- 새롭게 배운 내용
정렬 알고리즘의 종류 ( by 빅오표기법)
- O(n²)의 시간 복잡도 (정렬할 자료의 수가 늘어나면 제곱에 비례해서 증가)
- 버블 정렬(Bubble Sort)
- 선택 정렬(Selection Sort)
- 삽입 정렬(Insertion Sort)
- 퀵 정렬(Quick Sort)
- O(n log n)의 시간 복잡도
- 병합 정렬(Merge Sort)
- 힙 정렬(Heap Sort)
- 부드러운 정렬(Smooth Sort)
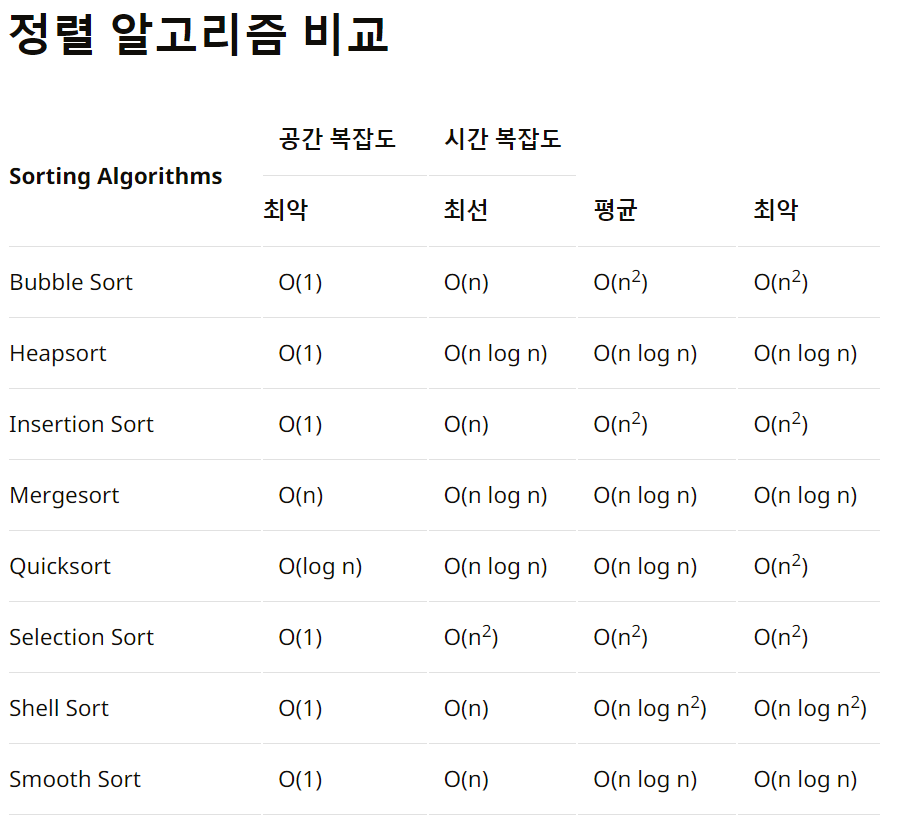
이 중 최악의 시간 복잡도를 '빅 오 표기법' 이라고 함.
출처, 설명: https://velog.io/@jguuun/%EC%A0%95%EB%A0%AC-%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98
이미지 출처: https://blog.chulgil.me/algorithm/
1) 2750번 수 정렬하기
아직 정렬 알고리즘은 사용하지 않고, 파이썬 내장함수인 .sort()를 사용
N = int(input())
ans_list = []
for i in range(N):
x = int(input())
ans_list.append(x)
# 디폴트로 오름차순 정렬을 시행한다.
ans_list.sort()
for i in ans_list:
print(i)2) 2751번 수 정렬하기2 (병합 정렬 merge sort)
위와 같이 내장함수인 sort()를 사용하면 시간 초과가 난다. 하지만 input()과 print 대신 sys.stdin.readline()과 sys.stdout.write를 사용한다면 정답 처리된다.
