안녕하세요.
오늘은 [탑 200 노래 제목에 가장 많이 들어가는 단어]를 주제로 시각화된 그래프를 만들어보도록 하겠습니다.
1. 노래 제목 크롤링하기
import requests
from bs4 import BeautifulSoup
from tqdm.auto import tqdm
from eunjeon import Mecab
import datetime
from dateutil.relativedelta import relativedelta
#가져올 날짜 구간 저장
date = datetime.date(2021, 12, 1)
delta = relativedelta(months=1)
date = date-delta
datebox=[]
while True:
date = date-delta
datebox.append(date.strftime('%Y%m%d'))
if date == datetime.date(2019, 1, 1):
break
#형태소 분석기 불러오기
mecab = Mecab()
#노래 제목 가져오기
title = []
for date in tqdm(datebox):
for page in range(1,5):
url = f"https://www.genie.co.kr/chart/top200?ditc=M&ymd={date}&hh=10&rtm=N&pg={page}"
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'}
res = requests.get(url, headers=headers)
soup = BeautifulSoup(res.text, 'lxml')
for t in soup.select('a.title.ellipsis'):
if not '19금' in t.text.split('(')[0].strip():
posbox=[]
for i, j in mecab.pos(t.text.split('(')[0].strip()):
if j in ['NNG', 'SL', 'NNP', 'IC', 'VV+ETM', 'MAG']:
title.append([date[4:-2]+'월', i, t.text.split('(')[0].strip()])
지니차트에서 노래 제목을 가져올거구요,
지니차트는 최근 2년의 데이터만을 공개해놓았길래 2019년 1월 ~ 2021년 10월까지의 데이터를 가져왔습니다.
url에 포스트 방식으로 넘어가는 날짜 데이터를 가져오기위해 날짜 구간을 datebox라는 변수에 저장했습니다.
그리고 requests 라이브러리로 각 월의 top 200 제목을 크롤링해온 후에
일반/보통명사, 외국어, 고유명사, 감탄사, 동사, 일반부사에 해당하는 형태소만을 title에 월과 함께 저장했습니다.
2. value_counts()로 빈도 세기
import numpy as np
import pandas as pd
import dataframe_image as dfi
df = pd.DataFrame(title, columns=['월', '단어', '원본'])
df = df[~df['단어'].str.contains('The')]
top_5 = pd.DataFrame(df['단어'].value_counts()[:5].rename('총 빈도'))
dfi.export(top_5, '총 빈도.png')
mf_box = []
for m in df['월'].unique():
mf = pd.DataFrame(df[df['월']==m]['단어'].value_counts()[:5].rename('빈도'))
mf['월'] = datetime.datetime.strptime(m.replace('월',''), '%m').strftime('%b')
mf = pd.DataFrame(mf)
mf = mf.reset_index().rename(columns={'index': '단어'})
mf_box.append(mf)
dfi.export(pd.DataFrame(mf), f'{m} 빈도.png')
mf_box = pd.concat(mf_box)
months = ['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec']
mf_box['월'] = pd.Categorical(mf_box['월'], months)
mf_box = mf_box.sort_values(by='월')우선 2년간 노래 제목에 쓰였던 가장 많은 수의 단어를 알아보기 위해 value_counts()로 카운트했습니다.
그리고 dataframe_image 라이브러리를 이용해 테이블을 이미지 파일로 저장해주었습니다.

2년간 노래 제목에 가장 많이 사용된 상위 5개 단어는 [사랑, 밤, 날, Love, 말]이군요.
사랑과 Love, 그리고 밤과 날이 함께 상위권에 위치한 것이 인상적입니다.
value_counts()로 저장된 형태소의 단어의 빈도를 센 후에,
Jan, Dec 와 같이 월의 이름을 따로 '월'이라는 컬럼에 넣어주었습니다.
그리고 순서를 지정해주기 위해 pd.Categorical()를 사용하고 sort_values()로 월별로 정렬을 해주었어요.
3. 선그래프로 시각화하기
테이블로 보면 '사랑'이 많이 보이는건 알겠는데 전체적인 데이터가 잘 와닿지 않네요.
