Introduction
데이터베이스에 관해 공부를 하고 또 검색을 하다보면 한가지 단어를 꾸준히 보게 되는데...바로
Indexing 이다. 그렇다. 오늘 블로깅의 토픽은 바로 인덱싱이다!
Definition
- 위키피디아에 따르면, 인덱스는 데이터베이스 분야에 있어서 테이블에 대한 동작의 속도를 높여주는 자료 구조를 일컫는다.
- 조금 더 이해하기 쉬운 개념은, 데이터베이스에 색인을 남긴다고 생각하면 될 것 같다. 쿼리가 실행되었을 때, 저장공간 접근 횟수를 최소화 해 데이터베이스의 성능을 최적화하는 방법이고, 또 데이터를 빠르게 찾고 또 접근하기 위해 사용하는 자료구조 기술이다.
- 서치 키를 인풋으로 받아, 조건에 맞는 데이터들을 효율적으로 반환한다.
Huh?
- 인덱스는 두 개의 열로 이루어진 작은 테이블로, 첫 번째 열에는 테이블의 기본키 혹은 기본키가 될 수 있는 후보키 의 복사본을 가지고 있고, 두번째 열은 그 키 값을 저장하고 있는 디스크 블락의 주소를 가리키는 포인터들을 보유하고 있다(서치키). 결국, 우리가 쉽게, 효율적으로 원하는 데이터를 가지러 갈 수 있게 도와주는 테이블이다.
인덱싱의 종류
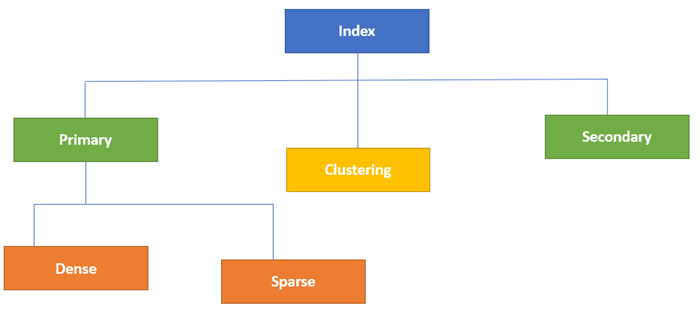
데이터 베이스의 인덱싱은 각자 고유의 속성에 따라 나눠진다. Primary와 Secondary Indexing이 주요 인섹싱 방법이다.
Primary Index
- Primary Index는 고정된 사이즈를 가지고 두 개의 열을 가진 정리된 파일이다. 첫 번째 열은 마찬가지고 기본 키를 가지고 있고 두번째 열은 특정 데이터 블럭을 가리키고 있다. Primary Index에서는 인덱스 테이블과 데이터 블럭이 일대일의 관계를 가지고 있다.
- 더 자세히 들어가보면, Primary Indexing은 두가지 종류로 나눌 수 있다.
- Dense Index- Sparse Index
Dense Index
- Dense Index에서는 데이터베이스에 저장된 모든 서치키마다 레코드가 생긴다. 이 점은 검색을 빠르게 해줄 수 있지만 인덱스 정보를 기록해야 하기 때문에 더 많은 저장 공간을 필요로 한다. 덴스 인덱싱에서는 두번열이 서치 키의 값과 디스크에 저장되 있는 실제 정보를 가리킨다.
- 한번의 디스크 검색만으로 서치 키를 사용해 어떠한 레코드던 찾을 수 있다. 키 값들이 정리되어 있기에 이진탐색을 할 수 있다. log2(n) 만큼 소요.
- 인덱스는 메인 메모리 버퍼에 영구 유지될 수 있을 만큼 작기에 메인 메모리 액세스만 해도 된다. 그만큼의 디스크 검색이 필요없다!
