YOLO 소개
2015년에 최초로 공개된 YOLO는 속도와 정확도 측면 모두에서 거의 모든 객체 탐지 아키텍처를 능가했다. 그 이후로 이 아키텍처는 몇 차례 개선됐다. 여기에서는 다음 3개의 논문을 통해 알아보겠다.
You Only Look Once: Unified, real-time object detection(2015), Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhad
YOLO9000: Better, Faster, Stronger(2016), Joseph Redmon, Ali Farhadi
YOLOv3: An Incremental Improvement(2018), Joseph Redmon, Ali Farhadi
YOLO의 강점과 한계
YOLO는 속도가 빠르나 최근에 나온 Faster RCNN이 정확도 측면에서 YOLO를 능가했다. 게다가 YOLO는 객체를 탐지하는 방식 때문에 작은 크기의 물건을 탐지하는 데 어려움을 겪는다. 또한 대부분의 딥러닝 모델과 마찬가지로 학습 데이터에서 너무 많이 벗어난 객체(가로세로 비율이 극단적으로 큰)를 탐지하는 일에도 어려움을 겪는다.
YOLO의 주요 개념
YOLO의 핵심 아이디어는 객체 탐지를 단일 회귀 문제로 다시 구성하는 것이다. 입력 이미지를 w*k 그리드로 나누고 그리드 각 부분에 대해 B개의 경계 상자(bounding box)를 정의한다.

