Vision Transformer
개요
현재 AI계에서 화제가 되고 있는 "Vision Transformer"에 대해 다뤄보려고 한다. 이번에 제안된 Vison Transformer(이하 ViT)이라는 모델에 의해 더 이상 레이어를 겹치는 형태의 모델은 없어질지도 모른다.
ViT는 Transformer을 거의 그대로 이미지 분류 업무에 이용한 것으로, ImangeNet/ImageNet-ReaL/CIFAR-100/VTAB SoTA모델과 거의 비슷한 정도 혹은 그 이상을 성능을 달성하였다. 심지어 SoTA모델들(BiT/NoisyStudent)와 비교해서 계산 비용은 15분의 1까지 떨어졌다 (SoTA를 향상시킨 모델은 많아 봤자 4분의 1 혹은 5분의 1밖에 계산 비용을 줄이는데 그쳤지만 말이다).
이번에 다룰 논문은 ICLR2021의 OpenReview에서 등록되어 아직 리뷰중에 있지만, NLP에서 Transformer가 RNN을 구축한 것 처럼, 이미지 인식에서도 Transformer가 CNN을 구축하지 않을까하고 주목하고 있는 상태이다. 그렇다면 본격적으로 기대를 받고 있는 새로운 모델 ViT에 대해 살펴보자.
요약
-
완전히 Convolution과 안녕하고 SoTA를 달성했다
-
Vision Transformer에서 중요한 것은 세 가지이다.
① 이미지 패치(patch)를 단어와 같이 다루었다.
② 아키텍처는 Transformer의 엔코더 부분이다.
③ 거대한 데이터 세트인 JFT-300M으로 사전학습했다.
-
SoTA보다 뛰어난 성능을 약 15분의 1의 계산 비용만으로 얻을 수 있었다.
-
사전학습 데이터 세트와 모델을 더욱 크게 하여 성능을 향상시킬 수 있는 여지가 있다.
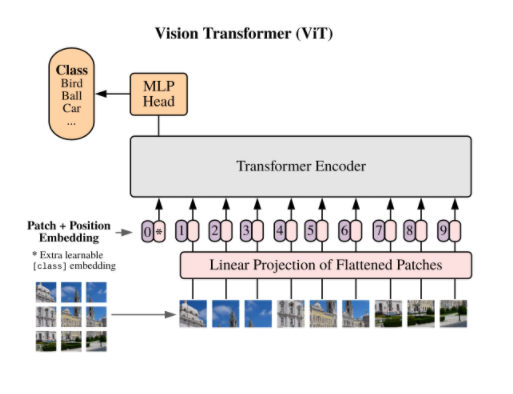
Vision Transformer 해석
Vision Transformer에서 중요한 부분은 세 가지이다.
- 입력이미지
- 아키텍처
- 사전학습과 파인 튜닝
1. 입력이미지
ViT는 Transformer를 베이스로 한 모델이지만 이러한 ViT에 이미지를 어떻게 입력한다는 것일까?
먼저 기본적으로 Transformer에는 각 단어가 벡터로 표현되어 있는 문장을 한 번에 입력한다.
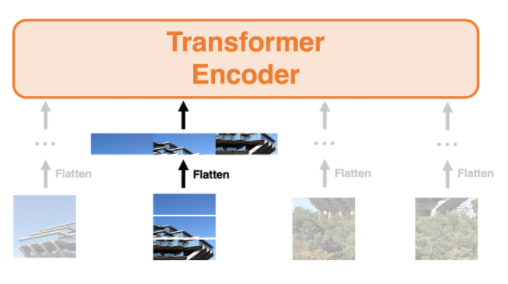
이러한 Transformer에 이미지를 넣고 싶을 경우 어떻게 할까?

답은 아래의 이미지와 같이 이미지를 패치로 나눠서 각 이미지 패치가 단어 벡터와 같이 다루면 된다.