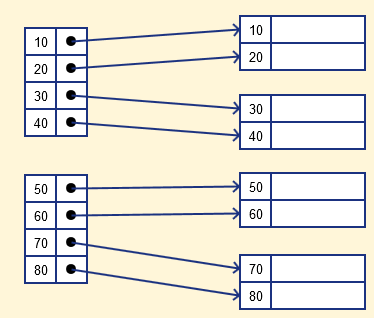
Sparse Index
- Sparse Index는 파일 안의 몇 개의 값을 위해 저장해 놓는 인덱스 기록 방법이다. 덴스 인덱싱의 저장공간 필요를 해결하는데 도움을 주는 이 방법은, 첫번째 인덱스 열이 같은 데이터 블럭 주소를 저장하기에 데이터가 필요할 때는 그 블럭의 주소를 불러온다.
- 하지만 몇 개의 서치 키 값을 위한 인덱스 기록만 저장하기 때문에 저장 공간이 덜 필요하고 overhead (주소를 가리키는 머리)를 추가하거나 제거할 때 신경쓸 부분이 줄어들지만 원하는 레코드를 찾아올 때는 블럭만을 가져오기에 덴스 인덱싱 보다 레코드를 찾아오는 부분에서는 속도가 느리다.
- 주어진 서치 키 값과 작거나 같은 값 중 가장 큰 값을 찾고, 마찬가지로 값이 정렬되어 있기에 이진 탐색이 가능하다. 이후로 블록을 찾으면 원하는 레코드를 찾기 위해 블록을 탐색한다.
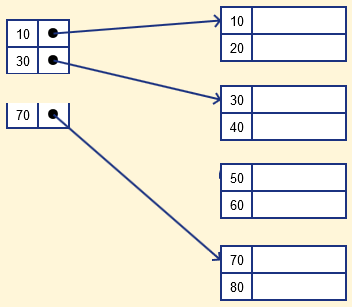
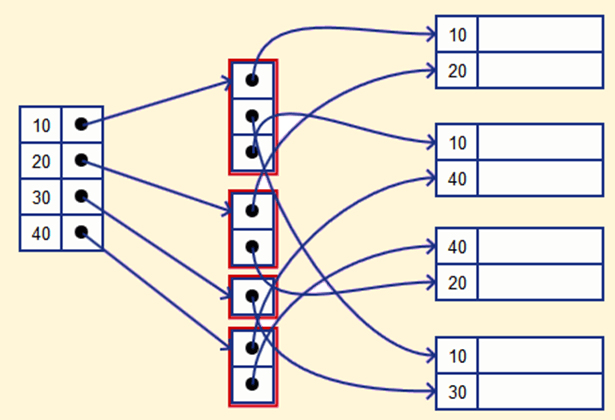
Multiple Levels of Index
-
인덱스 자체로 많은 데이터 블록을 커버 하지만 원하는 레코드를 찾기 위해 수차례의 디스크 검색을 수행해야 할 수 있다. 인덱스를 위한 인덱스를 사용하면 조금 더 검색과 인덱스 사용이 효율적이다.
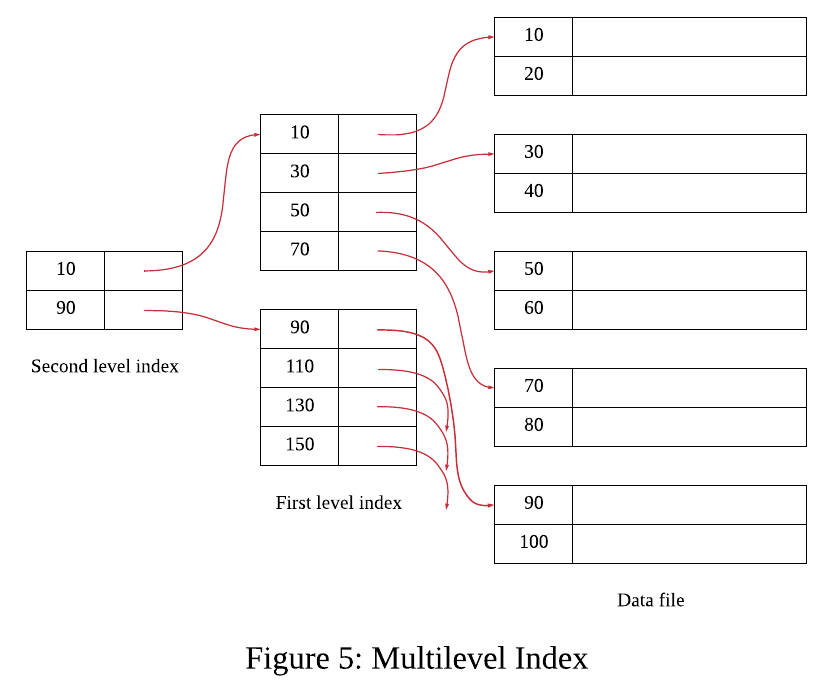
-
그림과 같이 sparse index를 혼합해서 인덱스를 위한 인덱스도 만들 수 있다.