하지만 주어진 힌트를 활용하여 병합 정렬을 활용해보기로 했다.
import sys
N = int(input())
ans_list = []
for i in range(N):
ans_list.append(int(sys.stdin.readline()))
# 내장 함수인 sorted() 사용
for i in sorted(ans_list):
sys.stdout.write(str(i)+'\n')아래 코드는 병합정렬 알고리즘을 활용함.
재귀함수를 통해 전부 len = 1 짜리 배열로 분할한 후 다시 비교하며 작은수부터 병합해준다.
따라서 시간 복잡도는 분할하는 과정에서 O(logN), 병합 과정에서 O(N)으로 전체 O(NlogN)이 된다.
단, 리스트 슬라이스 [a:b]는 배열의 복제를 발생시켜 메모리 효율은 좋지 않다..!
출처:https://www.daleseo.com/sort-merge/
import sys
N = int(input())
ans_list = []
for i in range(N):
ans_list.append(int(sys.stdin.readline()))
def mergeSort(checkArr):
if len(checkArr) < 2:
return checkArr
# 재귀를 통한 분할 과정
mid = len(checkArr) // 2
front_arr = mergeSort(checkArr[:mid])
back_arr = mergeSort(checkArr[mid:])
# 분할이 끝나면 front와 back으로 분할 된 배열의 0번째 수부터 비교하여 다시 병합
mergedArr = []
l = h = 0
while l < len(front_arr) and h < len(back_arr):
if front_arr[l] < back_arr[h]:
mergedArr.append((front_arr[l]))
l += 1
else:
mergedArr.append(back_arr[h])
h += 1
# 두 배열 중 하나의 배열이 모두 담긴 상황이라면 다른 배열의 나머지 값들도 넣어주기 (이미 정렬됨)
mergedArr += front_arr[l:]
mergedArr += back_arr[h:]
return mergedArr
for j in mergeSort(ans_list):
print(j)3) 10989번 수 정렬하기 3 (계수 정렬 counting sort)
❌❌❌ <1회차 최종 실패! -> 코드 리뷰 및 이해에 초점>
카운팅 정렬, 혹은 계수 정렬은 O(n + k)의 시간복잡도를 가진 정렬이다.
여기서 다소 낯선 k는 정렬을 수행할 배열의 가장 큰 값을 의미한다.
k가 단순히 상수로 취급되어 생략되지 않고 남아있는 것은 그만큼 k에 따라 수행시간에 영향을 미치기 때문이다.
만약 k가 n보다 작다면 정렬의 수행시간은 O(n)이 되겠지만, 무한대로 크다면 정렬의 수행시간도 무한대가 된다.
출처: https://seongonion.tistory.com/130
계수 정렬은 반복되는 원소의 개수를 세어 저장하고 저장한 값에 따라 정렬된 리스트를 만드는 알고리즘이다.
보통 학교 시험 성적과 같이 일정 범위에 분포되며(0~100점) 반복 값이 존재할 때 활용한다.
아래 코드는 계수 정렬을 활용하여 출력하는 코드다. 그러나 메모리 초과가 발생하고 있다...
원인을 찾아본 결과 입력이 최대 천만번 까지 가능하여 반복문 내 append가 있다면 메모리 재할당이 발생하는 등 다양한 원인이 존재했고, 메모리 제한이 8mb이기 때문에 발생한 것이었다.
import sys
N = int(input())
N_list = []
for i in range(N):
x = int(sys.stdin.readline())
N_list.append(x)
# 입력한 배열 원소 중 최댓값 범위 만큼의 개수 리스트 생성 후 개수리스트에 원소 개수 만큼 반영해준다.
count_list = [0] * (max(N_list) + 1)
for n in N_list:
count_list[n] += 1
# 개수 리스트의 원소를 누적합 값으로 갱신 (입력값 배열에 담긴 원소를 바로 정렬된 위치로 삽입하기 위한 사전작업)
for i in range(1, len(count_list)):
count_list[i] += count_list[i-1]
result_list = [0] * (len(N_list))
for n in N_list:
idx = count_list[n]
result_list[idx - 1] = n
count_list[n] -= 1
for k in result_list:
print(k)아래 코드는 위와 같은 오류를 피하고자 입력값의 범위인 10,000을 고려해 array를 미리 생성해주고 그 뒤에 값을 변경하는 방식이다.
