★★주의할 점★★
1) 해당 문서에 사용된 모든 코드는 crypto_prediction에 있습니다.
2) 딥러닝 앙상블 코드는 Adaboost-GRU 앙상블 모형을 이용한 금융 시계열 예측 논문을 참고하였습니다.
3) 글 앞에 잡소리가 많습니다. 모델을 바로 보시려면 2. Preparing Datasets 로 넘어가주세요~
1. Intro
요즘 가상화폐가 금융계에서 상당히 핫하죠. 5년 전만 해도 쉽게 살 수 있던 비트코인이 현재는 몇 천만원 대에 거래되고 있기도 하구요, 적은 시드머니로 많은 수익을 냈다는 글도 인터넷에서 쉽게 볼 수 있습니다.
이런 가상화폐의 등락을 예상하고 매수할 수 있다면 얼마나 좋을까요? 이와 관련해서 금융 시계열 예측은 예전부터 활발히 이루어졌습니다. 다만 주가, 가상화폐 등의 시계열 자료는 비선형성, 불규칙성을 가지고 있어 쉽게 예측하기 힘들죠.
(1) Statistical Method vs Deep Learning
금융 시계열 데이터를 예측하는 방법은 크게 통계적 방법과 딥러닝을 사용한 방법이 있습니다. ARIMA로 대표되는 통계적 방법론은 간단히 말하자면 주어진 데이터에 선형성과 규칙성을 부여해서 예상하는 방법입니다. 하지만 아까 말했듯이 금융 시계열 데이터는 비선형적이고 불규칙한 경우가 많죠. 따라서 학습 데이터에 과도하게 의존하는 과대적합(over-fitting)문제가 일어날 수 있습니다.
딥 러닝 방법은 시계열 데이터의 특징을 머신러닝으로 해결하는 방법 중에 하나입니다. 금융 시계열 데이터에 사용되는 대표적인 딥 러닝 모델은 RNN, LSTM, GRU입니다. 모두 RNN 기반의 time-step을 입력값으로 받는 딥 러닝 모델이라는 것이 공통점이죠. 하지만 vanilla RNN은 time-step이 길어질수록 성능이 낮아지는 문제를 가지고 있기 때문에, RNN을 개량한 LSTM과 GRU가 멀리 쓰이고 있습니다.
(2) Hybrid Ensemble Deep Learning
딥 러닝 방법론에선 LSTM과 GRU를 사용해서 앙상블 모형을 개발하는 방법도 활발히 시도되고 있습니다. 본 글에서 참고한 논문은 Adaboost-GRU 앙상블 모형을 이용한 금융 시계열 예측입니다. 얼마 전 나온 따끈따끈한 논문이죠. 해당 논문에 모델에 대한 자세한 설명이 있습니다.
딥러닝 앙상블의 기본적인 아이디어는
딥러닝을 사용한 분류기를 여러 개 만들어서 결합으로 강한 최종 분류기를 만든다!
입니다. 논문에서는 GRU를 이용해 딥 러닝 모델을 만들고 KerasRegressor로 분류기를 만들어 Adaboost알고리즘으로 분류기들을 결합하였습니다. 자세한 코드는 이후에 제시하겠습니다.
(3) MAE, MSE, RMSE
시계열 데이터 예측 모델의 성능을 평가하는 지표들입니다.
MAE 는 Mean Absolute Error의 줄임말로, 실제값-예측값에 절대값을 취해서 평균을 냅니다.
def MAE(y_true, y_pred):
return np.mean(np.abs(y_true-y_pred))MSE 는 Mean Square Error의 줄임말로, 실제값-예측값에 제곱을 취해서 평균을 냅니다.
def MSE(y_true, y_pred):
return np.mean(np.square(y_true-y_pred))RMSE 는 Root Mean Square Error의 줄임말로 MSE에 루트를 취합니다.
def RMSE(y_true, y_pred):
return np.sqrt(np.mean(np.square(y_true-y_pred)))2. Preparing Datasets
(1) pybithumb
pybithumb 모듈을 활용해 현재 거래중인 가상화폐의 시계열 데이터를 얻어올 수 있습니다.