원래의 인덱스를 First Level Index (or Inner Index) 라고, 추가한 인덱스는 Second Level Index (or Outer Index) 라고 한다. 유사하게, third와 fourth도 계속 추가할 수 있다.
최초의 인덱스가 아니라면, 이후에는 반드시 sparse Index여야 한다.
Indexes with Duplicate Search Keys?
- Dense Index는 모든 레코드의 값을 인덱스에 반영하기에 레코드가 중복될 경우 서치키가 중복될 수 있다. 이러한 중복을 해결하기 위해 중복되는 서치 키 값에 대해서는 한 개의 인덱스 항목과 포인터만을 둔다.
- Dense Index의 경우 중복 서치 키들에 대해 첫번째 값에 대해서만 레코드를 가리키게 설계.
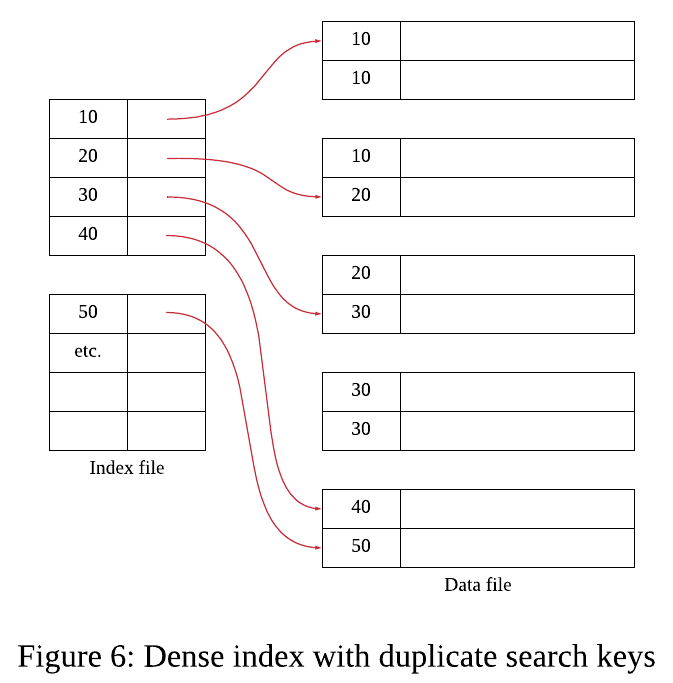
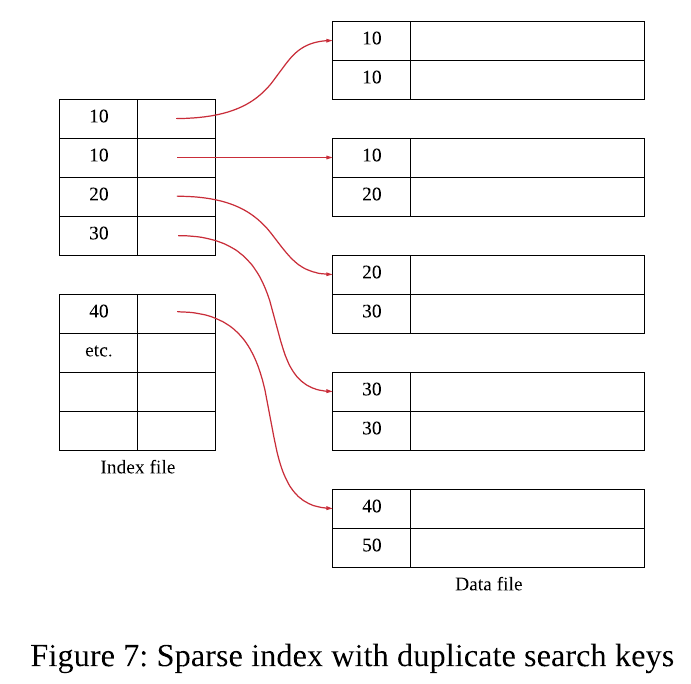
- Sparse Index의 경우 블록당 한개의 인덱스 항목과 포인터를 (서치키)를 두고 서치키는 블록의 첫 번째 레코드만 가리키도록 설계.
