고객사에 나가서 트러블 슈팅을 해보면서 느낀 점이 서버, 인프라에 대한 모니터링이 중요하다는 것이다. 배우는 입장이고 테스트하는 입장에서는 느끼지 못했던 부분이다. 인프라를 모니터링 하기 위해서는 어떤 것들을 고려해야하는지 구글링해보면서 나름대로 정리해보았다.
우선, 토스의 서버 인프라 모니터링 세션을 들으면서 요약한 내용이다. 줄 글을 읽기 전에 가볍게 시청하기 좋은 것 같다. 영상링크
왜 k8s Istio 인가?
토스는 마이크로 서비스를 운영하고 있었고 기존에 VAMP(뱀프, 서비스 디스커버리를 담당하는 API Gateway 컴포넌트)와 DC/OS(컨테이너 오케스트레이션 엔진)을 사용하고 있었다.
이때, 운영 코스트가 높아지면서 서비스 디스커버리의 한계를 경험했다고 한다. 그래서 변화하게 된 것이 Istio, K8s 기반의 시스템이다. 여담으로 마이그레이션 기간은 active-active IDC가 전환되기 까지 9개월이 걸렸다고 한다.
기존에는 influxdb와 telegraf로 모니터링을 하고 있었다. 이를 Istio, K8s 기반으로 변화시키면서 prometheus, thanos(운영의 편리성을 도와주었다고 한다. 후술 하겠지만 분산화된 프로메테우스를 관리하기 편하게 도와준다.)를 메인 모니터링 시스템으로 자리잡게 되었다.
쿠버네티스로 변화하면서 가장 부각되었던 점은 서비스 디스커버리였다. VAMP API Gateway를 운영할 때에는 VAMP가 장애가 나면 전면 장애로 전파가 되었는데, 서비스 메쉬는 분산 API Gateway로 서버side 로드밸런싱이 아니라 스스로 밸런싱하는 클라이언트side 로드밸런싱이다 보니까 하나의 API Gateway에서 장애가 발생하더라도 그 영향이 적었다. 또한 사이드카 패턴(사이드카 패턴이란?)으로 서비스의 인바운드 아웃바운드 트래픽까지 통제권을 가질 수 있기 때문에 서비스 로직에서 네트워크 구성에 대한 고려(mtls-클라이언트와 서버간에 상호인증, 서킷 브레이커-MSA의 회복 패턴에 한 종류, 리트라이 로직-코드 레벨에서 재시도를 통해 회복성을 개선하는 방법)할 필요 없이 어플리케이션 코드에서 분리할 수 있었다. 네트워크를 전체적으로 오케스트레이션할 수 있는 점이 장점라고 한다.
보통 오류 로그를 발견해 서비스 이슈 발생 여부를 알게 되는데, 이 로그를 활용해 발견할 수도 있지만 로직이 복잡하거나 트랜잭션이 길 경우 파악이 잘 안된다.
트러블 슈팅에는 메트릭이 원인 규명에 도움이 된다. 전체적인 트랜잭션 로그를 확인하고 어느 어플리케이션에서 문제가 있었는지 확인하고 이후 네트워크 및 어플리케이션이 실행된 머신에 이슈가 있었는지 확인한다.
Application Layer Metric
토스의 경우스프링 프레임워크관련 매트릭이 주를 이루었고 사일로의 필요에 따라 node, python, Golang 메트릭을 지원하였다.오류와 가장 상관관계가 높은 메트릭이라고 할 수 있다.
JVM 메트릭이나톰켓 메트릭,JPA 메트릭등을 계속 모니터링 해왔다. 여기서 특이한 사항이 없다면 네트워크를 주의 깊게 살펴보았다.
Network Layer Metric
기본적으로 서비스와 서비스 간의 통신을 보게 되고 극단적인 케이스에선 요청 자체가 ingress로 들어오지 못해 큰 장애가 날 수 있기 때문에모든 네트워크 패널이 정상적인지 알려줄 가시성도 확보하게 된다.
OS Layer Metic
로깅과 tracing을 해보았을 때가장 상관관계가 낮기때문에 마지막에 판단할 근거를 제시하게 해준다.