# 빗썸 가상화폐 데이터 모듈
!pip install -q pybithumb
import pybithumb
mydf = pybithumb.get_ohlcv("ETH",interval='hour').reset_index()
mydf.head()
time open high low close volume
0 2020-11-30 16:00:00 637000.0 639500.0 636500.0 638000.0 2856.190998
1 2020-11-30 17:00:00 638000.0 638500.0 623500.0 629500.0 9376.482516
2 2020-11-30 18:00:00 629500.0 632500.0 624000.0 630000.0 4245.008116
3 2020-11-30 19:00:00 630000.0 637500.0 629000.0 634000.0 1781.313382
4 2020-11-30 20:00:00 634000.0 646000.0 634000.0 643000.0 4348.065615pybithumb.get_ohlcv 함수로 이더리움(ETH)의 거래정보를 얻어왔습니다.
데이터는 2020년 11월 30일부터 현재까지의 시간 단위 시계열 데이터입니다. 시가, 종가, 고가, 저가, 그리고 볼륨이 포함된 데이터프레임이 반환됩니다.
시가(open)만 사용해 시각화를 해보았습니다.
plt.plot(mydf['open'])
plt.title('ETH')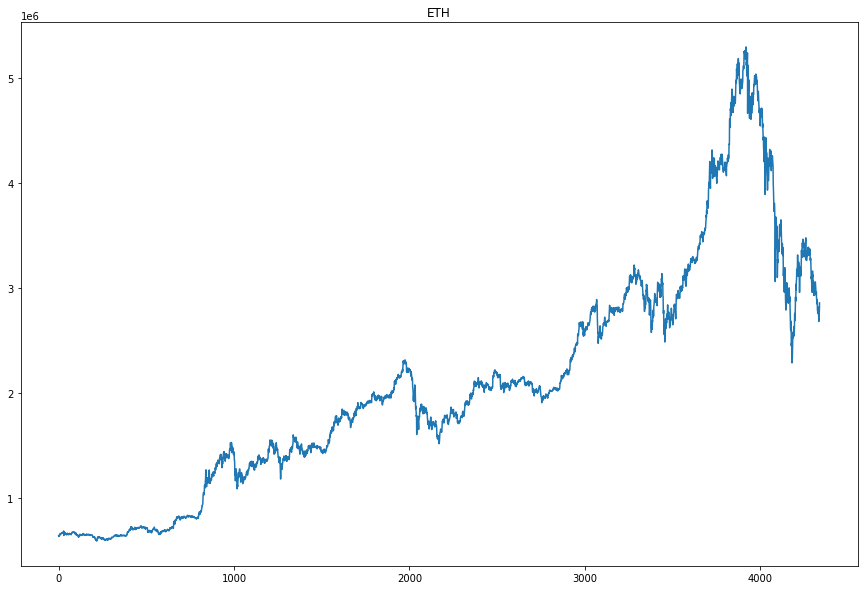
아주아주 불규칙한 그래프가 보입니다. 역시 가상화폐답게 변동폭이 매우 큽니다.
(2) preprocessing
금융 시계열 데이터의 전처리 방법은 크게 두 가지가 있습니다. smoothing과 scaling입니다. 여기서는 두 가지 모두 사용해서 전처리를 진행하겠습니다.
smoothing 은 정해진 하나의 timestep 값에서 window의 평균(혹은 최대값, 최소값 등의 통계수치)을 나누어 데이터의 분포를 고르게 만들어주는 방법입니다. 눈으로 보면 이해가 빠르니 바로 코드로 돌려 봅시다. smoothing은 pandas 내장 함수인 pd.Series.rolling으로 구현할 수 있습니다.
