
📚 프로세스와 스레드
프로세스와 스레드의 차이점
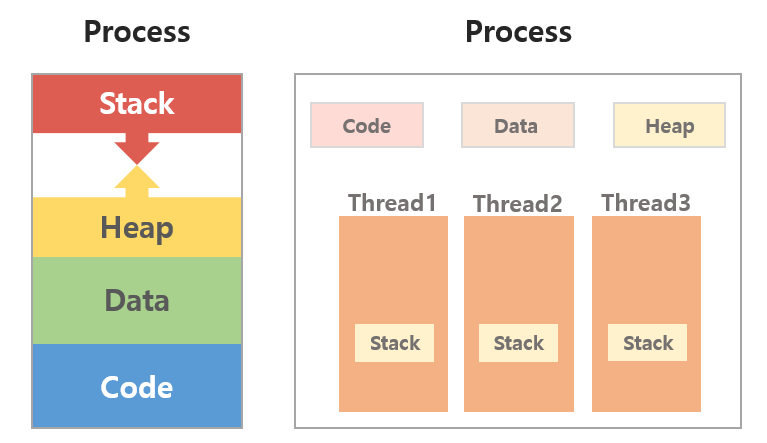
프로세스는 프로그램을 메모리에 올려 실행한 상태로 운영체제로부터 독립된 메모리 영역(Code, Data, Stack, Heap)과 CPU 자원을 할당받을 수 있다. 스레드는 이런 프로세스 내의 실행 단위로 프로세스의 자원을 공유(Code, Data, Heap)하면서 프로세스를 실행하는 흐름으로, 독립적인 실행이 가능할 수 있도록 Stack, PC 레지스터를 독립적으로 할당받는다.
프로세스
실행 중인 프로그램
프로세스와 프로그램의 차이점
프로그램은 작업의 절차를 실행할 수 있는 정적 파일, 프로세스는 프로그램을 메모리에 올린 동적인 상태(프로그램을 실행하면 프로세스 인스턴스가 생성된다고 생각)
- 디스크로부터 메모리에 적재되어 CPU의 할당을 받을 수 있음
- 운영체제로부터 주소 공간, 파일, 메모리 등을 할당받을 수 있음
프로세스의 메모리 구조
- Code 영역: 실행할 프로그램의 코드가 저장된다.
- Data 영역: 전역변수와 정적변수가 저장된다. 이 변수들은 프로그램이 시작될 때 할당되어 프로그램 종료 시 소멸된다.
- Stack 영역: 지역변수, 매개변수, 리턴값 등 잠시 사용되었다가 소멸되는 데이터를 저장하는 영역이다.
3가지 영역은 컴파일 시점에 크기가 결정되기 때문에 무한대로 할당할 수는 없다. stack 영역은 최대 할당 크기는 컴파일 시점에 결정되지만 동적으로 크기가 변한다. 만약 스택이 넘치면 stack overflow가 발생한다.
- Heap 영역: 필요에 의해 메모리를 할당하고자 할 때 사용하는 동적 데이터 영역으로 메모리 주소값에 의해서만 참조되고 사용되는 영역
Heap 영역은 런타임(프로그램 동작) 시에 크기가 결정된다.
스레드
프로세스가 할당받은 자원을 공유하여 이용하는 실행 흐름의 단위
- 한 프로세스 내에서 동작되는 여러 실행 흐름으로 프로세스 내의 주소 공간이나 자원 공유
- 하나의 프로세스가 생성되면 하나의 스레드(메인 스레드)가 생성됨
- 하나의 프로세스는 여러 개의 스레드를 가질 수 있음
- 스레드는 프로세스 내에서 Stack만 따로 할당받고 Code, Data, Heap 영역 공유 (추가로 PC 레지스터 값도 따로 갖고 있음)
스택을 스레드마다 독립적으로 할당하는 이유
스택은 함수 호출 시 전달되는 인자, 되돌아갈 주소값 및 함수 내에서 선언하는 변수 등을 저장하기 위해 사용되는 메모리 공간이므로 스택 메모리 공간이 독립적이라는 것은 독립적인 함수 호출이 가능하다는 뜻이고 이는 독립적인 실행 흐름이 추가되는 것이다. 따라서 스레드의 정의에 따라 독립적인 실행 흐름을 추가하기 위한 최소 조건으로 독립된 스택을 할당한다.