서비스 메쉬를 사용하면서 네트워크 제어권을 획득하면서 네트워크 메트릭 정보가 더욱 풍부해졌다. 서비스 간 통신에서 어떤 source 어플리케이션이 destination 어플리케이션의 어떤 버전으로 요청을 넣었고, 소스의 어떤 버전의 어플리케이션이 요청을 넣었는지 알 수 있게 되었다.
reporter라는 속성으로 source와 destination이 다른 응답으로 처리되는 경우도 인지할 수 있다. 추가적으로 response_flags라는 지표를 활용할 수 있게 되었는데, 이 지표는 하나의 요청 flow에서 upstream, downstream 사이에서 어떤 비정상적인 현상이 있었는지 파악하는데 도움이 되었다고 한다.
서비스 디스커버리 이슈로도 문제가 발생할 수 있는데 클라이언트 side 방식으로 로드밸런싱을 하다 보니까 서비스 B에 요청을 보낼 때, 서비스 B에 대한 타겟 인스턴스의 IP를 모두 가지고 있어야한다. 만약 타겟 서비스의 이슈로 인스턴스 IP가 없으면 NR(No route configured), 헬스 체크가 실패해서 제대로 전달하지 못할 때, UH(No healty upstream hosts), 요청이 계속 실패해서 서킷이 열리면 UO(Upstream overflow)가 나오게 된다.
그리고 이슈 발생 시 요청 응답이 오래 걸렸거나, 커넥션 리셋의 이슈로 문제가 생겼을 때, 로그에서 그 상황을 모두 남겨주면 좋겠지만, 안타깝게도 남기지 못하는 경우도 있다. read timeout으로 클라이언트가 요청을 끊었으면 DC(Downstream connection termination)으로 찍히게 되고 서버단에서 요청을 제대로 응답하지 않으면 UC(Upstream connection termination)으로 찍히게 된다. 처음 Istio를 도입했을 때 이런 정보가 문제 해결을 위한 접근을 빠르게 해주었다. 이런 flag가 찍히게 되었을 때 alert를 통해 원인에 접근하는것이 수월해졌다.
추가적으로 UT(Upstream request timeout), UF(Upstream connection failure), URX(The request was rejected because the upstream retry limit) 같은 flag가 더 있다.
사용자, GSLB, L7, Istio, App까지 도달하면서 특정 홉에서 문제가 나면, 서비스까지 트래픽 요청이 오지 않는다. 이때 서버에서는 오류 로그가 나타나지 않아서 단순히 트래픽이 적어졌다고 오판할 수 있다. 이때 클라이언트 로깅으로 밖에 알 수 없다.
무엇을 모니터링 할 것인가?
토스의 많은 엔지니어 분들은 이를 위한 가시성 확보와 auto failover 구성에 많은 노력을 했다. 한 홉의 문제가 있을 경우 다른 컴포넌트 혹은 다른 IDC로 트래픽을 돌릴 수 있어야 하기 때문이다. 그리고 최종적으로는 IDC 외부에서 직접 최상단을 지속적으로 찔러 어플리케이션까지의 도달 여부를 판단할 수 있도록 블랙박스 모니터링(관찰자가 밖에서 시스템을 바라보는 접근 방식)까지 진행했다. aws route53을 통해서 블랙박스 모니터링 중이다. 정상 상태의 경우 양쪽 IDC 아이피를 번갈아 리졸빙해서 idc간에 트래픽을 조정하고, 하나의 홉이라도 이슈가 발생하면 어플리케이션까지 제대로 된 트래픽이 도달하지 못하고 헬스체크가 실패하게 된다. 그러면 리졸버에서 해당 앤드포인트로 아이피를 리졸빙하지 않게 되어, 다른 IDC로 트래픽을 보네 failover가 진행된다. 물론 DNS failover라서 클라이언트의 캐싱이 존재해서 완벽하게 failover되지 않지만, 외부에서 통신이 잘 되는지 확인하는 데 도움을 주었다.
OS 단의 매트릭은 하드웨어 리소스 입장에서의 메트릭이라 어플리케이션 오류와 상관관계를 찾기가 어렵다. 이 부분은 경험적인 인사이트의 의존도가 높았다. 기본적으로는 CPU, Memory, Network, Disk, 커널 관련 지표가 있다.
이때 USE method가 좋은 인사이트를 주었다. Bredan Gregg라는 넷플릭스의 퍼포먼스 엔지니어가 만든 분석 기법이다. 각 하드웨어 리소스에서 에러가 있는지 사용률이 높은지 리소스가 포화되어 더 이상 못 스는 상태인지 등을 보고 각 리소스의 문제를 배제해 나가는 방식이다. 이를 통해 모니터링을 보다 체계화 시킬 수 있었다. 아래는 해당 방식의 예시이다.