rolling_10 = mydf['open'].rolling(10, min_periods=0).mean()
plt.plot(rolling_10)
plt.title('ETH rolling window=10')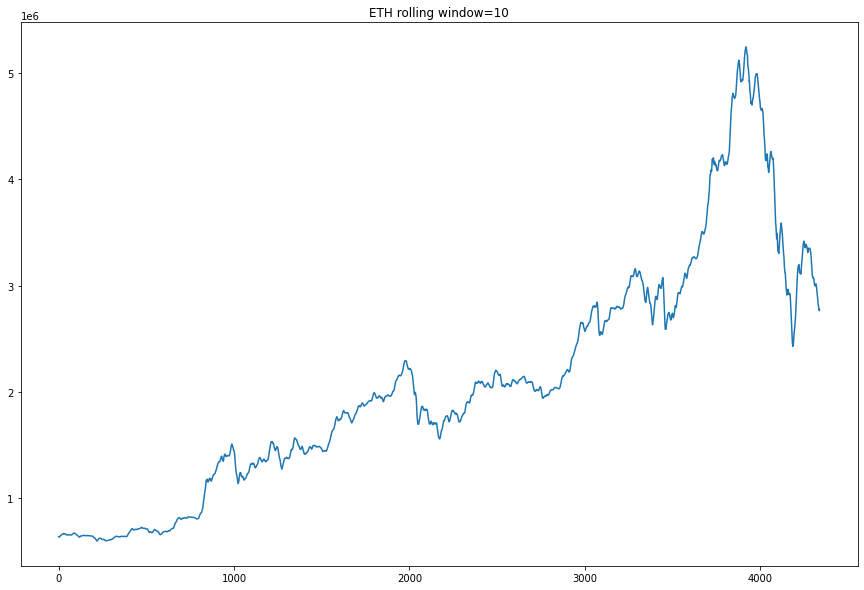
window size=10으로 mean rolling을 적용한 그래프입니다. 한 눈에 보아도 그래프가 조금 부드러워진 것을 볼 수 있죠? smoothing을 적용하면 학습 시 좀더 안정적인 예측을 가능하게 해줍니다.
scaling 은 데이터의 분포를 표준화하는 과정입니다. StandardScaler, MinmaxScaler 등이 있지만 여기서는 데이터의 최대, 최소값을 사용하는 MinmaxScaler를 사용하겠습니다.
scaler = MinMaxScaler()
training_data = scaler.fit_transform(mydf['open'].reshape(-1,1))
plt.plot(training_data)
plt.title('preprocessed training data')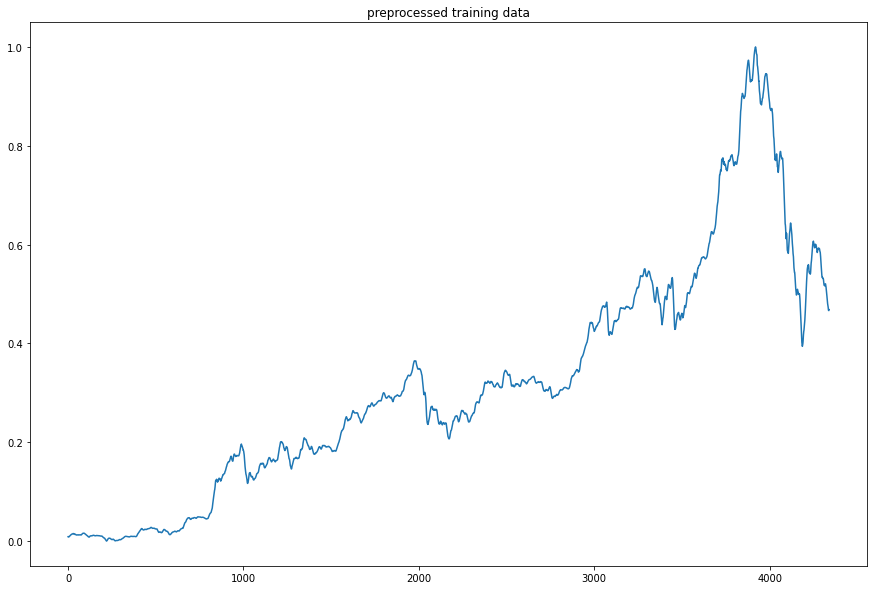
scaling을 적용하면 y값이 0과 1 사이로 나타나는 것을 볼 수 있습니다.
(3) input datasets
딥러닝을 활용한 시계열 예측에서는 트레이닝 데이터를 딥러닝 학습 데이터로 만드는 과정이 필요합니다. X는 t개의 time-step으로 이루어진 벡터입니다.
