어텐션 매커니즘은 기계번역 분야에서 활발히 활용되는 seq2seq 모델의 단점을 개선한 기법이다.
seq2seq 개념
- 인코더가 레이어를 거치면서 입력 시퀀스의
context vector를 추출 - 디코더가
context vector를 활용해 출력 시퀀스 생성
seq2seq의 문제점
- 고정 크기 벡터에 모든 정보를 압축
👉 입력 시퀀스 길이가 길어질 수록 정보 손실 발생 - RNN을 사용
👉 기울기 소실 발생
Attention
- 디코더가 출력 단어를 예측할 때마다 인코더에서의 전체 입력 문장을 다시 한 번 참고하되 전체 문장을 일률적으로 참고하는 것이 아니라 예측해야할 단어와 연관이 깊은 단어에 더 집중해서 참고한다.
 출처 : https://blog.floydhub.com/attention-mechanism/
출처 : https://blog.floydhub.com/attention-mechanism/
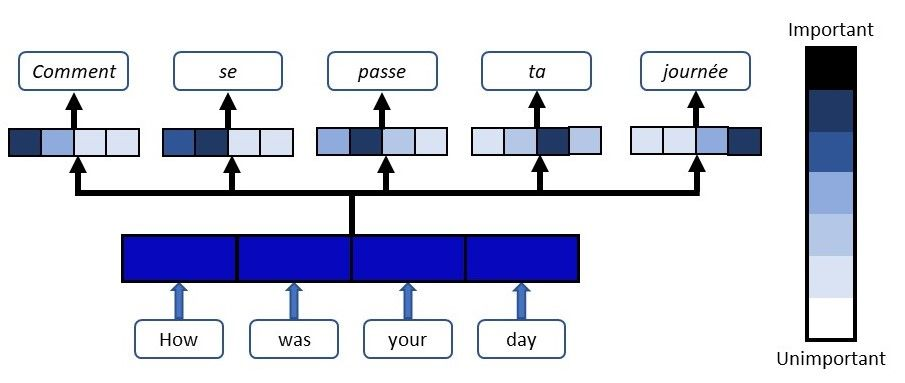
위의 이미지를 보면 입력 시퀀스로 How was your day가 들어왔을 때
어떻게에 맞는 단어를 예측하는 경우 전체 입력 시퀀스 중 How was에 대한 정보를 더 집중해서 보고, 단어 하루를 예측하는 시점에서는 전체 입력 시퀀스 중 your day를 집중해서 보는 것을 확인할 수 있다.
Attention Value 구하기
Attention(Q,K,V)=Attention Value
 출처 :
출처 : - 인코더의 시점 별로
hidden state구하기 - 이전 시점 디코더의
hidden state와 인코더의 각 시점 별hidden state를 내적해서 어텐션 스코어 구하기cf) 어텐션 스코어를 구하는 방법에는 여러 종류가 있다. 그 중
dot-product방식을 차용해 구해본다. - 어텐션 스코어들을
softmax로 거쳐 어텐션 분포 구하기 - 어텐션 분포에 해당하는 각
hidden state곱하기 - 가중치 부여된 벡터들을 더해서 최종
context vector만들기
👉Attention Value!
Attention 으로 학습
- 각 시점의 디코더는 이전 시점 디코더의 출력과
hidden state와 함께 앞서 만든Attention Value를 함께 입력으로 받아 예측 벡터를 얻어낸다.
References