그런 다음 각 경계 상자에 대해 다음을 예측하기만 하면 된다.
- 상자의 중심
- 상자의 너비와 높이
- 이 상자가 객체를 포함하고 있을 확률
- 앞서 말한 객체의 클래스
이 모든 예측은 숫자이므로 객체 탐지 문제를 회귀 문제로 변환했다.
실제로 YOLO에서 사용하는 개념은 이보다 좀 더 복잡하다. 만약 한 그리드 안에 여러 객체가 있다면 어떻게 될까? 또는 한 객체가 여러 그리드에 걸쳐져 있다면 어떻게 될까?
YOLO로 추론하기
모델 아키텍처를 한번에 이해하기 어려우므로 추론과 훈련으로 나누어 모델을 자세히 설명하겠다. 추론은 이미지 입력을 받아 결과를 계산하는 절차다. 훈련은 모델의 가중치를 학습하는 절차다. 모델을 처음부터 구현할 때는 모델이 훈련되기 전에 추론을 사용할 수 없다. 그렇지만 설명을 단순화하기 위해 추론부터 알아보겠다.
YOLO 백본
대부분의 이미지 탐지 모델처럼 YOLO는 백본 모델(backbone model)을 기반으로 한다. 이 모델의 역할은 마지막 계층에서 사용될 의미 있는 특징을 이미지로부터 추출하는 것이다. 이 때문에 백본 모델을 특징 추출기(feature extractor)라고도 부른다.
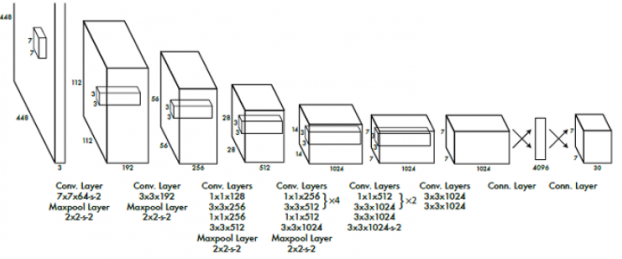
특징 추출기로 어떤 아키텍처도 사용할 수 있지만 YOLO 논문에서는 맞춤 아키텍처를 사용했다. 최종 모델의 성능은 특징 추출기 아키텍처로 무엇을 사용했는지에 따라 크게 달라진다.
백본의 마지막 계층은 크기가 w h D인 특징 볼륨을 출력하는데, 여기에서 w*h는 그리드의 크기이고 D는 특징 볼륨의 깊이다. 예를 들어, VGG-16의 경우 D=512이다.
그리드 크기인 w*h는 다음 두 요인에 따라 달라진다
- 전체 특징 추출기의 보폭: VGG-16의 보폭은 16으로, 출력된 특징 볼륨이 입력 이미지보다 16배 작다는 뜻이다.
- 입력이미지 크기: 특징 볼륨 크기는 이미지 크기에 비례하므로 입력 크기가 작을 수록 그리드 크기가 작아진다.
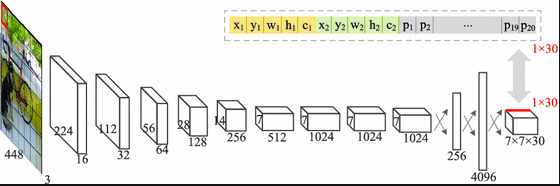
YOLO의 마지막 계층은 입력으로 특징 볼륨을 받는다. 이 마지막 계층은 크기가 1*1인 합성곱 필터로 특징 볼륨의 공간 구조에 영향을 주지 않고 깊이를 바꾸는 데 사용될 수 있다.
YOLO의 계층 출력
YOLO의 마지막 출력은 w h M 행렬로, 여기에서 wh는 그리드 크기이며 M은 공식 B(C+5)에 해당한다. B와 C는 다음과 같이 정의할 수 있다.
- B는 그리드 셀당 경계 상자 개수다.
- C는 클래스 개수다
클래스 개수에 5를 더했다는 점에 유념하자. 이는 경계 상자마다 (c+5)개의 숫자를 예측해야 하기 때문이다.
- tx와 ty는 경계 상자의 중심 좌표를 계산하기 위해 사용된다.
- tw와 th는 경계 상자의 너비와 높이를 계산하기 위해 사용된다.
- c는 객체가 경계 상자 안에 있다고 확신하는 신뢰도다.
- p1,p2, ... , pC는 경계 상자 클래스 1,2, ... ,C의 객체를 포함할 확률이다.
앵커 박스(anchor box)
tx,ty,th,tw가 경계 상자의 좌표를 계산하는 데 사용된다고 설명했다. 왜 직접 좌표(x,y,w,h)를 출력하지 않았을까? YOLO v1에서는 그러한 방법을 사용했으나 객체 크기가 다양해서 수많은 오차가 발생하였다.
사실 학습 데이터셋의 객체 대부분이 크면 w와 h가 매우 크다고 예측할 것이다. 그리고 작은 객체에서 훈련된 모델을 사용할 때 이 네트워크는 대체로 실패할 것이다. 이 문제르 해결하기 위해 YOLO v2부터는 앵커 박스를 도입했다.
앵커 박스(사전 정의된 상자[prior box])는 네트워크를 훈련시키기 전에 결정되는 일련의 경계 상자 크기다. 예를 들어 사람을 탐지하기 위해서는 길이가 길고 폭이 좁은 앵커 박스를 갖는다.
앵커 박스의 집합은 일반적으로 작으며 실제로 3~25 사이의 다양한 크기를 갖는다. 그러한 상자가 모든 객체와 정확하게 일치할 수 없으므로 네트워크는 가장 근접한 앵커 박스를 개선하는 데 사용된다. 이것이 tx,ty,th,tw가 필요한 이유로 앵커 박스 보정에 해당한다.
최초로 논문에서 앵커 박스를 소개했을 때는 수작업으로 9개의 상자 크기가 이용됐으나 이후로는 모델을 훈련시키기 전에 데이터를 분석해 앵커 박스의 크기를 선택할 것을 권고하고 있다.
YOLO v2에서는 다음과 같은 공식을 사용하여 최종 경계 상자 좌표를 계산한다.
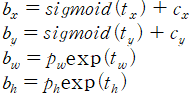
상자 사후 처리
결국 예측된 경계 상자의 좌표와 크기와 함계 신뢰도와 클래스 확률을 얻게 된다. 이제 신뢰도를 클래스 확률과 곱하고 높은 확률만 유지하게 임곗값을 설정하기만 하면 된다.
이렇게 임계값 기준으로 처리를 하다보면 같은 객체에 많은 경계 상자가 겹쳐서 탐지되어 경계 상자가 여러개가 중첩이 된다. 따라서 이를 보정하기 위해 사후 처리 파이프라인의 마지막 단계로 비최댓값 억제(non-maximum suppression, NMS)가 필요하다.
NMS
NMS의 기본 생각은 확률이 가장 높은 상자와 겹치는 상자들을 제거하는 것이다. 따라서 최댓값을 갖지 않는 상자들은 제거한다. 그러기 위해서는 확률 기준으로 모든 상자를 정렬하고 먼저 가장 확률이 높은 상자를 취한다. 그런 다음 각 상자에 대해 다른 모든 상자와의 IoU를 계산한다.
하나의 상자와 그 밖의 상자 사이의 IoU를 계산한 다음, 특정 임곗값을 넘는 상자를 제거한다.
YOLO 훈련시키기
YOLO 백본 훈련 방법
전체 모델을 훈련시키기 전에, 백본은 전이학습 기법을 사용해 ImageNet의 도움으로 전형적인 분류 작업을 하도록 훈련된다.
YOLO 손실
마지막 계층의 출력이 상당히 일반적이지 않아서 그에 대응하는 손실 또한 그렇다. 이를 설명하기 위해 손실을 여러 부분으로 나눈는데 각각은 마지막 계층에서 반환되는 출력의 한 종류에 해당한다. 이 네트워크는 다음처럼 여러 종류의 정보를 예측한다.
- 경계 상자 좌표와 크기
- 객체가 경계 상자 안에 있을 신뢰도
- 클래스에 대한 점수
경계 상자 손실
손실의 첫 부분은 네트워크가 경계 상자 좌표와 크기를 예측하기 위해 가중치를 학습한느 데 가이드를 제공한다.

