
📝Carrotww의 코딩 기록장
🧲 Programmers 뒤에있는 큰 수 찾기 - Level2
🔍 Programmers 뒤에있는 큰 수 찾기 - Level2
stack 문제이다. 최근에 stack문제를 많이 접했어서 빠르게 풀었다.
def solution(numbers): result = [-1 for _ in range(len(numbers))] stack = [] for index, val in enumerate(numbers): while stack and stack[-1][1] < val: result[stack.pop()[0]] = val stack.append((index, val)) return result뒤에 숫자가 stack에 있는 숫자보다 크다면 계속 반복하면서 result의 index 자리를 큰 수로 채우는 방식이다.
🧲 Programmers 인사고과 - Level3
🔍 Programmers 인사고과 - Level3
오래걸렸다.
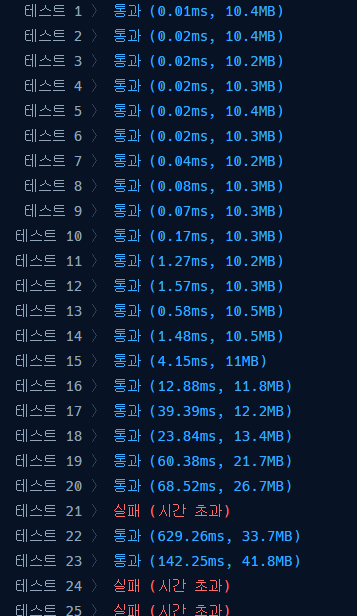
여러번 다른 방법으로 풀이하였는데 틀리고, 3개가 시간초과나고 쉬워보였지만 O(n2)의 시간복잡도를 O(n)으로 어떤 방식으로 해결하느냐가 관건인 문제다.첫 번째 풀이는 오답이 너무 많아서 빼고 시간초과 난 문제
- 시간초과 풀이
def solution(scores): from collections import defaultdict result = 0 a, b = scores.pop(0) total_score = a + b rank = defaultdict(list) # score 를 돌며 rank dict에 key - 총 점수, val - list를 넣어준다. for score in scores: temp_score = score[0] + score[1] rank[temp_score].append(score) # 그나마 시간을 줄이고자 생각한 방법인데 # 비교 대상인 compare_score 리스트는 큰 수대로 내림차순 정렬을 하였다. # 지금보니 굳이 scores 리스트는 정렬하지 않아도 됐을것같다. scores.sort(key=lambda x: x[0]+x[1]) compare_score = sorted(scores, key=lambda x: x[0]+x[1], reverse=True) # 앞에서 빼두었던 주인공의 점수를 확인하고 인센티브를 받지 못한다면 -1을 리턴해준다. for temp in compare_score: t_a, t_b = temp[0], temp[1] if a < t_a and b < t_b: return -1 # 이 부분에서 시간초과가 난 것 같다. # O(n)으로 개선이 필요하다. for score in scores: s_a, s_b = score[0], score[1] for temp in compare_score: t_a, t_b = temp[0], temp[1] if s_a < t_a and s_b < t_b: rank[s_a + s_b].remove(score) break # 주인공보다 점수가 클때 result에 해당 사람들 인원을 더하고 # 최종으로 +1 하여 등수를 리턴한다. for ra in rank: if ra and ra > total_score: result += len(rank[ra]) return result + 1
이중 for문을 사용하여 시간초과가 났다.
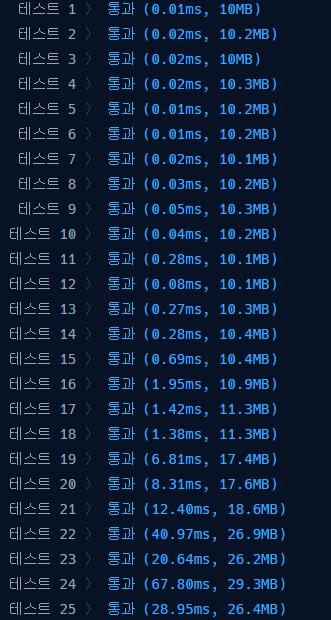
- 개선된 정답 풀이
def solution(scores): from collections import defaultdict result = 0 a, b = scores.pop(0) total_score = a + b rank = defaultdict(int) # 개수만 세면 되기 때문에 list말고 int defaultdict로 만들어주었다. # 처음 풀이에서 사용하였던 remove() 함수의 사용을 없애기 위함이다. scores = list(filter(lambda x: sum(x) > total_score, scores)) # 주인공이 몇 등인지만 구하면 되기 때문에 # 주인공보다 점수가 높은 사람들의 리스트를 만들어주었다. for score in scores: s_a, s_b = score if a < s_a and b < s_b: return -1 rank[sum(score)] += 1 # 위와 같은 방식이며 리스트를 저장하지 않고 해당 key 값에 value를 1씩 증가시켰다. scores.sort(key=lambda x: (x[0], -x[1]), reverse=True) # 이 부분이 제일 중요한데 # a 점수로 내림차순 정렬을 하고 같은 a 점수들 중에서는 b 점수가 낮은 점수로 오름차순 # 정렬하였다. # ex) (4, 3) (4, 4) (4, 5) (3, 3) (3, 5) (3, 6) # a 점수는 내림차순 이기 때문에 뒤 index 의 사람들은 당연히 a 점수가 앞 사람보다 # 작을 것이고 b 점수를 max 값으로 갱신해주면서 뒷 사람이 b_max 보다 작으면 # a, b 모든 점수가 작은 것이기 때문에 rank에서 해당 점수 사람을 제거하였다. max_b_score = 0 for score in scores: s_a, s_b = score if s_b < max_b_score: rank[sum(score)] -= 1 else: max_b_score = max(s_b, max_b_score) for ra in rank: result += rank[ra] # 주인공보다 높은 사람들의 점수만 담은 rank 이기 때문에 조건문을 걸어줄 필요도 없다 return result + 1
확실히 매일 하니까 느는것 같다...!

Carrot_hyeong