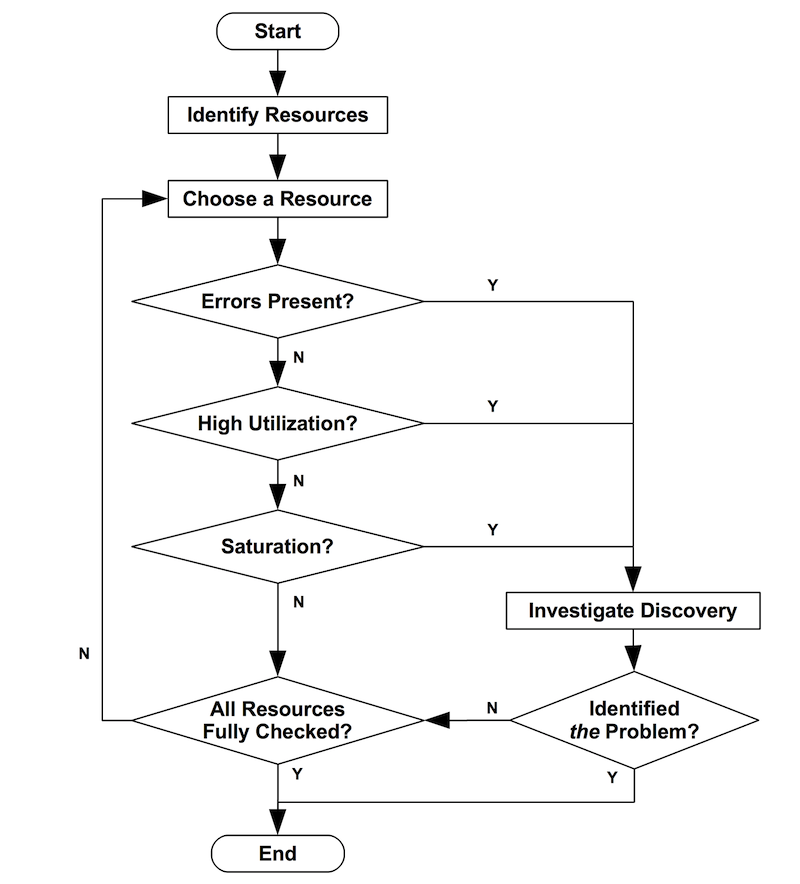
CPU의 경우 컨테이너의 CPU Usage를 알 수 있고, 컨테이너에서 리눅스의 CPU 알고리즘인 cfs 쓰로틀량을 측정할 수 있어, 이를 통해 CPU를 얼만큼 saturation되었는지 나온다면 CPU가 그 원인에 조금이라도 기여했다고 판단하였다.
이때 CPU를 더 줄지 아니면 쓰레드나 프로세스 설정을 변경할 지 판단하였다.
메모리의 경우 컨테이너 입장에서 메모리를 쓰고 있는지 판단하고 추가적으로 어플리케이션이 메모리 영역을 나눠 관리한다면 그 메트릭으로 사용량을 판단한다. 하지만 saturation이 얼마나 되었는지를 판단하기에는 아직 직관적인 메트릭을 찾지 못하였다고 한다. 그래서 oom 이벤트로 포화상태를 판단했고 oom이 나지 않는다면 메모리 이슈를 조금 배제하도록 했다. 물론 OS 캐시 때문에 메모리 할당 이슈가 있을 수 있다. 그래서 해당 부분은 주기적으로 비워주면서 해결하고 있다.
Disk Device는 각 어플리케이션이 얼마나 read/write를 많이 하는지, OS 입장에서 disk total utilization을 보고, io time이 얼마나 길어졌는지 보면서 saturation된 양의 척도로 삼았다. 최종적으로 error 여부를 보면서, 이슈가 났을 때 이 원인이 disk임을 판단할 수 있는 근거가 되었다. 그러나 서버 인프라에선 보통 디스크에 저장하는게 없다. 어플리케이션이 왜 디스크를 많이 쓰게 되는지 원인을 찾았다.
Network Device는 각 어플리케이션이 얼마나 많은 패킷을 보내고 있는지 OS 입장에서 network total utilization을 보고 사용량이 얼마만큼인지 판단하고, ethtool을 통해 얼마나 drop이나 overrun이 되었는지 알 수 있었다. 오류나 saturation의 척도는 컨테이너 네트워크에는 잘 잡히지 않기 때문에 해당 어플리케이션이 떠 있는 호스트 OS 입장에서 saturation된 양을 판단해 네트워크 디바이스에 이상이 없는지 보았다. 보통은 특정 어플리케이션이 네트워크 디바이스의 대역폭 (bandwidth)을 많이 차지해 다른 어플리케이션이 제대로 통신할 수 없었고 이를 근거로 해당 어플리케이션의 네트워크 사용을 제한하는 과정을 거쳤다.