각 이미지 패치가 단어처럼 다루기 때문에 실제는 패치를 벡터에서 Flatten한다. 아래의 그림에서 왼쪽에서부터 2번째의 패치에 대해 Flatten을 실행했을 때의 모습을 보여준다. 이처럼 모든 패치에 대해 동등하게 벡터와 Flatten 처리하여 엔코더에 입력한다.
원래의 이미지가 아래와 같이 수식으로 나타날 때

Flatten 한 뒤부터 ViT에 입력하는 것은 아래와 같이 벡터로 처리하여 입력한다.
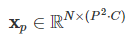
N은 패치 수이고, P는 패치의 크기를 의미한다. 여기서 패치는 정사각형이므로, 즉 N은 다음과 같이 표현할 수 있다.
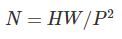
위 이미지의 원본 사이즈가 256이라고 한다면, N은 4, P는 128이 된다.
2. 아키텍처
아키텍처는 거의 Transformer의 엔코더 부분과 동일하다(즉 BERT). 엔코더의 구조는 다음과 같다.
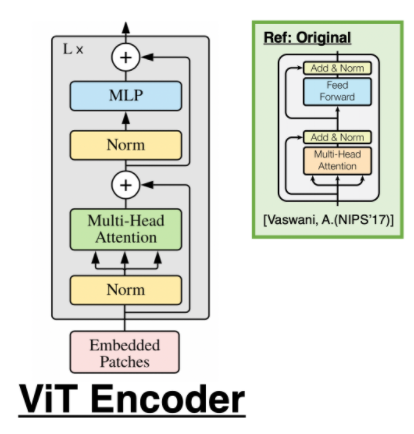
여기서 Norm은 layer normalization을 의미한다. 오리지널의 엔코더와 거의 동일하지만 다른점은 2가지이다.
-
Pre-Norm : Norm이 Multi-head Attention / MLP의 전에 위치해있다.
-
GeLU : MLP는 2단으로 활성화 함수로 GeLU를 채용하고 있다(오리지널은 ReLU 채용)
또한 입력부분에 Embedded Patches라고 되어 있다. 즉 앞서 설명한 patch 벡터들이다. 여기서 삽입하는 것은 아래의 두가지이다.
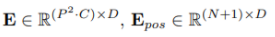
- Flatten 한 Patch를 학습 가능한 Linear Projection(E)을 사용하여, D 차원으로 매핑
- 각 패치에 위치 엔코딩 Epos를 계산
한편 위치 엔코딩도 학습 가능하다. 이미지 분류에서는 [cls] 토큰의 출력을 식별기(MLP)에 넣는 것으로 최종적인 예측이 나온다.

- 수식정리

xkp는 k번째 패치이고 각 배치는 xkp에 E를 곱해 [cls] 토큰을 연결한 후 위치 엔코딩 Epos를 더한다. 한편 E의 대신에 resnet에 각 패치를 넣어도 된다. 이 경우 패치는 flatten 되지 않고 resnet에 입력하여 그 출력에 대해 flatten을 실시한다. 논문 속에서는 패치의 최초의 입력에 resnet을 이용한 방법을 하이브리드라고 부르고 있다.
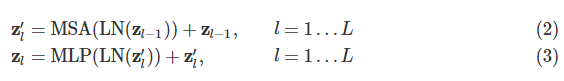
식(2)는 멀티 헤드 Attention을 표시하는 것이고 식(3)은 MLP를 나타낸 것이다.

입력 zL0는 최종출력단계에 있어서 이전부터 0번째의 벡터 표현이므로 즉 [cls]토큰의 최종 출력이다. 이것을 LN에 넣어 y를 얻는다. MLP 헤드 자체의 식은 논문에 나오지는 않지만 후에 이 y를 MLP에 넣는 것으로 최종적인 예측까지 나오는 것 같다.
[출처]
https://engineer-mole.tistory.com/133
https://kmhana.tistory.com/27
