ImageNet Classification with Deep Convolutional Neural Networks, 2012
Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton
Introduction
Image Classification competition인 ImageNet LSVRC-2010, ImageNet LSVRC-2012에서 Deep Convolution Neural Networks를 사용하여 1위를 차지한 모델을 소개한다. 이미지 분류를 위해 약 6천만개의 파라미터를 사용했다. 5개의 convolution layer를 max pooling layer와 함께 사용했고, 3개의 full connected layer를 사용하였다. 2개의 GPU를 효율적으로 분산하여 학습속도를 높혔다. full connected 층에서의 과적합(over-fitting)을 막기 위해 당시 새로생긴(?) dropout을 추가하였다.
The Dataset
- ILSVRC는 2010년부터 시작되었고, 1000개의 범주별로 1000개의 이미지를 갖는 데이터를 사용한다. 대략 120만개의 training image와 5만개의 validation image, 15만개의 testing image가 있다.
- ImageNet의 이미지는 다양한 해상도의 이미지들로 구성되어 있기 때문에, 신경망(NeuralNet) 모델에 사용하기 위해서 논문의 필자는 이미지를 down-sampling하여 해상도를 256x256으로 맞추어 주었다.
- training set에서 mean activity를 구하여 각각의 픽셀에서 빼주었다.
The Architecture
ReLU
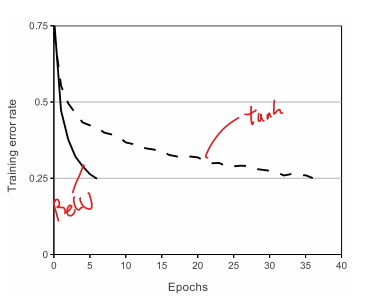
위의 그래프의 실험에서 최적의 성능을 얻어내기 위해 각기 다른 learning rate가 쓰였다고 한다.
- Rectified Linear Units(ReLUs)를 사용하여 tanh보다 몇 배 빠른 속도로 학습시킬 수 있었다고 한다. 이 빠른 학습속도는 큰 데이터셋에서 좋은 성능을 얻어내는데 큰 도움이 되었다고 논문의 필자는 설명한다.
GPU
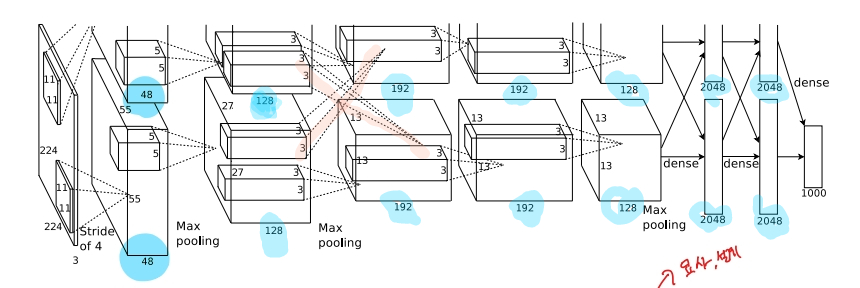
- 두 개의 GTX 580 GPU가 사용되었다.
- kernel을 반반 나누어 GPU를 병렬로 사용하였고, 특정한 layer에서만 GPU간의 교류(communicate)가 일어나게 하였다.
- 특정 layer를 제외하고 같은 GPU안에서 학습이 진행되므로 빠른 학습 속도를 얻을 수 있었다.
Local Response Normalization
-
같은 위치의 pixel에 있지만, 다른 kernel에 있는 pixel 값들로 Normalization하는 방법
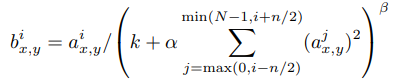
N: kernel의 수
i, j: i(or j)번째 kernel
k, n, α, β(상수): hyper-parmeter
a: i번째 kernel의 x,y위치의 값을 의미 -
논문에서는 다음 값을 사용하였다.
k = 2, n = 5, α = 10−4, and β = 0.75 -
정규화를 위해 사용하였고, 1~2%의 성능향상을 보여주었다고 한다.