Managing Index w/ Data Modifications
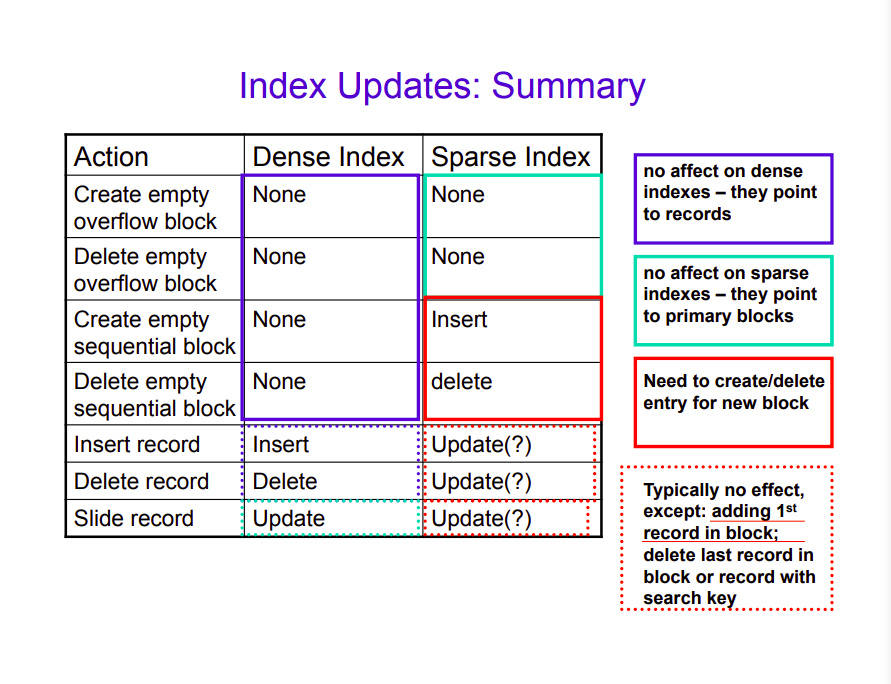
- 데이터는 시간이 지나면서 바뀌기 마련이기에 레코드는 삽입, 삭제, 혹은 갱신될 수 있다.
Sequential File(레코드가 순차적으로 정리된 파일) 과 같은 구조라면 한 블록이 다 차서 공간이 없을 경우 더더욱 블럭이 거대하게 변할 것이다. 데이터 파일을 순차적으로 재구성하는 방법 처럼 가능한 방법들이 있다.
- Overflow block 생성 / 삭제: 오버플로 블록이란 시퀀셜 파일에서 레코드를 삽입할 때 자리가 없으면 생성해 사용하는 것인데 이미 블럭안에 레코드들이 자리를 다 할당받아 차지하고 있기에 데이터 재구성이라는 번거롭고 비싼 과정을 대체하기 위해 오버 플로우 블록을 만들어 그 안에 레코드를 삽입한다. 하지만 서치키의 순서대로 시퀀셜 순서를 따르고 있지 않을 수 있어 탐색이 더 어려울 수 있다.