그래서 선그래프로 시각화를 해주었습니다.
import plotly.express as px
fig = px.line(mf_box, x='월', y='빈도', color ='단어', category_orders={"월": months})
fig.update_traces(mode="markers+text+lines", textposition='top center', hovertemplate=None)
fig.update_layout(hovermode="x")
fig.update_layout(
font=dict(
family="Courier New, monospace",
size=21
)
)
fig.show()
fig.write_html("월 별 노래 제목 최빈도 단어.html")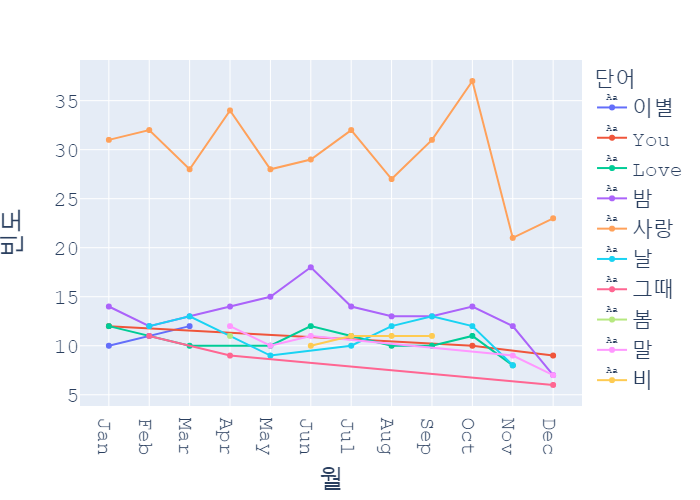
눈에 띄는 몇가지 단어들을 살펴보겠습니다.
'사랑'이 압도적으로 상위에 있고, 10월에 최고치를 찍었다가 11월에 급격히 감소한걸 볼 수 있습니다.
그 다음으론 비슷하지만 '밤'이 2위를 차지했네요.
밤이 짧아지고 더워지기 시작하는 5월에서 6월로 넘어갈때 '밤'이라는 단어가 급격히 상승했다가
밤이 길어지는 12월에는 밤이라는 단어가 하위권으로 넘어가는 것을 볼 수 있네요.
'그때'라는 단어는 1월과 12월에 등장하는 것도 흥미롭습니다.
겨울이 되면 '그때'를 자주 상기하게 되는걸까요?
'비'라는 단어가 장마철이자 가을비가 내리는 계절인 6~9월까지 등장하는 것도 인상적입니다.
특이하게도 계절에 따른 변화가 눈에 보이기 때문에, 계절로 묶어서도 시각화를 해보려고 합니다.
4. 계절별로 묶어서 시각화
# 일반적으로 3·4·5월을 봄, 6·7·8월을 여름, 9·10·11월을 가을, 12·1·2월을 겨울이라 한다.
def seasons(x):
if x['월'] in ('Jan|Feb|Dec'):
return '겨울'
elif x['월'] in ('Mar|Apr|May'):
return '봄'
elif x['월'] in ('Jun|Jul|Aug'):
return '여름'
elif x['월'] in ('Sep|Oct|Nov'):
return '가을'
mf_box['계절'] = mf_box.apply(seasons, axis=1)
season_box = []
for s, w in mf_box[['계절','단어']].values:
total = mf_box[(mf_box['계절'] == s) & (mf_box['단어'] == w)]['빈도'].sum()
if [w, total, s] not in season_box:
season_box.append([w, total, s])
season_df = pd.DataFrame(season_box, columns=['단어','빈도','계절'])
four_seasons = ['봄','여름','가을','겨울']
season_df['계절'] = pd.Categorical(season_df['계절'], four_seasons)
season_df = season_df.sort_values(by='계절')
fig = px.line(season_df, x='계절', y='빈도', color ='단어', category_orders={"계절": four_seasons})
fig.update_traces(mode="markers+text+lines", textposition='top center', hovertemplate=None)
fig.update_layout(hovermode="x")
fig.update_layout(
font=dict(
family="Courier New, monospace",
size=21
)
)
fig.show()
fig.write_html("월 별 노래 제목 최빈도 단어.html")구글에 계절의 구분을 검색하자 [일반적으로 3·4·5월을 봄, 6·7·8월을 여름, 9·10·11월을 가을, 12·1·2월을 겨울이라 한다.]는 결과가 나왔으므로 이에 따라 4계절을 구분하겠습니다.