X = (x0,x1,...,x(t-1))
이에 대응되는 라벨 데이터 y는 xt로부터 h step 떨어져 있는 벡터입니다. h가 0이면 X 벡터의 마지막 값의 다음 값을 예측하는 것입니다. 원래 하나의 X 벡터로 여러 개의 y값을 예측할 수도 있지만 여기에서는 하나의 y값만을 예측한다고 생각하겠습니다.
y = x(t+h)
y_hat = f(X)
해당 내용을 make_dataset 코드로 구현하였습니다.
def make_dataset(training_data, t, h=0, test_size=0.2):
X_train = []
y_train = []
for i in range(t, len(training_data)-h):
X_train.append(training_data[i-t:i])
y_train.append(training_data[i+h])
X = np.array(X_train)
y = np.array(y_train)
X_train,X_test,y_train,y_test = train_test_split(X, y, test_size=test_size, shuffle=False)
return X_train,X_test,y_train,y_test만들어진 데이터의 20%를 테스트 데이터로 사용하기 위해 train_test_split 함수를 사용했습니다. 데이터의 순서를 보존하기 위해 shuffle=False argument를 넣어 주는 것이 필수적입니다.
3. Training
모델의 성능을 비교하기 위해 Adaboost-GRU 모델 이외에도 Adaboost-LSTM, single GRU, single LSTM 모델을 추가적으로 학습시켰습니다.
(1) Adaboost-GRU
model = Sequential()
model.add(InputLayer(input_shape=(X_train.shape[1],1)))
model.add(GRU(units=128))
model.add(Dropout(0.5))
model.add(Dense(units=1))
model.compile(loss='mean_squared_error', optimizer='adam')논문 의 의사코드를 참고하여 GRU 모델을 만들었습니다. 여기에
GRU_Predictors = KerasRegressor(build_fn=lambda:model, epochs=20, batch_size=30)
final_model = AdaBoostRegressor(GRU_Predictors, n_estimators=5, random_state=42)KerasRegressor 를 사용하여 분류기를 만들어준 뒤 AdaBoostRegressor 로 최종 결합하였습니다. 논문에서는 GRU_Predictors epochs=50을 사용했고 AdaBoostRegressor n_estimators=200을 사용했지만 학습 시간 단축을 위해 낮게 조정하였습니다.
final_model.fit(X_train,y_train)
preds = final_model.predict(X_test)
preds = scaler.inverse_transform(preds.reshape(-1,1))
preds_series = np.hstack([mydf['open'][:-len(preds)], preds.squeeze(1)])
plt.plot(preds_series, label='prediction')
plt.plot(mydf['open'], label='true')
plt.axvline(x=len(mydf['open'])-len(preds), color='r')
plt.legend()
plt.show()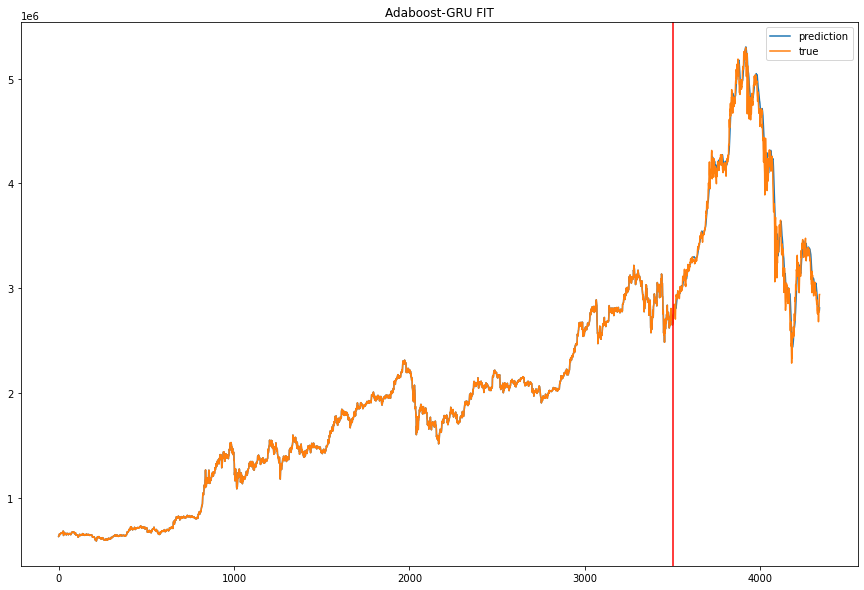
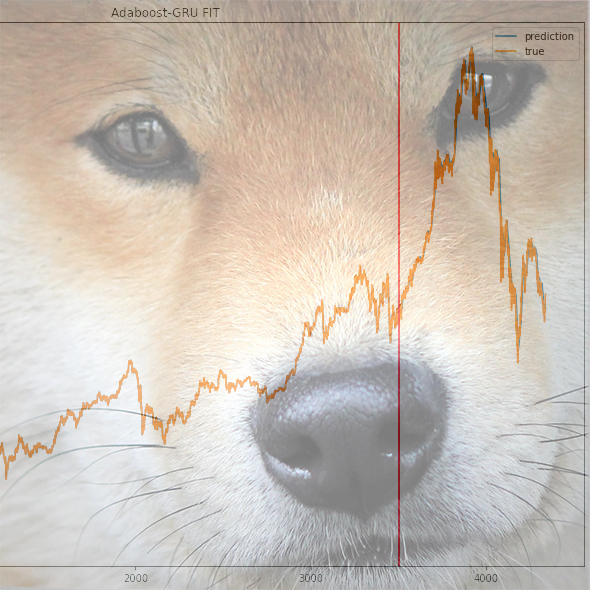
해당 코드로 학습 데이터를 fit하고 플롯으로 그려 보았습니다. 큰 오차 없이 학습이 잘 된 것을 알 수 있습니다. 결과값을 스케일러를 사용해 inverse_transform해 주었습니다.
