
📰 이번에 다룬 뉴스:
architecture notes 의
Things You Should Know About Databases
⚠️ 뉴스를 보고 작성자 편한대로, 이해한 대로, 기억하고 싶은 부분만 번역했습니다. 믿지 마시고, 되도록이면 위의 원문을 봐주세요.
✒️ 느낀 점
매번 프로젝트를 할 때 마다 같이 erd 를 만들고 데이터를 다루지만, 정확히 DB 에 대해서 공부해본 적은 없는 것 같아서 이번에 번역을 하면 공부를 시작했다. 하지만 B-Tree 와 B+Tree 자료구조 부분에서 설명이 많이 부족해 이해가 쉽지 않았다. 이 부분은 좀 더 공부를 해봐야 될 것으로 보인다.
🔤 번역
들어가며
DB 는 어플리케이션의 모든 상태를 저장함에도 불구하고, 표면 레벨에서 DB 가 어떻게 동작하는지에 대해서는 잘 모른다는 것이 때론 놀랍기도 하다. 그래서 이번 포스트에서는 관계형 데이터베이스의 인덱스와 transaction 에 대해서 다루겠다.
❔ RDBMS 란?
관계형 데이터베이스는 1970년 E.F.Codd 가 제안한 관계형 데이터에 기반한 디지털 데이터베이스이다. 관계형 데이터베이스 관리 시스템(Relation Database Management System)은 관계형 데이터를 관리하기 위해 사용된다. 많은 관계형 데이터베이스는 SQL 옵션을 사용하여 데이터베이스를 관리한다. 예로는 MySQL 과 PostgreSQL 이 존재한다.
❔ index 란 무엇인가?
인덱스란 데이터구조로서 요청한 데이터를 찾는데 필요한 시간을 감소시켜준다. 이를 위해 인덱스는 추가적인 저장소와 메모리를 필요로 하며 계속 최신으로 유지시킴으로서 사용자로 하여금 테이블의 행을 하나씩 확인하는 지루한 작업을 건너뛸 수 있도록 해준다. 마치 책에서 인덱스를 해놓으면 한 번에 원하는 페이지로 이동할 수 있도록 하는 것과 비슷하다.
❔ 왜 index 가 필요한가?
적은 데이터는 관리하기가 쉽지만, 데이터가 커질수록 관리는 점점 어려워진다. 빠르게 처리되던 것도 점점 매우 느려지게 된다. 이렇게 커지는 관계형 데이터를 사용할 때 인덱스는 원하는 정보를 빠르게 가질 수 있도록 해준다.
❔ index 는 어떻게 동작하는가?
그래서 위와 같은 속도의 문제를 해결하기 위한 솔루션 중 하나는 데이터를 검색하는 방법에 따라 논리적으로 데이터를 저장하는 것이다. 이름으로 리스트에서 검색을 하고 싶다면, 이름을 통해서 리스트를 정렬할 것이다. 이와 같은 전략에는 아래와 같은 질문이 생겨날 수 있다.
- 다양한 다른 방법으로 검색하고 싶어지면 어떻게 하는가?
- 데이터를 추가하는 것은 어떻게 할 것인가? 충분히 빠른가?
- 데이터 업데이트는 어떻게 할 것인가?
- 작업의 O 표기법은 어떻게 되는가?
전략과 상관없이 우리는 순서를 관리할 방법이 있어야만, 정렬되지 않은 관계형 데이터에서 원하는 정보를 찾을 수 있을 것이다.
| id | 이름 | 도시 |
|---|---|---|
| 1 | 짱구 | 서울 |
| 2 | 철수 | 수원 |
| 3 | 훈이 | 부산 |
| 4 | 맹구 | 포항 |
| 5 | 유리 | 서울 |
위의 데이터를 살펴보면 위의 데이터는 저장소에 순서없이 랜덤하게 지각할 수 있도록 흩어져 있다. 요즘은 대부분의 서버가 SSD 를 달고 나온다.
위와 같은 데이터를 메모리로부터 읽는 것은 빠를뿐만 아니라 무척 사소한 일일 것이다.
| id | 이름 | 도시 |
|---|---|---|
| 1 | 신짱구 | 서울 |
| 2 | 김철수 | 수원 |
| 3 | 이훈이 | 부산 |
| 4 | 맹구 | 포항 |
| 5 | 한유리 | 인천 |
| ... | ... | ... |
| 1000000 | 봉미선 | 서울 |
| 1001000 | 신형만 | 서울 |
그럼 위처럼 데이터가 캐싱되기 힘들정도로 많다면 어떻게 될까? 또는 디스크에서 모든 데이터를 읽기에는 지나치게 시간이 많이 걸린다면?
지금 설명해주는 방법이 대부분의 개발자가 '나 이 문제 전에 본 적있어'라고 느끼는 부분이다. 우리는 해시맵과 같은 dictionary 와 특정 행에 우리가 원하는 것이 있는지를 전체 데이터를 훑지 않으면서 살펴볼 수 있는 방법이 필요하다.
