 응답을 얻어서 쿼리하기 위해 데이터베이스로 이동하는 동선을 줄여준다.
캐시 미스 : 데이터베이스에서 데이터를 가져와서 데이터베이스에서 읽는다.
동일한 쿼리가 발생하는 다른 애플리케이션이나 인스턴스에서는 데이터를 캐시에 다시 기록하여 다음에는 같은 쿼리로 캐시 히트를 얻도록 한다.
데이터를 캐시에 저장하기 때문에 캐시 무효화 전략이 있어야 하며 가장 최근 데이터만 사용하는지 확인해야 한다.
다른 아키텍처는 사용자 세션을 저장해 애플리케이션을 무상태로 만드는 것이다.
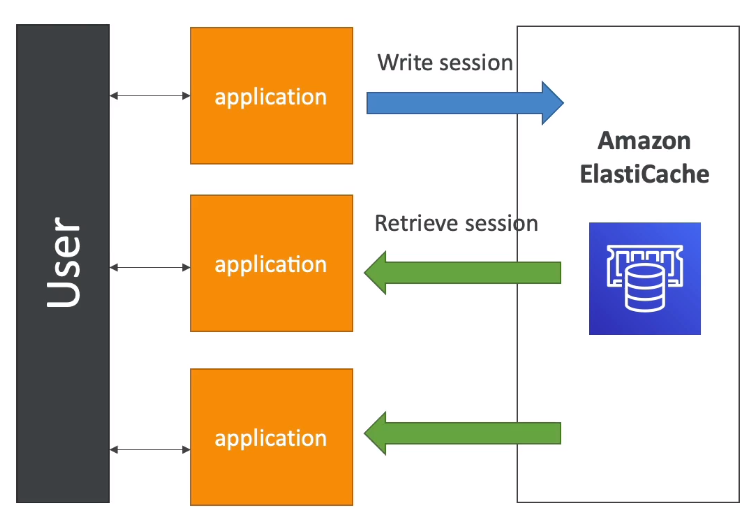
레디스(Redis)
- 자동 장애 조치로 다중 AZ를 수행하는 기술
- 읽기 전용 복제본은 읽기 스케일링에 사용되며 가용성이 높다.
- 지속성으로 인해 데이터 내구성도 있으며 백업과 기능 복원 기능도 있다.
멤캐시트(Memcached)
- 데이터 분할에 다중 노드를 사용 =>샤딩 (sharding)
- 가용성이 높지 않고 복제도 발생하지 않는다. 지속적 캐시가 아니다.
- 백업과 복원기능도 없다.
- 다중 스레드 아키텍처로 몇몇 샤딩과 함께 캐시에서 함께 실행되는 여러 인스턴스가 있다.
레디스는 고가용과 백업, 읽기 전용 복제본 등이 있다.
멤캐시트는 데이터를 손실할 수 없는 단순한 분산 캐시이고 가용성이 높지 않고 백업 기능이 없다.
일래스틱 캐시의 모든 캐시는 IAM 인증을 지원하지 않는다.
일래스틱 캐시에서 정의할 IAM 정책은 AWS API 수준 보안에만 사용된다.
즉, 캐시 생성, 캐시 삭제같은 종류의 작업을 의미한다. 그러나 캐시 내의 모든 작업은 IAM을 사용하지 않는다.
레디스 보안은 토큰을 통해 접근하거나 SSL을 지원한다.
멤캐시트는 좀더 강한 SASL을 지원한다.
일래스틱 캐시에 데이터를 불러오는 패턴
- Lazy Loading
모든 읽기 데이터가 캐시되고 데이터가 캐시에서 부실해질 수 있다. - Write Through
데이터를 오래된 데이터가 없는 데이터베이스에 기록될 때마다 캐시에 데이터를 추가하거나 업데이트 - Session Store
세션 저장소로 사용하여 Time To Live (TTL)속성으로 세션을 만료시킬 수 있다.