설명을 덧붙이자면, 계수 정렬을 해당문제에 최적화하여, 주어진 입력값의 범위라는 힌트를 역이용하여 메모리 사용량을 줄이는 것이다.
import sys
n = int(sys.stdin.readline())
array = [0] * 10001
for i in range(n):
data = int(sys.stdin.readline())
array[data] += 1
for i in range(10001):
if array[i] != 0:
for j in range(array[i]):
print(i)출처: https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=vjhh0712v&logNo=221466898588
4) 2108번 통계학
import sys
N = int(input())
N_list = []
for i in range(N):
x = int(sys.stdin.readline())
N_list.append(x)
# 산술평균 출력
print(round(sum(N_list) / N))
# 중앙값 출력
N_list.sort()
print(N_list[int(len(N_list) / 2)])
# 최빈값 출력
# 계수 정렬의 아이디어를 빌려 반복되는 수를 저장할 리스트를 생성해주고, 이에 값을 담아 활용했다.
# -4000 ~ 4000까지 총 8001개를 담을 리스트 생성 (0도 포함)
count_list = [0] * 8001
for i in N_list:
# 음수는 절댓값을 씌워 인덱스 1~4000 자리에 할당
if i < 0:
count_list[abs(i)] += 1
# 양수는 4000을 더해 인덱스 4001~8000 자리에 할당
elif i > 0:
count_list[i + 4000] += 1
# 0은 인덱스 0자리에 할당
else:
count_list[0] += 1
# 최대 반복수 구하기
maxval = max(count_list)
max_list = []
for i in range(0, len(count_list)):
# 해당 원소가 최대 반복수일 경우 음수, 0, 양수를 따져 max_list에 저장
if count_list[i] == maxval and i <= 4000:
max_list.append(-i)
elif count_list[i] == maxval and i > 4000:
max_list.append(i-4000)
elif count_list[i] == maxval and i == 0:
max_list.append(i)
# 최빈값이 중복된다면 len은 1이 아니기에 가장 작은걸 지우고 그다음 작은걸 출력한다.
if len(max_list) != 1:
max_list.remove(min(max_list))
print(min(max_list))
# 그 외 상황은 최빈값이 하나인 경우, 따라서 그냥 출력
else:
print(min(max_list))
# 범위 출력 (최대 - 최소)
print(max(N_list) - min(N_list))5) 1427번 소트인사이드
N = int(input())
strN_list = []
for i in str(N):
strN_list.append(i)
strN_list.sort(reverse=True)
ans = ''
for i in strN_list:
ans+=i
print(int(ans))6) 11650번 좌표 정렬하기
이차원 배열의 sort()는 내부 배열의 i를 기준으로 오름차순 정렬이 된다.
따라서 해당 문제는 내장함수 sort()의 디폴트 기능으로 해결 가능하다.
출처: https://asxpyn.tistory.com/75
import sys
N = int(input())
# 입력한 좌표를 담아줄 2차원 배열 중 바깥 배열 생성
xy_list = []
for i in range(N):
x, y = map(int, sys.stdin.readline().split())
xy_list.append([x, y])
xy_list.sort()
for j in xy_list:
print(str(j[0]) + ' ' + str(j[1]))7) 11651번 좌표 정렬하기 2
2차원 배열에서 내부 배열의 특정 값을 기준으로 정렬하는 방법은
.sort(key = lambda x: (x[i]))
특정 값 (i번째 원소)을 기준으로 오름차순 정렬된다.
