1. Background
- Two-stage Detectors
:image-Region Proposal-Classification-pred
1) Localization (후보영역찾기)
2) Classification (후보영역 분류)
: 속도가 느림
- One-stage Detectors
:image-Conv layer-feature map-pred
:Localization과Classification이 동시에 진행
: 속도가 빠름
: 영역을 추출하지 않고 전체 이미지를 보기 때문에맥락적 이해가 높음
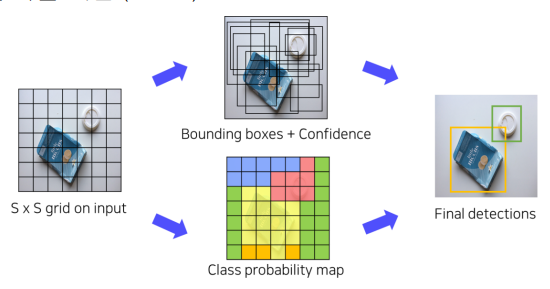
2. You Only Look Once(YOLO) v1
Region proposal단계가 없음- 전체이미지에서
bbox와class를 동시에 예측
Grid
- 입력 이미지를 x
grid로 나눔()- 각
grid마다 개의bbox와confidence score계산()- ()개의
bbox- 신뢰도(
confidence score)=- 각
grid마다 개의 class에 대한 해당 클래스일 확률 계산()conditional class probability=
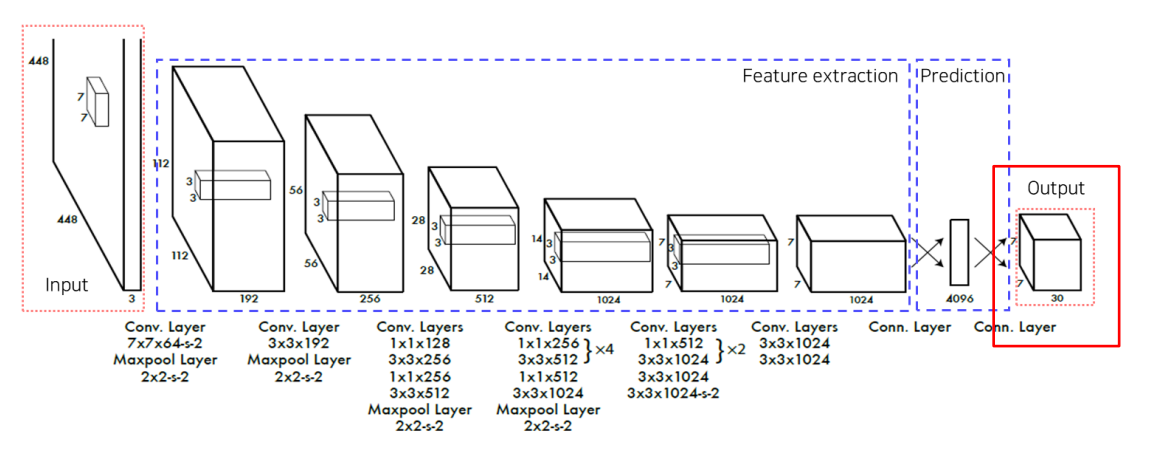
Network(참고슬라이드)
GoogLeNet을 변형하여 사용input image-GoogLeNet-output feature- = 의
output을 만듦
- output
- 출력이 가지는
30개의 channel을5/5/20으로 나눌 수 있음- 처음
5개는bbox1의 +- 두 번째
5개는bbox2의 +- 나머지
20개는class별score값을 나타냄- 각
bbox의score와class score를 곱해줌으로써 20차원의bbox class score를 얻어냄- 최종적으로 하나의 이미지당 개의
bbox에 대한 20차원의class score가 만들어짐
1)
threshold이하의class score를 갖는bbox의 값은 지움
2)class score기준으로 bbox를 내림차순 정렬함
3)NMS를 통해 겹치는bbox는 제거함
Loss
:
object가 있을 때를 의미
- 장점
1) Faster R-CNN에 비해 6배 빠른 속도
2) 다른 real-time detector에 비해 2배 높은 정확도
3) 물체의 일반화된 표현을 학습, 새로운 dataset에도 좋은성능