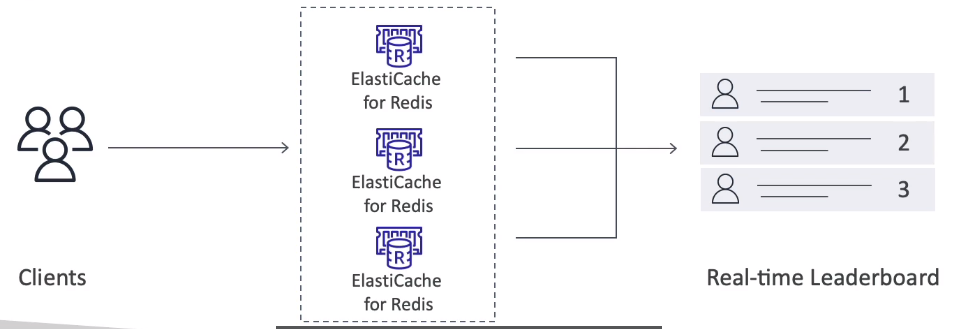
게임 리더보드 생성
순위를 가려내는 개념이다.
고유성과 요소 순서를 모두 보장하는 정렬된 집합이라는 기능이 있다.
요소가 추가될 때 마다 실시간으로 순위가 매겨진 다음 올바른 순서로 추가된다.
레디스 클러스터가 있는 경우 순위를 매기는 실시간 리더보드를 생성하는 개념이다. 그리고 모든 레디스 캐시는 동일한 리더보드를 사용할 수 있다.
클라이언트가 일래스틱 캐시와 통신할 때 실시간 리더보드에 액세스 할 수 있고 애플리케이션 측에서 이 기능을 프로그래밍할 필요가 없다.
실시간 리더보드에 접근하기 위해서 레디스의 정렬된 집합을 활용할 수 있다.
중요 포트:
- FTP: 21
- SSH: 22
- SFTP: 22(SSH와 동일)
- HTTP: 80
- HTTPS: 443
vs RDS 데이터베이스 포트:
- PostgreSQL: 5432
- MySQL: 3306
- Oracle RDS: 1521
- MSSQL 서버: 1433
- MariaDB: 3306(MySQL과 동일)
- Aurora: 5432(PostgreSQL 호환 시) 또는 3306(MySQL 호환 시)
Route53 CNAME vs Alias
CNAME
- 호스트 이름이 다른 호스트 이름으로 향하도록 할 수 있다.
- 이건 루트 도메인 이름이 아닌 경우에만 가능하다.
Alias
- Route53에 한정되지만 호스트 이름이 특정 AWS 리소스로 향하도록 할 수 있다.
- Alias 레코드는 루트 및 비루트 도메인 모두에 작동한다.
- 무료이고 자체적으로 상태 확인이 가능하다.
- EC2 DNS 이름은 Alias 레코드의 대상이 될 수 없다.
각 레코드로 보내지는 트래픽의 양(%)은 해당 레코드의 가중치를 전체 가중치로 나눈 값이다.
- traffic (%) = Weight for a specific record / Sum of all the weights for all records
가중치 0의 값을 보내게 되면 특정 리소스에 트래픽 보내기를 중단해 가중치를 바꿀 수 있다.
만약 모든 리소스 레코드 가중치의 값이 0인 경우에는 모든 레코드가 다시 동일한 가중치를 갖게 된다.
Route53 - Health Checks
- 공용 엔드 포인트를 모니터링 (애플리케이션, 서버, 다른 AWS 리소스)
- 계산된 상태 확인
- CloudWatch 경보의 상태를 모니터링하는 상태확인
- 이 상태 확인들은 각자의 메트릭을 사용하는데 CloudWatch의 지표에서도확인이 가능하다.
18% 이상의 상태확인이 엔드 포인트를 정상이라고 판단하면 Route53도 이를 정상이라고 간주합니다.
상태확인은 로드 밸런서로부터 2xx 나 3xx의 코드를 받아야만 통과가 된다.
상태확인에는 상당히 유용한 기능이 있는데
텍스트 기반 응답일 경우, 상태확인은 응답의 처음 5,120바이트를 확인한다. 응답 자체에 해당 텍스트가 있는지 보기 위해서이다.
네트워크 관점에서
아주 중요한 부분으로 상태 확인의 작동이 가능하려면 상태확인이 여러분의 애플리케이션 밸런서나 엔드 포인트에 접근이 가능해야 한다.
따라서, Route53의 상태 확인 IP주소 범위에서 들어오는 모든 요청을 허용해야 한다.
Health Check는 부모, 자식 관계 또한 가질 수 있고 이 상태 확인들을 모두 합치기 위한 조건은 OR, AND, NOT 만 사용할 수 있다.
하위 상태 확인을 256개까지 모니터링할 수 있다.
110.들을차례
