
데이터 정규화
머신러닝에 사용되는 데이터는 그 값이 너무 크거나 작지 않고 적당한 범위 (-1에서 ~ 1사이)에 있어야 모델의 정확도가 높아진다고 알려져있다.
Normalization(정규화)
값의 범위를 0 ~ 1로 변환시킨다
ex)
from sklearn.preprocessing import MinMaxScaler
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
scaler = MinMaxScaler()
scaler.fit(data)
print(scaler.transform(data))결과
[[0. 0. ]
[0.25 0.25]
[0.5 0.5 ]
[1. 1. ]]0 ~ 1로 변환 시킴 -> 중간에 큰 값이 있어도 균일하게 변환됨
Standardization(표준화)
값의 볌위를 평균 0, 분산 1이 되도록 변환
📌 이상치(혼자만 값이 크거나 작은)가 있으면 표준화를 사용하는 것이 좋다.
ex)
from sklearn.preprocessing import scale
from sklearn.preprocessing import StandardScaler
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
scaler = StandardScaler().fit(data)
scaled_data = scaler.transform(data)
print(scaled_data)
print(scaled_data.mean(), scaled_data.std())
scaled_data = scale(data)
print(scaled_data)
print(scaled_data.mean(), scaled_data.std())결과
[[-1.18321596 -1.18321596]
[-0.50709255 -0.50709255]
[ 0.16903085 0.16903085]
[ 1.52127766 1.52127766]]
0.0 1.0평균 0, 분산 1이 되도록 변환됨
혼동 행렬 (confusion matrix)
혼동행렬(confusion matrix)은 모델의 성능을 평가할 때 사용되는 지표입니다.
우선 표를 먼저 보면
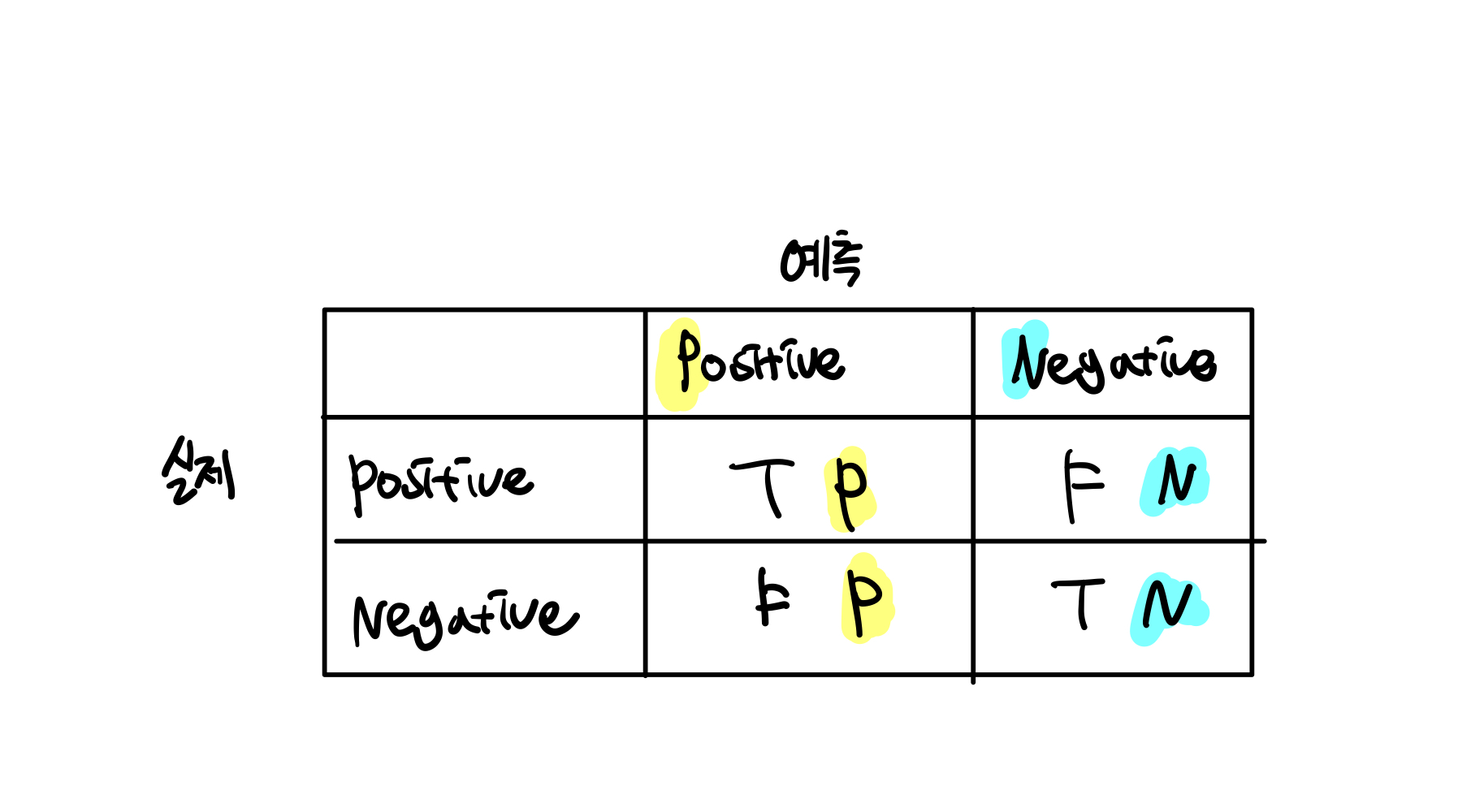
예를 들어 질병이 있는 사람을 질병이 없다고 예측한다는 예시가 있다고 하면
- 질병이 있는 사람을 없다고 예측 -> 틀린 예측 -> F
- 질병이 없다고 예측 -> 질병이 있는것과 없는 것 중 없는 것은 부정적으로 예측 한것
따라서 예측을 Negative 한것이다 -> N
위의 예시처럼 예측을 했을때 맞췄으면 T 아니면 F
예측을 부정적으로 했으면 N, 긍정으로 했으면 P
이렇게 구한 값을 가지고 아래 표처럼 지표를 구해서 평가하는 것이다.