Overlapping Pooling
- 논문에서는 strides(s) = 2, window(z) = 3x3를 사용하여 Overlapping(겹치는) pooling 방법을 사용하였다
- s=2, z=2로 두고 학습하였을 때보다, Over-fitting을 방지하는 효과를 발견하였다고 한다.
Overall Architecture
- LRN layer는 1,2 번째 convolution layer 뒤에서 사용되었다.
- Max Pooling layer는 LRN layer의 뒤와 5번째 convolution layer의 뒤에서 사용되었다.
Reducing Overfitting
Data Augmentation
- 좌우대칭(horizontal reflection)과 256x256의 원본 이미지(앞에서 preprocessing한)에서 224x224의 크기로 random cropping이용하여 데이터를 2048배 늘려주었다고 한다. test data를 예측할 때에는 네 모서리와 가운데 부분의 patch를 추출하여 예측값(output)을 평균(average)내어 사용하였다고 한다.
- training data에서 PCA를 하여 N(m=0, s=0.1)인 분포에서 얻은 값과 eigenvalue를 곱하여 픽셀의 강도(intensity)를 바꾸는 방법으로도 데이터를 augmentation 하였다고 한다.
Dropout
- 여러 모델을 결합하는 것보다 효율적인 방법이라고 소개함
- p(논문에서는 0.5)값을 정하여 random하게 선택된 neuron들의 출력을 사용하지 않는 방법
- 각각의 neuron들에서 robust feature를 얻을 수 있게 강제한다고 설명하였다.
- 처음 두개의 fully-connected layer에서 사용하였으다
Details of learning
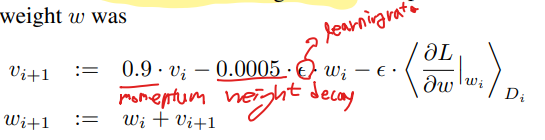
-
Stocastic Gradient Descent(momentumm=0.9, weight decay = 0.0005)를 사용하였다.
-
model regularizer의 역할을 수행하는 weight decay의 중요성을 매우 강조하였다.
-
N(m=0, s=0.01)의 분포에서 가중치(weights)를 초기화하였고, 편향(bias)은 2,4,5번째 convolution layer와 fully-connected layer에서만 1을 사용하였고 나머지 layer에서는 0을 사용하였다고 한다. bias를 1로 설정한 layer에서는 ReLU에 positive input을 제공함으로써 더 빠른 학습을 도왔다고 설명한다.
Result
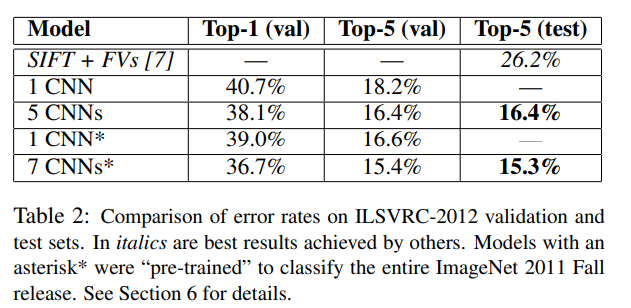
- CNN모델도 다른 machine learning 모델들과 마찬가지로, 단독을 사용하였을 때보다 여러 모델의 예측을 평균내었을 때 성능이 더 향상되었다고 한다. 또한 사전학습(pre-trained)된 모델을 사용하였을 때 성능이 향상되었다고 한다.

- 마지막 convolution layer의 ouput(4096차원)에서 유클리디안(Euclidean) 거리를 사용하여 비교했을 때 거리가 가까울 수록 같은 category의 이미지인 것을 확인할 수 있었다고 한다.
총평
- DCNN 모델의 초창기 버전이기 때문에 지금 주로 사용되는 방법론들과는 다른 부분들이 있지만, 큰 틀에서는 유사한 것 같다.
- PCA와 eigen value를 이용하여 data augmentation을 하는 것은 이번에 처음보았는데, 이 부분에 대해서는 조금 더 공부가 필요할 것 같다.
- 마찬가지로 Local Response Normalization(LRN)도 이번에 처음보았다. 최근에는 BatachNormalization(BN)이 주로 사용되는 것으로 알고 있는데, LRN의 성능을 BN과 비교해보는 실험을 해보는 것도 좋을 것 같다.