(2) Etc.
Adaboost-LSTM은 위와 같은 코드를 사용했지만 약한 분류기를 만들 때 GRU가 아닌 LSTM을 사용한 점만이 다릅니다. single GRU와 single LSTM은 같은 모델로 같은 파라미터를 사용해 학습시켰습니다.
예측 결과를 시각화하면 다음과 같습니다. (이미지를 병렬로 넣고 싶은데 방법을 모르겠군요.)
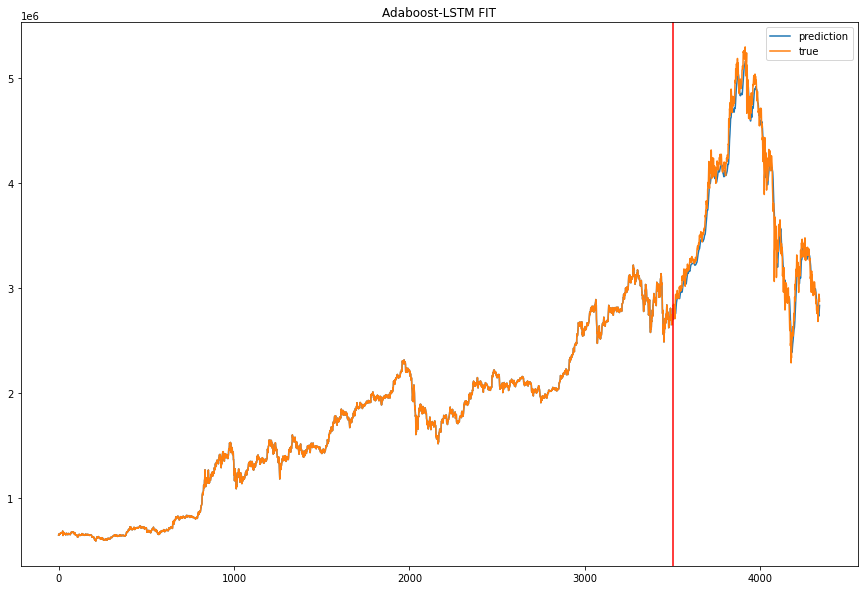
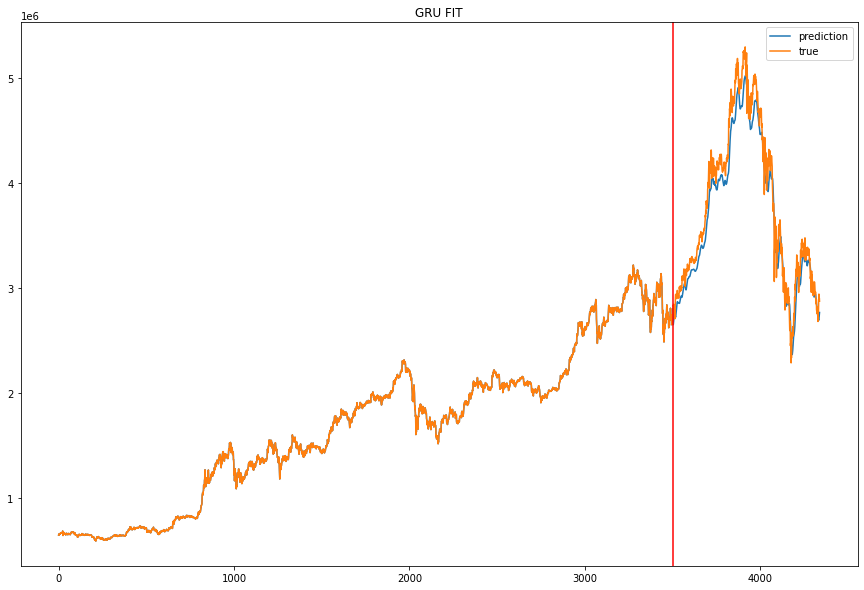
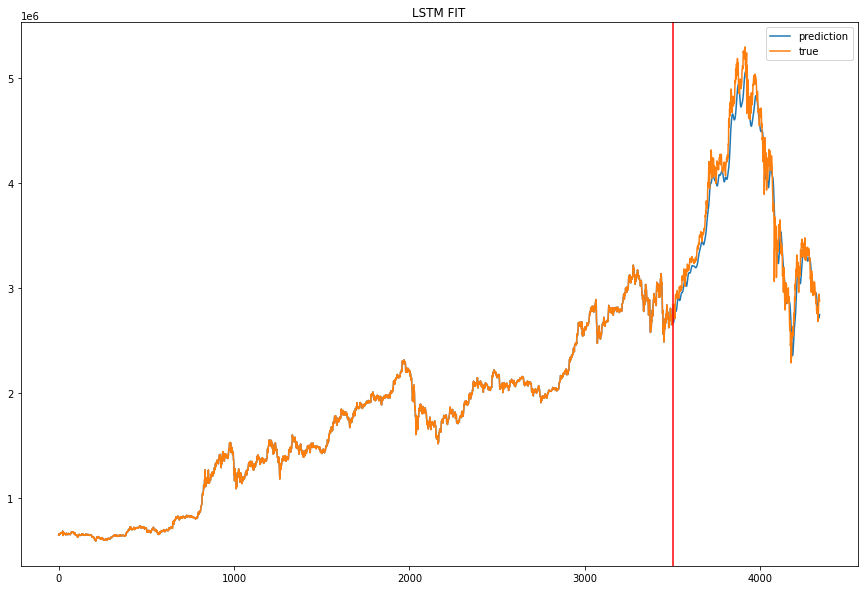
MAE, MSE, RMSE 로 나타낸 모델 성능입니다.
| Adaboost-GRU | Adaboost-LSTM | single GRU | single LSTM | |
|---|---|---|---|---|
| MAE | 7.92e+04 | 9.76e+04 | 1.50e+05 | 1.36e+05 |
| MSE | 1.23e+10 | 1.49e+10 | 3.06e+10 | 2.75e+10 |
| RMSE | 1.11e+05 | 1.22e+05 | 1.75e+05 | 1.66e+05 |
