0. 들어가며
스레드 동기화(thread synchronized)는 하나의 자원에 대해 많은 기능들이 접근해야할때 반드시 알아야 하는 기능입니다.
스레드는 프로세스의 최소 작업단위이며 동기화는 프로세스, 스레드 들이 수행되는 시점을 조절하여 공유하는 정보를 일치시키는 작업을 의미합니다
이 둘의 개념 및 예제에 대해서 공부를 진행해 보겠습니다
0.1 스레드 동기화란 ?
스레드 동기화는 멀티스레드 환경에서 여러 스레드가 하나의 공유자원에 동시에 접근하지 못하도록 막는것을 말합니다. 공유데이터가 사용되어 동기화가 필요한 부분을 임계영역(critical section)이라고 부르며, 자바에서는 이 임계영역에 synchronized 키워드를 사용하여 여러 스레드가 동시에 접근하는 것을 금지함으로써 동기화를 할 수 있습니다.
다시 말해, 싱글 스레드 프로세스라면, 공유 데이터에 단 하나의 스레드만이 접근하므로 문제가 될 것이 없습니다. 하지만, 멀티 스레드 프로세스의 경우, 두 개 이상의 스레드가 공유 데이터에 동시에 접근하게 되면 예상과 벗어난 결과가 타나날 수 있습니다.
이러한 문제를 해결해 주는 것이 바로 스레드 동기화입니다.
1.1 synchronized 사용법
synchronized 키워드는 동기화가 필요한 메소드나 코드블럭앞에 사용하여 동기화 할 수 있습니다. synchronized로 지정된 임계영역은 한 스레드가 이 영역에 접근하여 사용할때 lock이 걸림으로써 다른 스레드가 접근할 수 없게 됩니다. 이후 해당 스레드가 이 임계영역의 코드를 다 실행 후 벗어나게되면 unlock 상태가 되어 그때서야 대기하고 있던 다른 스레드가 이 임계영역에 접근하여 다시 lock을 걸고 사용할 수 있게 됩니다.
lock은 해당 객체당 하나씩 존재하며, synchronized로 설정된 임계영역은 lock 권한을 얻은 하나의 객체만이 독점적으로 사용하게됩니다.
1) 메소드에 synchronized 설정하기
메소드 이름 앞에 synchronized 키워드를 사용하면 해당 메소드 전체를 임계영역으로 설정하실수 있습니다.
synchronizedvoidincrease() {
count++;
System.out.println(count);
}2) 코드블럭에 synchronized 설정하기
동기화를 많이 사용하게 되면 효율이 떨어지게 되므로 꼭 필요한 부분에만 블럭을 지정하여 임계영역으로 설정하실 수 있습니다. 예제와 같이 synchronized(this)로 지정하게 되면 참조변수(this) 객체의 lock을 사용하게 됩니다.
voidincrease() {
synchronized(this) {
count++;
}
System.out.println(count);
}1.2 synchronized 예제
public class HelloSync {
public static void main(String[] args) {
StringDisplay sd = new StringDisplay();
MyThread[] mts = new MyThread[5];
for (int i=0; i<mts.length; i++) {
mts[i] = new MyThread(sd, Integer.toString(i));
mts[i].start();
}
}
}
class StringDisplay {
synchronized void display(String s) {
for (int i=0; i<5; i++) {
System.out.print(s);
}
System.out.println("");
}
}
class MyThread extends Thread {
StringDisplay sd;
String s = "";
public MyThread(StringDisplay sd, String s) {
this.sd = sd;
this.s = s;
}
@Override
public void run() {
sd.display(s);
}
}synchronized
- display 메소드에 synchronized 키워드를 사용하여 여러개의 스레드가 잠금을 통해 권한을 얻고 메소드를 실행할 수 있도록 하여 예상하는 결과를 얻는 것이 목표입니다
코드 work flow
main메서드가 실행됩니다.StringDisplay객체sd가 생성됩니다.MyThread객체 배열mts가 생성됩니다.- 반복문을 통해
mts배열의 각 요소에 대해 다음 작업을 수행합니다:i값을 문자열로 변환하여MyThread객체를 생성합니다.MyThread객체의start()메서드를 호출하여 해당 스레드를 실행합니다.
MyThread의run()메서드가 실행됩니다.MyThread객체의sd변수는StringDisplay객체를 참조합니다.MyThread객체의s변수는 생성 시 전달된 문자열을 가지게 됩니다.sd.display(s)메서드를 호출합니다.display()메서드는synchronized키워드로 동기화되어 있으므로, 해당 객체의 잠금을 획득합니다.display()메서드에서 반복문을 통해s문자열을 5번 출력합니다.display()메서드가 종료되고 잠금이 해제됩니다.MyThread의run()메서드가 종료됩니다.- 이전 단계로 돌아가, 다음
MyThread객체의run()메서드를 실행합니다. - 위 단계들을
mts배열의 모든 요소에 대해 반복합니다. main메서드의 실행이 종료되고 프로그램이 종료됩니다.
