TensorRT
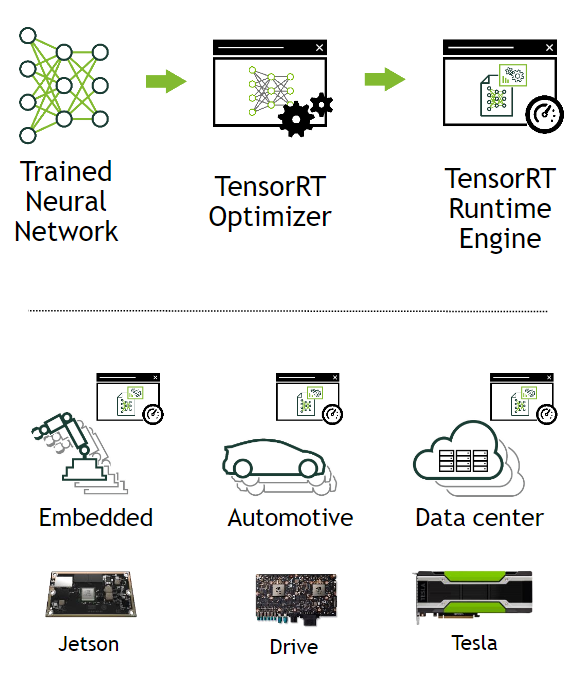
TensorRT는 학습된 딥러닝 모델을 최적화하여 NVIDIA GPU 상에서 추론 속도를 향상시켜 딥러닝 서비스를 개선하는데 도움을 줄 수 있는 모델 최적화 엔진이다. 학습된 모델을 실행하고자 할 때 모델을 경량화 시켜 연산 속도를 향상시킨다. 딥러닝 프레임워크인 pytorch, tensorflow, caffe 등을 통해 학습된 딥러닝 모델을 TensorRT를 통해 최적화하여 TESLA T4 , JETSON TX2, TESLA V100 등의 NVIDIA GPU 플랫폼에 아름답게 싣는 것이다.
또한, TensorRT는 NVIDIA GPU 연산에 적합한 최적화 기법들을 이용하여 모델을 최적화하는 Optimizer 와 다양한 GPU에서 모델 연산을 수행하는 Runtime Engine 을 포함한다. TensorRT는 대부분의 딥러닝 프레임워크에서 학습된 모델을 지원하며, 최적의 딥러닝 모델 가속화를 지원한다.
TensorRT의 장점은 C++ 및 Python 을 API 레벨에서 지원하고 있기 때문에 GPU 프로그래밍인 CUDA 지식이 별로 없어도 딥러닝 분야의 개발자들이 쉽게 사용할 수 있다. 또한 GPU가 지원하는 활용 가능한 최적의 연산 자원을 자동으로 사용할 수 있도록 Runtime binary 를 빌드해주기 때문에 Latency 및 Throughput 을 쉽게 향상시킬 수 있고, 이를 통해 딥러닝 응용프로그램 및 서비스의 효율적인 실행이 가능하다. 또한 흔히들 알고있는 Convolution Layer, ReLU 등의 Layer 뿐 만 아니라 다양한 Layer 및 연산에 대하여 Customization 할 수 있는 방법론을 제공하여 개발자들이 유연하게 TensorRT를 활용할 수 있도록 하고 있다.
TensorRT의 네트워크 최적화 방법

TensorRT는 학습된 딥러닝 네트워크 (trained neural network) 를 입력으로 받아, 추론에 최적화된 딥러닝 네트워크 엔진 (optimized inference engine) 을 출력한다.
TensorRT가 수행하는 최적화는 총 6가지이며 다음과 같다.