- 람다는 손실에 가중치를 부여한다. 이것은 훈련하는 동안 경계 상자 좌표에 얼마만큼의 중요도를 부과할지를 반영한다.
- 시그마는 그 오른쪽 옆에 나오는 것들을 합계 낸다는 뜻이다. 이 경우, 그리드 각 부분에 대해 합계를 내고 그리드의 이 부분에 포함된 각 상자에 대해 합계를 낸다.
- 객체에 대한 지시 함수는 그리드의 i번째 부분의 j번째 경계 상자가 해당 객체를 탐지한다면 1이 되는 함수이다.

이 손실의 핵심은 지시 함수(1^ojb)다. 해당 상자가 객체를 탐지할 때만 좌표가 정확하다. 여기에서 이미지 내의 객체마다 어느 경계 상자가 탐지하는지를 결정하는 일이 여러운 부분이다.
객체 신뢰도 손실
두 번째로 알아볼 손실은 경계 상자가 객체를 포함하는지 여부를 예측하기 위해 가중치를 학습하도록 네트워크를 가르친다.

- C: 그리드의 i번째 부분에서 j번째 상자에 객체가 포함될 신뢰도
- 객체가 없을 경우에 대한 지시 함수: 그리드의 i번째 부분에서 j번째 경계 상자에서 객체가 탐지되지 않을 때 1이되는 함수

객체가 없을 경우에 대한 지시 함수를 계산하는 가장 원시적 방식은 (1-지시함수)이다. 하지만 그렇게 하면 훈련 과정에서 특정 객체를 탐지했는지 결정할 때 이 객체를 탐지했다고 볼 만한 적절한 후보군이 더 있을 수 있다. 이같이 해당 객체에 맞는 훌륭한 다른 후보들의 객체성 점수에 페널티를 부과해서는 안 된다. 따라서 다음과 같이 정의된다.

분류 손실
마지막으로 알아볼 손실은 분류 손실로 네트워크가 각 경계 상자에 대해 적절한 클래스를 예측하게 해준다.
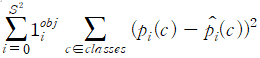
전체 YOLO 손실
전체 손실은 앞서 설명한 3개의 손실의 합이다. 이 세 항을 결합함으로써 전체 손실은 경계 상자 좌표 개선, 객체성 점수, 클래스 예측에 대한 오차에 페널티를 부과한다. 이 오차를 역전파함으로써 정확한 경계 상자를 예측하도록 네트워크를 훈련시킬 수 있다.