- 순차적인 정렬 하에 새로운 블록을 삽입할 수 있다. 이 경우 새로운 블록에 대한 항목을 sparse index에 추가해줘야 한다.
- 레코드를 블록에 삽입할 공간이 없으면, 인접 블록 (Adjacent Block)에 끼워 넣을 수 있다. 반대로 인접 블록이 비어 있으면 Combined(병합)될 수 있다.
인덱스 파일도 Sequential File이다. 그러므로 데이터 파일을 유지보수 하는 것과 유사한 전략을 사용할 수 있다.
Secondary Index
-
세컨더리 인덱스는 각 레코드에 유니크한 값을 가지고 있는 후보키로 필드를 만들고 또 non-clustering index라는 이름도 가지고 있다. 말 그대로 다른 인덱스를 돕는 보조 인덱스인데 주 인덱스가 레코드의 위치를 결정한다면, 보조인덱스는 레코드의 위치가 어딘지 알려주는 역할로 항상 덴스 인덱스를 사용해야 한다. 레코드의 중복이 일어날 수 있다.
-
위의 설명에서 나오듯 first level 과 second level로 인덱스를 나눠 사용하는 이유는 first level의 매핑사이즈를 줄여주기 위함인데, first level에서 숫자의 범위는 커야한다. 그래야 매핑 사이즈가 작게 유지될 수 있다.
-
예를 들면, 은행 계좌 데이터 베이스에서, 데이터는 계좌 번호에 따라 순차적으로 저장되어 있다. 만약 한 은행 브랜치에 있는 모든 계좌를 찾고 싶다면 먼저 은행 브랜치의 정보를 가지고 레코드를 향한 포인터를 지니고 있는 버켓에 연결한다. 그렇다면 그 버켓에서 서치키 정보에 부합하는 레코드들을 다 가리키기에 필요한 레코드를 다 가져올 수 있다.
Clustering Index
-
클러스터링 인덱스에서는 인덱스에 레코드를 향한 포인터가 저장되어 있는게 아닌 레코드 그 자체가 저장되어 있다. 이따금씩 인덱스는 각 레코드 고유의 기본 키가 아닌, 일반 키를 담고 있는 열로 만들어질 수도 있다. 이럴 경우 2개 이상의 열을 합쳐서 유니크한 값을 가져와 clustered index를 만들 수 있다. 이럴 경우 레코드 식별이 더욱 빨라진다.
-
예를 들어, 회사가 여러 부서의 직원들을 고용한다면 클러스터링 인덱스는 같은 부서에 근무하는 직원들마다 만들어야 한다. 인덱스 포인트는 클러스터 된 것을 통째로 가리킨다. 하지만부서 번호는 유니크 하지 않은 키이다.
*추가적으로 학습이 필요한 것 같다.
B-Trees
- B-tree는 인덱싱에서 흔히 사용하는 자료구조이다. 완전 이진 탐색 트리와 같은 멀티레벨 인덱트 포맷 기술이다. 이 자료구조는 인덱스를 생성할 파일의 크기에 적절한 만큼의 인덱스 레벨을 자동으로 유지하고, 모든 블록은 최소 절반 이상 차있게 된다.
- B 는 밸런스의 약자로, 루트로부터 리프까지의 모든 경로는 같은 길이이다. 세가지 레이어가 있는데, Root, Leaf, 그리고 Intermediate Layer(중간단계의 노드)로 이루어져있다.