우선 월에 맞는 계절을 반환해주기 위해 seasons라는 함수를 만들어 apply() 함수로 적용해주었습니다.
그리고 계절에 따른 단어들의 빈도를 합쳐주었습니다.
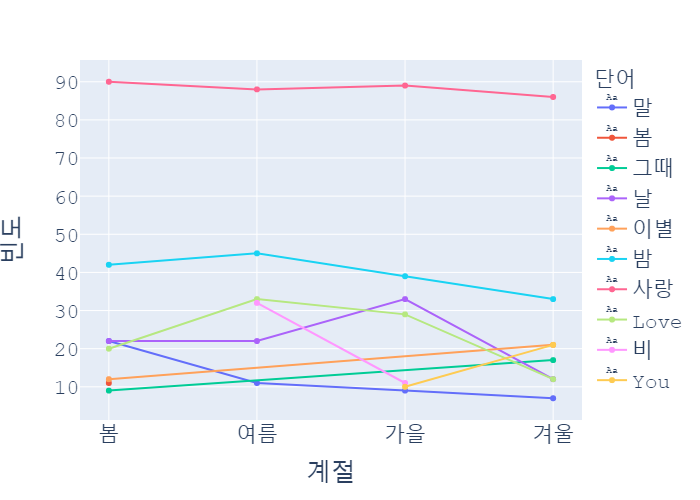
모든 계절에서 '사랑'이라는 단어가 1위를 차지했습니다.
한국인들은 사시사철 사랑을 찾나봐요 ㅋㅋ
봄에 가장 수치가 높고 여름에만 유일하게 살짝 떨어졌다가 가을, 겨울엔 일관적인 수치인 것을 볼 수 있습니다.
반면 'Love'는 다른 계절에 비해 여름이 가장 수치가 높네요.
'밤'과 'Love'의 그래프 형태가 비슷한 것도 눈에 띕니다.
밤과 love는 대체 무슨 관련이 있는걸까요?? 궁금해지네요
수치는 각각 다르지만 '사랑'을 포함해 상위 5개 단어였던 '밤', 'Love', '날', '말'은 사계절 내내 나타났습니다.
'밤'은 여름에 가장 많이 등장했다가 겨울엔 서서히 감소하네요.
밤의 길이가 짧은 만큼 밤을 동경? 그리워하는 부분이 있는 것 아닌가 생각하게 됩니다.
날이 좋은 가을에는 '날'이라는 단어가 급격히 상승합니다.
반면 '봄'이라는 단어는 봄에 등장했다가 사라지고, '그때'라는 단어는 겨울에 등장했다가 사라지네요.
'이별'이라는 단어는 봄과 겨울에만 등장합니다.
사실 봄과 이별은 잘 어울리지 않는다고 생각했는데 꼭 그렇지만도 않나봐요.
'비'라는 단어는 아까 월별 그래프에서도 봤듯이 여름~가을에 걸쳐 나타났습니다.
'비'가 사라지자 'You'라는 단어가 마치 바톤 터치하듯 가을~겨울에 이어서 나타난 것도 흥미롭네요.
5. 느낀점
이렇게 월별, 계절별 노래 제목에 나타난 단어들의 빈도를 시각화하여 살펴봤습니다.
다른 해석 결과도 있을 수 있겠지만 계절에 따라 제목에 들어가는 단어들이 바뀐다는게 신기하고
[사랑, 밤, 날, Love, 말] 이라는 상위 5개 단어가 모두 사계절 내내 등장하는 것도 특이하네요.
2년간의 데이터로 했을때 이런 결과가 나왔지만
10년의 데이터를 가지고 하면 어떤 결과가 나올지도 궁금해지네요.
오늘 포스팅은 여기서 마치겠습니다.
감사합니다.