여기서 주의깊게 봐야할 점은 9-13 라인입니다
동기화가 되어있으므로 객체의 잠금을 얻는다 라는 말이 핵심입니다
이로써 각 thread 객체들은 display 메소드를 동시에 실행할 수 없습니다
위 코드의 결과는 아래와 같습니다
(매번 실행시 결과는 다를 수 있음)
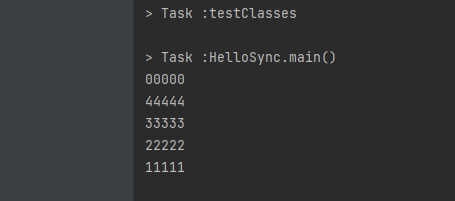
5개의 mythread 객체가 생성되며 start() 호출을 통해 display 메소드를 실행하게 되며
만약 동기화를 사용하지 않는다면
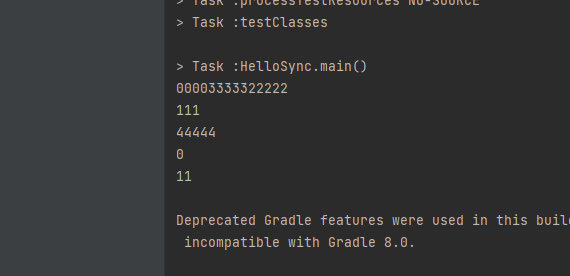
와 같이 순서가 엉망이 되어버리는 현상을 볼 수 있습니다
결과적으로 각 Thread는 display 메서드를 호출하여 문자열을 5번 출력하고 이를 5개의 스레드가 동시에 실행합니다
이때 synchonized 키워드를 사용함으로써 임계구역에 대한 동기화가 이루어지며, 여러 스레드가 동시에 임계구역에 접근하는 것을 방지하여 출력 결과가 의도한 대로 진행되는 것입니다
위와 같이 예상치 못한 결과를 얻는 이유에 대해서 살펴보겠습니다
2.1 JVM 최적화 및 실행 과정
JVM의 최적화 및 실행 과정과 관련이 있습니다. JVM은 코드를 해석하고 실행하기 위해 Bytecode Interpreter와 JIT(Just-In-Time) 컴파일러를 사용합니다.
- Bytecode Interpreter:
- Bytecode Interpreter는 Java 바이트코드를 한 줄씩 해석하고 실행합니다.
- 스레드는 각자의 인터프리터를 가지며, 인터프리터는 해당 스레드의 PC(Program Counter)를 추적합니다.
- 인터프리터는 임계구역에 진입할 때마다 해당 메서드의 라이브러리 코드를 재진입하고, 로컬 변수 테이블과 스택 프레임을 새로 초기화합니다.
- JIT 컴파일러:
- JIT 컴파일러는 인터프리터로부터 반복적으로 실행되는 코드를 감지하고, 해당 코드를 기계어로 컴파일하여 최적화된 형태로 실행합니다.
- JIT 컴파일러는 메서드 단위로 최적화를 수행합니다.
2.2 JVM 컴파일과정
- javac 가 .java 파일을 .class 파일로 만든다
- jvm이 class 파일을 로드하며 해당 아키텍처(cpu)에 맞기 머신 코드로 컴파일 한다
- 컴파일된 함수를 class와 연관시켜 class의 method가 호출될 때 compile된 machine code를 실행시킨다
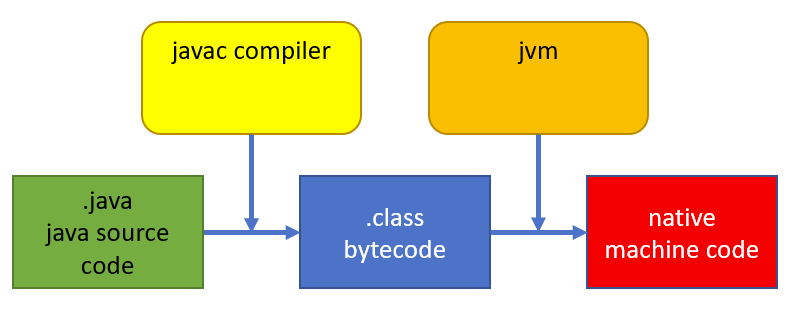
하지만 .class 파일을 실행할때 바로 jvm이 머신코드로 컴파일 하지 않는다.
먼저 bytecode interpreter를 이용해서 bytecode를 실행한다 전체 단 한번 실행되는 코드처럼 굳이 컴파일 할 이유가 없는 바이트 코드를 컴파일하게 되면 시간적 비용이 비효율적으로 소모되기 때문이다. 하지만 여러번 실행을 거치며 해당 코드가 많이 실행되는 코드라고 판단되면(Warmed Hot) 그제서야 JIT-Compiler를 이용하여 컴파일을 진행한다.

여기서 JIT 컴파일러와 Bytecode Interpreter의 작동방식으로 인하여 다음과 같은 문제가 발생할 수 있습니다
- JIT 컴파일러의 최적화:
- JIT 컴파일러는 반복적으로 실행되는 코드를 최적화하기 위해 추적합니다.
- 이 때, 임계구역의 코드가 최적화 대상이 될 수 있습니다.
- 최적화된 코드는 순서나 재진입 시의 동작이 예상치 못한 결과를 가져올 수 있습니다.
- JIT 컴파일러와 인터프리터의 혼용:
- JIT 컴파일러가 동작하는 동안, 인터프리터도 함께 동작합니다.
- 이는 최적화된 코드와 인터프리터가 혼재하여 임계구역 접근 제어를 어렵게 만들 수 있습니다.
- 예를 들어, 최적화된 코드를 실행하는 도중 인터프리터로 전환되면서 임계구역 접근이 동기화되지 않을 수 있습니다.
- 컴파일러 최적화와 hoisting:
- JIT 컴파일러는 코드를 최적화하기 위해 hoisting 기법을 사용할 수 있습니다.
- hoisting은 반복문 안에서 반복적으로 실행되는 코드를 반복문 밖으로 옮기는 최적화 기법입니다.
- 이 때, 임계구역 관련 코드가 hoisting되면 임계구역 접근 제어가 제대로 이루어지지 않을 수 있습니다.
이러한 이유로 명확하게 synchronized 키워드를 사용하지 않으면 JVM 의 최적화 및 실행과정중에서 예상치 못한 결과를 얻을 수 있습니다.
따라서 임계구역에 대한 안전한 접근을 보장하며 코드를 작성하는 것이 중요합니다