.sort(key = lambda x: (x[i], x[j]))
만약 i번째 인덱스의 값이 같을 경우 뒤에 있는 j번째 인덱스를 기준으로 정렬한다.
.sort(key = lambda x: (-x[i]))
이 때 괄호 안의 x에 -를 붙이면 내림차순으로 정렬된다.
import sys
N = int(input())
xy_list = []
for i in range(N):
x, y = map(int, sys.stdin.readline().split())
xy_list.append([x, y])
# 내부 배열의 1번째 값으로 정렬하고 같을 시 0번째 값으로 정렬
xy_list.sort(key = lambda x: (x[1], x[0]))
for j in xy_list:
print(str(j[0]) + ' ' + str(j[1]))8) 1181번 단어 정렬
처음엔 sort 함수로 문자열 길이 정렬만 수행하고 길이가 같은 경우 반복문을 통해 비교하여 정렬하려고 했으나, 시간 초과가 발생했다.
import sys
N = int(input())
words = []
for i in range(N):
word = sys.stdin.readline().split()
words.append(word[0])
words = set(words)
words = list(words)
words.sort(key = lambda x: (len(x)))
for j in range(0,len(words)):
for idx in range(1,len(words)):
if j + idx > len(words) - 1:
continue
if len(words[j]) == len(words[j+idx]):
for k in range(len(words[j])):
if words[j][k] == words[j+idx][k]:
continue
else:
if ord(words[j][k]) > ord(words[j+idx][k]):
words[j], words[j+idx] = words[j+idx], words[j]
break
for t in words:
print(t)이 후 sort에 조건 x 를 추가하여 디폴트 기능으로 답을 얻긴 했으나 반복문의 시간 복잡도를 줄이는 방향도 공부해야겠다.
import sys
N = int(input())
words = []
for i in range(N):
word = sys.stdin.readline().split()
words.append(word[0])
words = set(words)
words = list(words)
# x를 추가해줌으로써 길이가 같을 경우 사전식 정렬이 이뤄진다. 정말 간편한 기능이다.....
words.sort(key = lambda x: (len(x), x))
for t in words:
print(t)9) 10814번 나이순 정렬
import sys
N = int(input())
clients = []
idxclients = []
for i in range(N):
client = list(map(str, sys.stdin.readline().split()))
clients.append(client)
# 입력된 순서(인덱스)까지 담아주는 리스트
for j in enumerate(clients):
idxclients.append(j)
# 첫번 째로 나이를 int로 형변환하여 비교하고, 두번 째로 enumerate에서 저장한 순서로 비교한다.
idxclients.sort(key=lambda x: (int(x[1][0]), x[0]))
for k in idxclients:
print(k[1][0] + ' ' + k[1][1])10) 18870번 좌표 압축
첫 시도에서 반복문 안에 .index() 함수는 O(N^2)의 복잡도를 가져 시간초과가 발생했다. 따라서 N(1) 복잡도를 갖는 딕셔너리를 활용해야함을 배웠다!!
import sys
N = int(input())
nums = list(map(int, sys.stdin.readline().split()))
ans_list = [0] * len(nums)
ranks = list(set(nums))
ranks.sort()
for i in range(len(nums)):
rank = ranks.index(nums[i])
ans_list[i] = rank
for k in range(len(ans_list)):
if k == (len(ans_list) - 1):
sys.stdout.write(str(ans_list[k]))
else:
sys.stdout.write(str(ans_list[k]) + ' ')import sys
N = int(input())
nums = list(map(int, sys.stdin.readline().split()))
ranks = sorted(list(set(nums)))
# 딕셔너리 선언: 반복문을 활용하여 쉽게 저장할 수 있다.
ranksDict = {ranks[i] : i for i in range(len(ranks))}
for i in nums:
print(ranksDict[i], end=' ')