📝 발표 자료에 CNN 돌려본 것을 넣어야 할 것같아서 내가 임의로 생성한 데이터 셋말고, 데이터셋 팀원들이 제공해준 데이터 셋으로 다시 진행하려고 한다. 그러다가 의문점이 생겼다.
❓의문점
- 기존에는 데이터 셋에는 train data, test data 2가지만 존재하는 줄 알고 cnn을 진행했는데, 회의를 통해서 train data, test data, validation data 3종류의 데이터가 필요하다는 것을 인지했다. 그러면서 든 생각은 그러면 내가 진행했던 cnn에서 test data는 과연 test data로 이용된 것이 맞았나..? 라는 의문이 들어서 다시 코드를 살펴보았다.


- 변수명은 사실 참고하던 서적의 코드와 동일하게 진행했는데, 내가 test data 구나~ 하고 진행했던 부분의 변수가 valid 라고 적혀있어서 혼란스러웠다. 하지만 서적에 적혀있는 파일의 이름 또한 'test' 였기에 진행할 당시에는 validation data가 test data랑 똑같구나! 하고 진행했었던 것같다. 그래서 다시 검색을 했는데..


-
test data와 validation data의 차이는 팀원들의 자료조사를 통해 인지했지만, 막상 코드를 보니 다시,, 원점으로 돌아간 기분이다.
‼️ 해결
내가 진행한 부분은 test data가 아닌 validation data였다. 사실 조금 멍청한 의문이었던건,, 모델을 만들때 넣어주는 data인데 왜 test data라고 생각했는지 모르겠다. 당연히 모델을 학습을 시키는 과정에서 넣어준 데이터인데 왜 test data라고 생각했을까? 모델이 완성된 이후에 test data를 이용해서 모델을 평가하는 것!!
✅ 데이터 셋의 양이 그렇게 많지 않아 validation을 따로 구성하지 않았는데, 그럼 바로 돌려야하는 경우엔 어쩌지?
✔️ 교차 검증을 사용하자 == 준비해놓은 test data를 validation data로 사용하자.
📌교차검증
교차 검증은 train data를 train data+validation data로 분리한뒤, validation data를 사용해 검증하는 방식이다.
보통은 train data로 모델을 훈련하고, test data로 모델을 검증한다. 여기에는 한가지 약점이 존재하는데, 고정된 test data를 통해 모델의 성능을 검증하고 수정하는 과정을 반복하면, 결국 내가 만든 모델은 test data에만 잘 동작하는 모델이 된다. 이를 해결하고자하는 것이 '교차 검증' 이다.
📝 현재까지 구축해놓은 데이터셋을 이용하여 CNN 다중분류를 수행했다.
코드는 이전에 진행하던 CNN 다중분류와 동일하므로 코드 리뷰는 하지 않겠다.