컨테이너 오케스트레이션을 하면 호스트에는 여러 종류의 컨테이너가 떠있는데, CPU나 메모리는 최대한 독립적으로 사용할 수 있지만, 네트워크나 디스크는 독립적으로 사용하기 어렵기 때문에 같은 머신에 떠있는 어플리케이션들은 서로의 성능에 영향을 준다. 따라서 위에서 정리한 리소스별 인사이트를 통해 하나의 대시보드에서 모니터링을 진행하고 있다.
CPU Basic, Memory Basic, Time Spent Doing I/Os, Network Traffic by Packets, CPU(cores), Memory Total, fs read/write usage, Network rx/tx usage장비의 문제도 생길 수 있다. 장비에 과전류가 흘러 머신이 꺼진다던지 휴먼에러로 머신이 내려갈 수 있다. 그러면 재 빠르게 서비스 디스커버리에서 타겟을 제거해주어야한다. 과거에 꽤 자주 발생했다.
k8s에서도 이 문제를 해결할 수 있지만 클러스터링 관점이라 노드에 헬스체크도 해주어야하고 어플리케이션을 내리는 시간의 지연도 있었다.
그래서 보다 직관적으로 1초 마다 ping을 알려서 메트릭을 만들었다. 머신이 문제가 있어 통신할 수 없는 상황임을 판단하여, 특정 threshold를 넘으면 머신에 있는 어플리케이션을 제거하여 최대한 장애시간을 줄일 수 있도록 진행했다.
어떻게 모니터링 할 것인가?
또한 서버 인프라 뿐만 아니라 모니터링해주는 인프라에도 문제가 생길 수 있다. 프로메테우스가 내려가면 메트릭을 전혀 볼 수 없는 상태가 되었다. 프로메테우스가 죽으면 메트릭 수집이 중단되고 그 순간의 메트릭이 누락된다. 또한 메모리의 과다한 사용 이슈가 있었다. 수집하는 메트릭량 + tsdb의 크기가 메모리에 비례한다. 당연하게도 해결책은 최대한 프로메테우스가 죽지 않도록 수집하는 메트릭 량을 줄여야했고 프로메테우스가 쌓고 있는 tsdb의 사이즈를 줄여야 했다.
그 방법으로 과연 우리가 수집하는 메트릭을 모두 보는지, 그리고 보는 메트릭의 카디널리티(중복 수치를 뜻하며 유니크한 값인지를 확인하는 척도 이다.)가 적합한지 판단했다. 그래서 메트릭 쿼리 카운트를 통해 어느 메트릭이 정말 많이쌓이는지 보고 카디널리티가 너무 넓은 메트릭은 어그리게이션으로 축소해서 메트릭 양을 줄였다. 처음에는 어느정도 효과를 보았지만 결국 한계에 도달했다. 유지해야하는 가시성이 있기 때문에 더 이상 줄이지 못했다.
결국 프로메테우스를 스케일 아웃하는 방안을 고려하였다. 프로메테우스는 hashmod라는 옵션으로 샤딩 기능을 제공해준다. 이 기능을 활용하여 타겟을 분리해서 쌓았다. 그리고 타노스 쿼리를 통해 통합 쿼리가 가능해지기 때문에 쿼리 사용자 입장에서 달라지는 경험은 없게 된다.
tsdb의 사이즈를 줄이면 프로메테우스의 메모리 이슈를 클리어할 수 있다. 프로메테우스에 타노스 사이트카를 주입해서 tsdb를 큰 오브젝트 스토리지에 업로드할 수 있고 스토어 게이트웨이로 저장된 메트릭을 조회할 수 있다. 큰 오브젝트 스토리지에 보관하기 때문에 훨씬 긴 기간의 메트릭 보관도 가능해진다. 프로메테우스에는 tsdb 저장을 최소화하며 메트릭의 보관 기간도 길게 가져가서 프로메테우스 운영이 간편해졌다.
결론적으로 네트워크 제어권을 강화해서 네트워크 문제를 판단할 수 있는 메트릭을 생성하였고 발생하는 이슈와 메트릭 사이의 상관관계를 높였다. 모니터링 인프라도 스케일 아웃 가능하도록 구성하여 운영 안정성을 높였다.