보기에 좀 불편하기는 하지만 Adaboost-GRU, Adaboost-LSTM, single LSTM, single GRU 순으로 성능이 좋은 것을 확인할 수 있습니다.
다만 이는 파라미터 조절이나 데이터(가상화폐 종류)에 따라 변동될 수 있는 값이니 절대적인 순위는 아닙니다! 이러한 시계열 예측 방법도 있다~ 정도만 알아가시면 될 것 같습니다.
해당 문서에 사용된 모든 코드는 crypto_prediction에 있습니다.
참고문헌: Adaboost-GRU 앙상블 모형을 이용한 금융 시계열 예측

4개의 댓글

lstm과 gru의 고질적인 문제를 언급 해주시면 더 좋은 글이 될 거 같습니다. error계측이 낮게 나와도 결국 time-lag 현상 때문에 사용 못하는 알고리즘이라는 것 입니다. error계측이 낮게 나오는 이유는 원래 t1-t0 가격 변동폭은 크지 않아서 낮게 나옵니다.

좋은 내용 감사합니다 멋지네요! 저도 퀀트 공부하는 중인데, https://quantpro.co.kr/ 해당 사이트 퀀트 내용 어떤지 의견주시면 감사하겠습니다!
궁금한게 있는데 미래는 어떻게 알 수 있나요??
학습한 모델을 통해 미래 예측을 할 수는 없는 건가요?
존재하는 데이터를 넘어서 미래의 예측값을 알고싶어요.