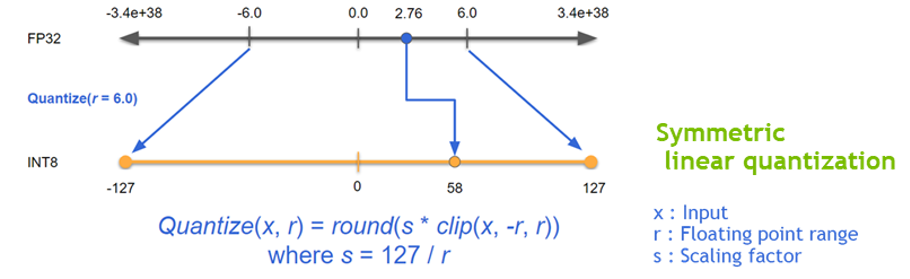
- Reduced Precision : 딥러닝 네트워크의 정확도를 유지하면서 FP32 연산을 FP16 (AMP) 혹은 INT8 (Quantization) 연산으로 바꿔 성능 향상을 달성함. 낮은 정확도를 가지는 데이터 타입 연산은 더 적은 메모리 사용량, 더 빠른(?) 메모리 접근, 더 빠른 계산 (Tensor core와 같은 specialized hardware unit을 사용할 수도 있음) 을 가능하게 함.
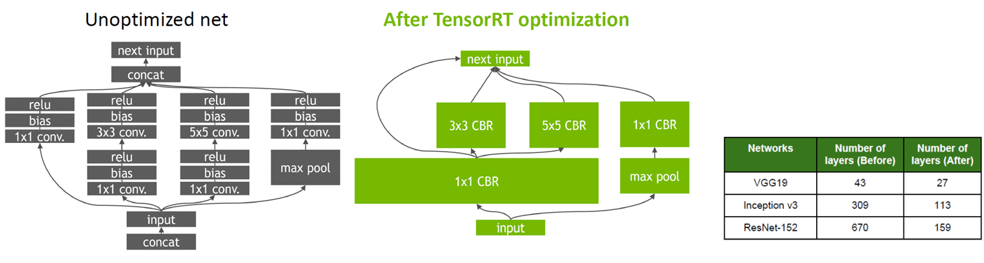
- Layer and Tensor Fusion : Operator fusion이라고도 하는데, 몇가지 Layer들을 하나의 layer로 합침. 이를 통해 data reuse 를 늘려 DRAM or off-chip memory 접근을 줄임. 이를 통해 성능 향상을 달성함.
- Kernel Auto-Tuning : 딥러닝 네트워크가 배포되는 시스템에 맞게 최적화된 GPU kernel tuning을 지원함. GPU는 어디에 사용되는 지 (데이터센터용 100시리즈, 임베디드용 jetson, 자율주행용 DRIVE), 어떤 세대인지 (Volta, Ampere, Hopper), 어떤 용도로 사용되는 지 (렌더링, HPC, 게임) 등 여러 조건에 따라 매우 다양한 아키텍처를 가짐. 각 아키텍처마다 최적 kernel parameters (thread block configuration, data layout, shared memory 등등) 가 달라질 것인데, 타겟이 되는 각 GPU 시스템에 맞게 이러한 kernel parameters를 자동으로 선택해줌.
- Dynamic Tensor Memory : GPU 메모리 사용량 최적화 및 재활용. GPU 메모리 할당 (malloc) 및 해제 (free) 는 매우 비싼 operation. 따라서 한번 GPU 메모리 영역을 할당하고, 그것을 반복해서 사용하는 것이 필수. TensorRT는 model 분석을 통해 네트워크에 사용되는 모든 tensor들의 lifetime을 알 수 있기에, 최적화된 메모리 영역 크기 파악 및 사용 스케쥴링이 가능.
- Multi-Stream Execution : 여러 input에 대한 병렬처리가 가능함. 이것에 대한 자세한 설명은 찾지 못하였는데, multiple GPUs (or MIG 자동) 를 자동으로 사용가능하게 해주는 것이 아닐까 함.
- Time Fusion : Recurrent neural networks에 대한 최적화. 이것에 대해서도 정리된 설명은 찾지 못해, document를 읽어서 정리해야겠음.
[출처]
https://eehoeskrap.tistory.com/414
https://computing-jhson.tistory.com/64