3. SSD
- YOLO의 단점
7x7 grid로 나눠grid보다 작은 크기의 물체 검출 불가능- 신경망을 통과하여 마지막 feature만 사용
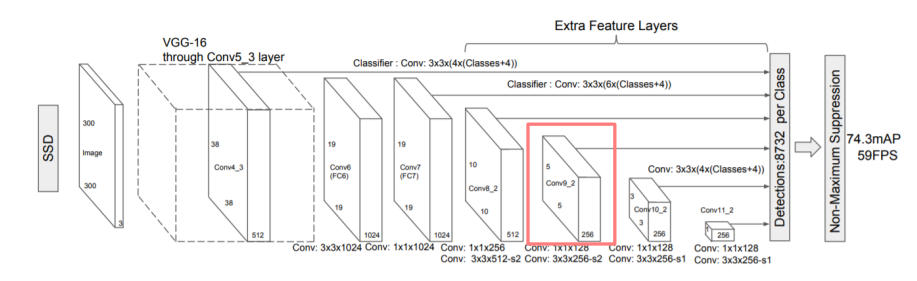
- SSD의 특징
Extra convolution layers에서 나온feature map들 모두detection수행
- 6개의 서로 다른 scale의 feature map 사용
- 큰
feature map에서는 작은 물체 탐지- 작은
feature map에서는 큰 물체 탐지fc layer대신conv layer사용하여 속도 향상Default box(= anchor box?)사용
- 서로 다른 scale과 비율을 가진 미리 계산된 box사용
- Network
VGG-16을backbone으로 사용- 다양한 크기의
feature map을 얻음
Multi-scale feature maps
- : 위치 정보
- : 클래스의 수(20) + 배경(1)
- 다양한 크기의
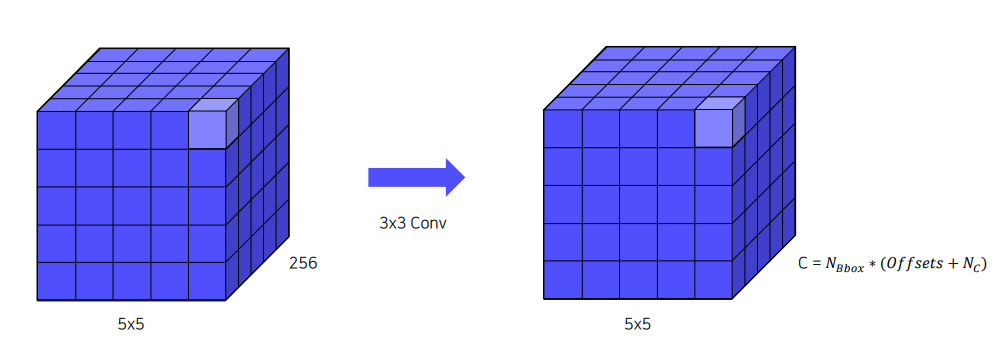
feature map을 만들기 위해 파라미터 를 사용aspect ratio인 에 를 곱해 다양한 크기의 를 만들어 냄- 이 1인경우에는 를 각각 로 두는 케이스를 추가함
- 그 결과로 각
cell별 (의 원소개수 + 1개)의default box를 만듦
- 각
bbox의 가 먼저 나옴- 가 나오고,
- 가 이어서 나옴
- 다양한 크기의
feature map을 얻은 후default box를 구해 매우 많은bbox를 얻음큰 feature map일수록작은 object를 잘 탐지하고작은 feature map일수록큰 object를 잘 탐지함
Training
Hard negative mining수행NMS수행





4. YOLO Follow-up
4.1 YOLO v2
- 3가지파트에서 model 향상
- Better(정확도)
- Faster(속도)
- Stronger(더 많은 클래스)
Better
Batch Normalization추가 ->mAP2% 향상- 였던 이미지의 resolution을 로 키워줌 ->
mAP4% 향상conv with anchor box->mAP5% 향상
fc layer제거anchor box도입- 좌표값 대신
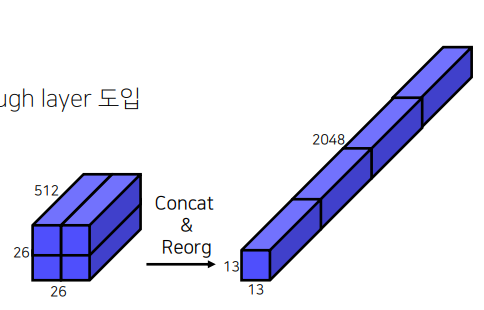
offset예측하는 문제가 단순하고 학습하기 쉬움Fine-grained features
low-level의 정보를high-level에 주고자early feature map을 분할 후,channel-wise로 결합하여late feature map에 합쳐주는passthrough layer도입
multi scale training
- 다양한 입력 이미지 사용
- multi-scale
feature map아님Faster
GoogLeNet대신DarkNet-19을backbone으로 사용Stronger
ImageNet,coco데이터셋을 동시에 사용ImageNet:classification만 수행coco:detection만 수행

4.2 YOLO v3
Darknet-53
skip connection적용Max pooling미사용,stride 2사용ResNet-101,ResNet-152와 비슷한 성능으로 더 높은FPS를 가짐Multi-scale Feature map
- 서로 다른 3개의
scale사용Feature Pyramid Network(FPN)사용
4.3 RetinaNet
one-stage가 가지고 있는 고질적인 문제를 해결
Class imbalance
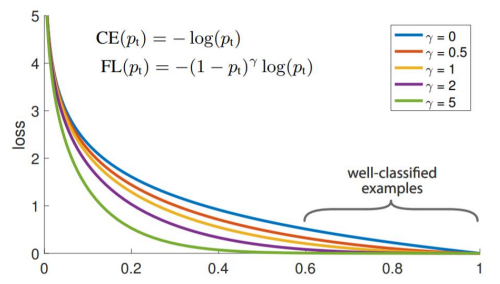
Anchor box대부분이negative sample임Positive sample(객체)<negative sample(배경)two-stage detector의 경우Region proposal에서negative sample을 제거해주고hard negative mining을 통해pos와neg를 적절하게 유지함Focal Loss
cross entropy+scaling factor- 쉬운 예제에 작은 가중치, 어려운 예제에 큰 가중치를 주어 어려운 예제에 집중하도록 함
Object Detection뿐만 아니라class imbalance가 심한classification task에도 사용할 수 잇음

인공지능 꿈나무