[안녕하세요, 괜찮습니다,기다리다 3가지 단어 CNN 학습 - 변경된 data set 이용]
- 다중 분류(categorical)
- 데이터 셋 구성 : train data= 3frame 당 1장으로 1470개, validation data 630개의 데이터로 구성
- 정확도 : training accuracy는 100%, validation accuracy는 52%
- 테스트 정확도 (test data==validation data) : 52%
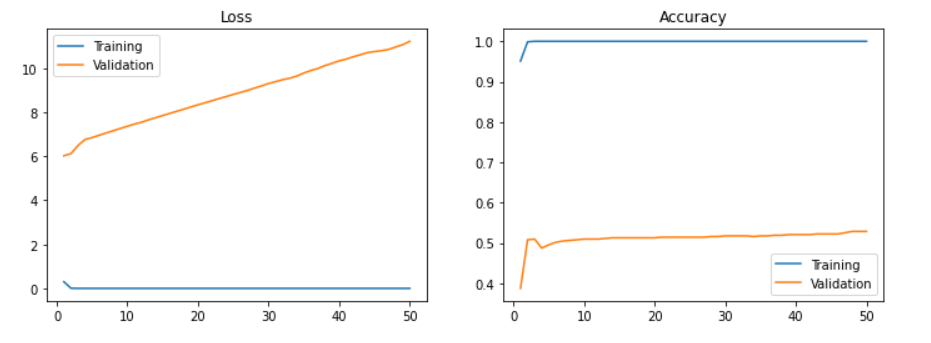
- train data에 대한 accuracy는 높지만, validation data에 대한 accuracy는 낮은 것을 보아 과적합(overfitting)이 발생한 것을 알 수 있었다. 이는 아마 데이터 셋의 부족때문이지 않을까 싶다.
📌 3frame? 1frame?
위 모델은 데이터 셋이 영상 3frame 당 1장으로 생성된 데이터 셋이다. 우리가 왜 3 프레임당 1장을 썼는지에 대해 설명하기 위해 1frame 당 1장도 진행하였다.
- 3frame으로 하는 다른 이유 : 모든 프레임을 추출하는 것이 아니라 특정 프레임 추출만으로 경제적이고 유의미한 데이터 셋을 구성하고 싶었다. 따라서 그 기준점에 대해 고민하던 중, 교수님과의 면담을 통해서 애니메이션 프레임에서 아이디어를 얻었다.
일본 애니메이션의 경우 초당 24장으로 구성된 풀 프레임 애니메이션보다 낮춘 초당 8에서 12초의 프레임으로 구성되는데, 동작에 있어 큰 어색함을 느끼지 못한다.
수어 동작의 경우, 역동적인 동작들이 아니기 때문에 1초에 8에서 12프레임 사이라면 충분히 동작을 표현할 수 있을 것이라 판단했다.
따라서 중간 값인 1초에 10프레임을 기준으로 잡았고, 초당 30초로 통일된 수어 영상에서 3프레임 당 1장을 추출하였다.
아주 초기에 1frame 당 1장, 5frame 당 1장을 진행했을때, 정확도에서 많은 차이가 없어서 1frame 당 1장이 데이터가 많음에도 불구하고 정확도가 더 높아지진 않는구나! 하고 판단했었다.
그렇기 때문에 나는 3frame 당 1장의 결과와 별반 다른 점이 없을거라고 예상했다.
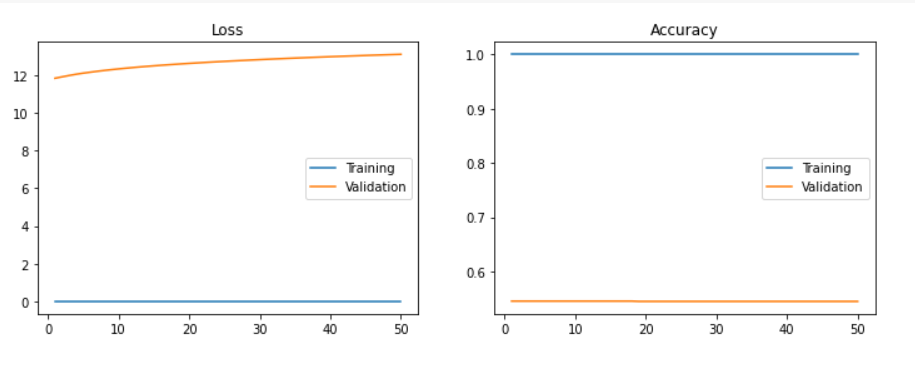
- 하지만 과적합이 더 심하게 진행된 모습을 볼 수 있었다..
- 팀원들과 상의를 통해 일단은 우리가 3frame 당 1장을 쓴 이유로는 적합하지 않다고 판단하여 발표에서는 빼게 되었고, 유사한 이미지가 더 많아서 과적합이 일어났나? 라는 의견도 나왔다.
- 이 부분에 대해서는 더 많은 조사가 필요해보인다.

FE Programmer