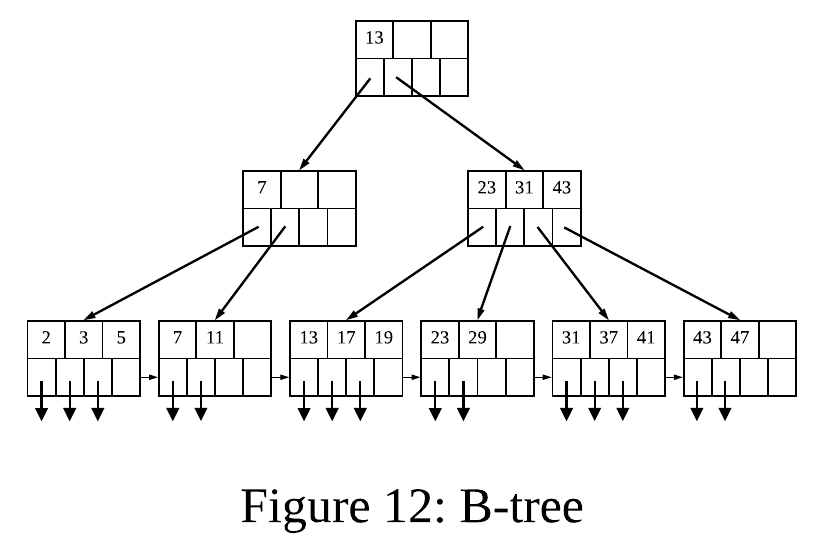
- 각 인덱스와 관련된 파라미터 n이 존재하고, 이 n은 모든 블록의 레이아웃을 결정한다.
- 각 블록은 n개의 서치 키 값과 n+1개의 포인터를 위한 공간이 있다.
- 리프 노드의 Key 값은 데이터 파일의 Key 값인데, 왼쪽에서 오른쪽으로 정렬되어있다.
- 루트에는 적어도 두개의 포인터가 사용된다. 트리처럼, 왼쪽과 오른쪽으로 뻗어나간다!
- 리프의 마지막 포인터는 그 다음 크기의 Key를 보유한 바로 오른쪽 노드를 가리킨다.
- 리프 블록 내의 다른 n개의 포인터 중, 적어도 (1+n)/2개의 포인터들은 데이터 레코드를 가리킨다. (안쓰이는 포인터는 널이다)
- i번째 포인터는 데이터의 i번째 key를 보유한 레코드를 가리킨다.
- Intermediate Layer에 있는 노드들의 모든 n+1개의 포인터들은 그 아래, 하위의 B-tree 블럭을 가리키는데, 적어도 (1+n)/2개의 포인터가 사용된다.
B-tree에 값을 추가하고 삭제하는 부분은 추후에...
Indexing의 장점
- 데이터를 가져오기 위한 Input, output 작업이 많이 줄어들기 때문에 인덱스 구조에서 데이터베이스의 행을 전만큼 접근할 필요가 없다.
- 유저에게 필요한 데이터를 빠르게 탐색해 더 빠르게 제공한다.
- 테이블 행에 연결을 할 필요가 없어 행 ID를 인덱스에 저장할 필요가 없기 때문에 데이블 공간이 줄어든다.
- 기본 키의 값으로 데이터를 분류할 수 있다.
Indexing의 단점
- 인덱싱 데이터베이스 관리 시스템을 사용하기 위해선 유니크한 값을 지닌 테이블의 기본 키가 필요하다.
- 인덱스 된 데이터에서 다른 인덱스를 사용할 수 없다.
- 인덱스로 정리된 테이블을 분할 할 수없다.
- SQL 인덱싱은 CRUD 쿼리의 성능을 감소시킨다.
Conclusion
데이터베이스 인덱싱을 그래도 간략하게, 전체적으로 공부했다. 아직 더 공부할 영역이 너무 많지만, 심해로 계속 빠져들고 있는 것 같아 나중에 조금 더 심화 토픽을 공부하고 싶을 때 하고 싶다. 인덱싱은 결국 탐색을 최적화 하고 또 검색을 빠르게 하기 위해서 하는 것인데 더 학습할 필요가 있다. 그래도 이론적으로 어느정도 알아보는게 목표였으니 그나마 안심이다.
참조
https://www.guru99.com/indexing-in-database.html#6
https://chartworld.tistory.com/18
https://www.quora.com/What-is-an-overflow-block-in-database
https://my.eng.utah.edu/~cs5530/Lectures/index.pdf
