구글 사이트에서 이미지를 검색하고 검색한 이미지를 저장하는 프로그램
크롬 드라이버 자동으로 설치하는 코드
다음 코드를 이용해 크롬 드라이버를 설치하였다.
from webdriver_manager.chrome import ChromeDriverManager
from selenium import webdriver
driver = webdriver.Chrome(ChromeDriverManager().install())
URL='http://www.google.co.kr/imghp'
driver.get(url=URL)
driver.implicitly_wait(time_to_wait=10)구글 상에서 이미지 크롤링 (1)
from selenium.webdriver.common.keys import Keys # 키입력 라이브러리
from selenium.webdriver.common.by import By # CSS선택 라이브러리
#검색창 원소를 selector로 찾아 클릭하여 바다를 검색한다.
elem = driver.find_element(By.CSS_SELECTOR, "body > div.L3eUgb > div.o3j99.ikrT4e.om7nvf > form > div:nth-child(1) > div.A8SBwf > div.RNNXgb > div > div.a4bIc > input")
elem.send_keys("바다")
elem.send_keys(Keys.RETURN)구글 상에서 이미지 크롤링 (2)
결과더보기 버튼을 눌러 사진을 추가적으로 더 보기 위한 코드이다.
import time
elem =driver.find_element(By.TAG_NAME, "body")
for i in range(60):
elem.send_keys(Keys.PAGE_DOWN)
time.sleep(0.1)
try:
#'결과 더보기' 버튼의 원소를 selector로 찾아 클릭한다
driver.find_element(By.CSS_SELECTOR, '#islmp > div > div > div > div > div.gBPM8 > div.qvfT1 > div.YstHxe > input').click()
for i in range(60):
elem.send_keys(Keys.PAGE_DOWN)
time.sleep(0.1)
except:
pass- 사진 3개를 무작위로 뽑아보았을 때 다음과 같다
#islrg > div.islrc > div:nth-child(793) > a.wXeWr.islib.nfEiy > div.bRMDJf.islir > img
#islrg > div.islrc > div:nth-child(777) > a.wXeWr.islib.nfEiy > div.bRMDJf.islir > img
#islrg > div.islrc > div:nth-child(755) > a.wXeWr.islib.nfEiy > div.bRMDJf.islir > img
'div:nth-child(숫자)' 부분을 'div'로 변경하면 모든 사진을 선택 할 수 있다
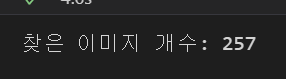
이미지의 개수 알아보기
links=[]
#이미지의 원소를 모두 찾는다
images = driver.find_elements(By.CSS_SELECTOR, "#islrg > div.islrc > div > a.wXeWr.islib.nfEiy > div.bRMDJf.islir > img")
for image in images:
if image.get_attribute('src') is not None: #링크 주소가 없으면 이미지가 없는 것 이므로 실행하지 않는다
links.append(image.get_attribute('src')) #이미지의 다운로드 링크 주소를 links 리스트에 추가한다.
print('찾은 이미지 개수: ', len(links)) #links 리스트의 길이 = 이미지의 개수결과
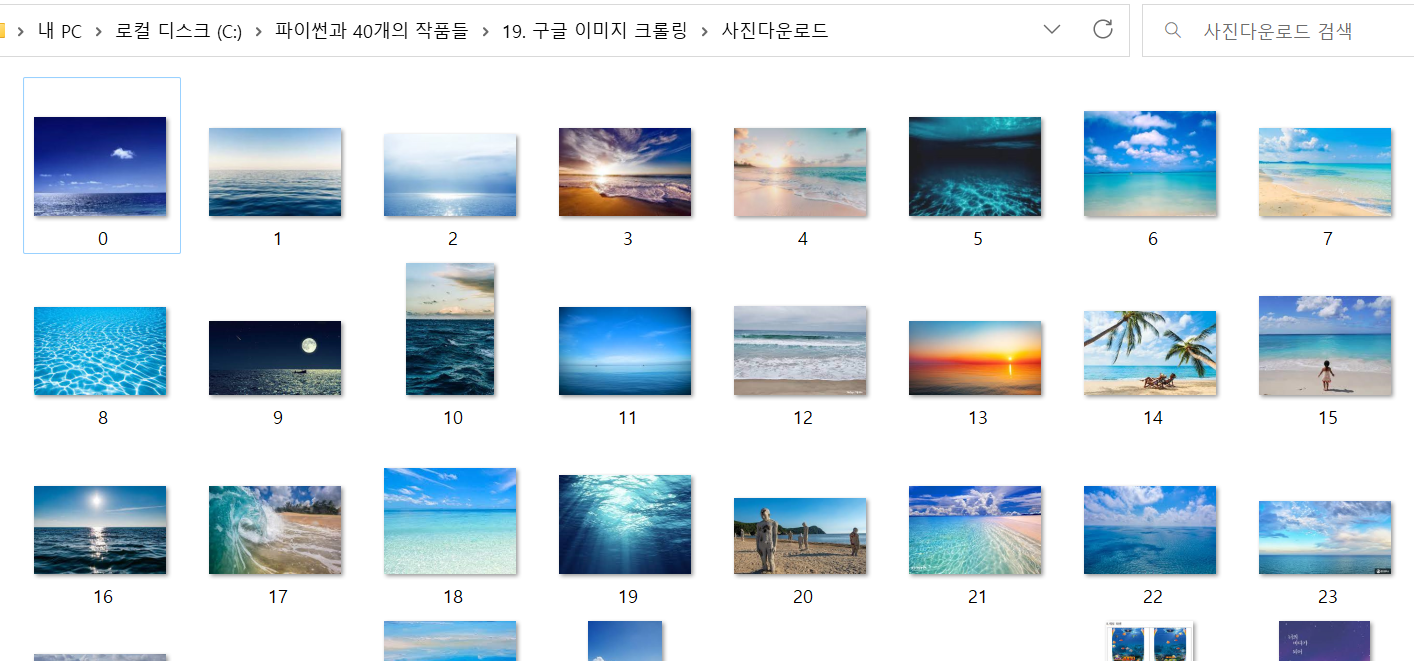
크롤링한 이미지 다운로드
찾은 사진들을 [사진다운로드] 폴더 안에 다운로드 한다
import urllib.request
for i,k in enumerate(links):
url = k
urllib.request.urlretrieve(url, "C:\\파이썬과 40개의 작품들\\19. 구글 이미지 크롤링\\사진다운로드\\"+str(i)+".jpg")
print('다운로드 완료')결과