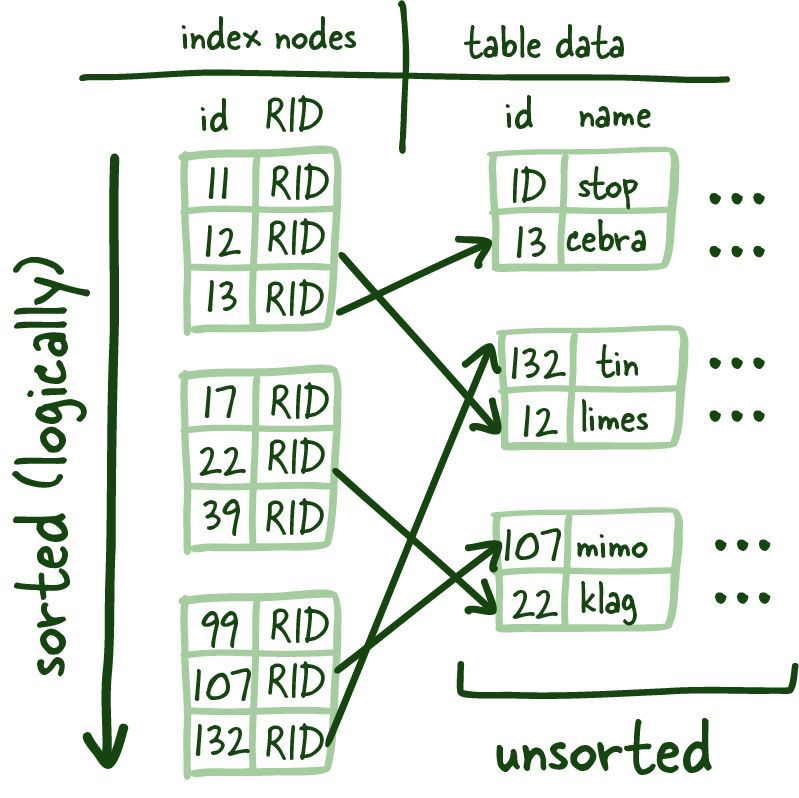
위의 사진은 아키텍처 노트에서 가져온 사진입니다.
위 사진속의 인덱스 리프 노드는 인덱싱된 열과 이에 해당되는 디스크에 저장된 정보를 매핑해준다. 이를 통해 인덱스 열을 통해서 검색을 하게 되면 빠르게 원하는 정보를 찾을 수 있게 된다. 인덱스를 스캔하는 것은 압축된 형태의 열을 스캔하는 것이기에 훨씬 시간을 아낄 수 있다. 블럭 전체를 뒤지는 것보다 훨씬 많은 시간을 아낄 수 있으며, 캐싱하는 것도 훨씬 용이해지며 결과적으로 전체 프로세스에서 사용되는 시간을 아낄 수 있도록 해준다.
이러한 인덱스 리프 노드는 균일한 사이즈를 가지며, 되도록 블럭마다 많은 리프 노드를 가질 수 있도록 하고 있다. 이와 같은 구조는 논리적으로 정렬이 되어야 되기 때문에 여전히 데이터를 빠르게 추가하거나 지우는 것에 대한 솔루션이 필요하다. 좋은 링크드 리스트, 정확히는 이중 연결 목록이 이 문제를 해결할 수 있다.
여기에는 2가지 이점이 있다. 인덱스 리프 노드를 앞뒤쪽 모두에서 읽을 수 있게되고 포인터를 수정하는 것이기에 새 행을 추가하거나 제거할 때 인덱스 구조를 빠르게 다시 빌드할 수 있다.
인덱스 리프 노드는 물리적으로 디스크에 정렬되는 것이 아니기 때문에 (포인터는 오직 이중 연결 목록에 대해서만 정렬한다) 정확한 인덱스 리프 노드를 찾는 방법이 있어야 한다.
Balanced Trees (B+Trees) - 이 부분은 다른 글을 참고해주세요
이 부분은 포스트 내용이 잘 이해가 되지 않아 추가적인 공부가 필요하다
B+Trees 를 사용하면 각각의 중간 노드 모두가 각각의 트리의 리프 노드 중 최상위 노드의 값을 가리킨다. 이를 통해 필요한 데이터를 가리키고 있는 정확한 인덱스 리프 노드를 찾기위한 정확한 경로를 얻을 수 있다.
이 구조는 아래에서 위로 향하도록 빌드되어 있어서 모든 중간 노드는 뿌리 노드까지의 모든 리프 노드를 다룰 수 있게 된다. 이 트리형태가 balanced 라는 이름을 가진 이유는, 트리전체에서 동일한 깊이를 가지고 있기 때문이다.
대수적 확장성
많은 개발자가 데이터의 기하급수적 증가와 회사의 가치 평가에 대해서 알고 있지만, 데이터의 크기는 간혹 우리를 힘들게 하는 경우가 있으며, 이 때 균형 트리는 지나치게 큰 데이터를 다룰 때 대항할 수 있는 가장 첫 번째 무기가 될 것이다.
중간 노드가 참조할 수 있는 항목의 수 M 개와 전체 트리의 깊이 N 에 따라 우리는 M 을 N개의 객체를 통해 참조할 수 있다.
M 이 5일 때의 테이블은 아래와 같다.
|깊이 N|인덱스 리프 노드|
|--|--|
|3|125|
|4|625|
|5|3125|
|6|15625|
|7|78125|
|8|390625|
|9|1953125|
기하급수적으로 인덱스 리프 노드가 증가할 때, 트리의 깊이는 놀라울 정도로 천천히 대수적으로 늘어난다.
이는 균형잡힌 트리의 깊이와 결합되어 디스크의 특정 데이터와 관련된 인덱스 리프노드를 거의 즉각적으로 찾을 수 있도록 해준다.
단어
tedious: 지루한
perceivably: 지각할 수 있게
trivial: 사소한
arsenal: 무기고, 무기창고, (집합적으로)무기
respective: 각각의
Logarithmic: 대수적인
exponential: 기하급수적인

인덱스에 대해 잘 배우고 갑니다! 🧡