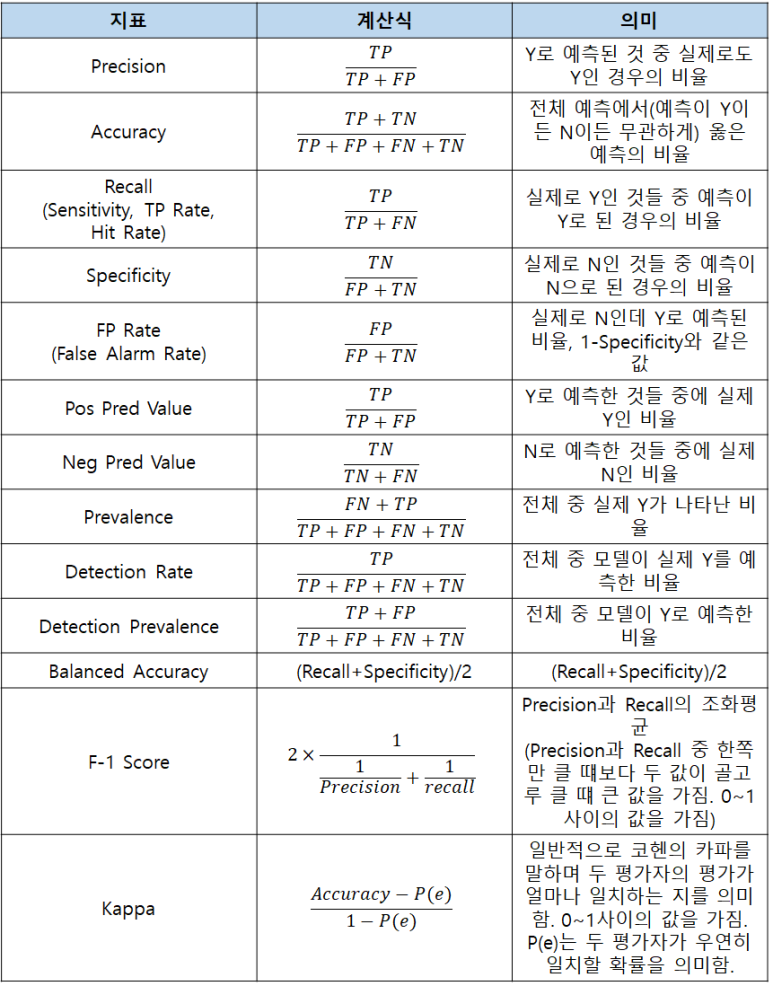
ex)
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
y_true = [0, 1, 2, 2, 2]
y_pred = [0, 0, 2, 2, 1]
print(accuracy_score(y_true,y_pred)) # 정확도
print(confusion_matrix(y_true, y_pred))
target_names = ['class 0', 'class 1', 'class 2']
print(classification_report(y_true, y_pred, target_names=target_names))결과
0.6
[[1 0 0] # [[실제 0을 0으로 예측, 1로 예측, 2로예측]
[1 0 0] # [실제 1을 0으로 예측, 1로 예측, 2로예측]
[0 1 2]] # [실제 2을 0으로 예측, 1로 예측, 2로예측]]
precision recall f1-score support
class 0 0.50 1.00 0.67 1
class 1 0.00 0.00 0.00 1
class 2 1.00 0.67 0.80 3
accuracy 0.60 5
macro avg 0.50 0.56 0.49 5
weighted avg 0.70 0.60 0.61 5