PC Register를 스레드마다 독립적으로 할당하는 이유
PC 값은 스레드가 수행한 명령어의 위치를 기억한다. 스레드는 CPU를 할당받았다가 스케줄러에 의해 다시 대기상태가 되기도 한다. 그렇기 때문에 명령어가 연속적으로 수행되지 못하고 어느 부분까지 수행했는지 기억할 필요가 있다. 따라서 PC Register를 독립적으로 할당한다.
멀티 프로세스와 멀티 스레드의 차이점
멀티 프로세스 방식
- 하나의 프로세스가 죽더라도 다른 프로세스에는 영향을 끼치지 않고 정상적으로 수행된다
- 멀티 스레드보다 많은 메모리 공간과 CPU 시간을 차지
멀티 스레드 방식
- stack을 제외한 자원을 공유하기 때문에 멀티 프로세스보다 적은 메모리 공간을 차지
- 빠른 context switching
- 오류로 인해 하나의 스레드가 종료되면 전체 스레드가 종료될 수 있음
- 자원에 대한 동기화 문제가 발생 가능
이 두 가지 방식은 동시에 여러 작업을 수행한다는 점에서 같지만 적용해야 하는 시스템에 따라 적합/부적합이 구분된다. 따라서 대상 시스템의 특징에 따라 적합한 방식을 선택해야 한다.
멀티 프로세스
하나의 응용 프로그램을 여러 개의 프로세스로 구성하여 각 프로세스가 하나의 작업을 처리하는 것
- 여러 개의 자식 프로세스 중 하나에 문제가 발생해도 다른 자식 프로세스에 영향이 확산되지 않음
- 구현이 간단
- 각 프로세스들이 독립적으로 동작하기 때문에 안정적(프로세스마다 독립적인 자원 할당)
- 멀티 스레드보다 많은 메모리 공간과 CPU 시간 차지
- 작업량이 많을수록 오버헤드가 발생하고 Context Switching으로 인한 성능 저하 우려
독립적으로 메모리를 사용하기 때문에 스케줄링에 의해 다른 프로세스가 CPU를 할당 받게 되면 CPU 내 레지스터 값인 이전 프로세스 데이터를 따로 저장한 후에 현재 프로세스의 데이터를 레지스터에 저장해야 하는데 이 과정에서 시스템에 많은 부하가 생긴다.
- 프로세스 간의 통신을 하기 위해서는 IPC를 통해야 함
IPC(Inter Process Communication)
커널 영역에 존재하며, 프로세스 간 통신을 위해서는 공유하는 메모리 공간이 필요하기 때문에 이러한 공유 공간 제공
멀티 스레드
하나의 응용 프로그램을 여러 개의 스레드로 구성하여 각 스레드가 하나의 작업을 처리하도록 하는 것
- 시스템의 자원과 처리 비용 감소(실행 속도 상승)
- Context Switching이 빠름(스레드는 Stack 영역만 처리하면 되기 때문)
- 스레드 간의 자원(Code, Data, Heap)을 공유하고 있기 때문에 통신의 부담이 적어 응답 시간이 빠름
- 스레드가 독립적, 유기적으로 동작하기 때문에 프로그램 테스트, 디버깅이 어려움
- 스레드 간의 데이터 공유 시 동기화 문제 발생
- 하나의 스레드에 오류가 발생하면 전체 프로세스에 문제 발생
- 너무 많은 스레드 사용은 오버헤드 발생
출처
📚 스케줄러(Scheduler)
어떤 프로세스에게 자원을 할당할지 결정하는 운영체제 커널의 모듈
스케줄링의 목표
- CPU 활용 최대화
- 평균 대기시간 최소화
- 처리량 최대화
프로세스 큐
- Job Queue: 현재 시스템 내의 모든 프로세스가 담긴 큐
- Ready Queue: 현재 메모리 내에 적재되어 있으며 CPU를 할당받아 실행되기를 기다리는 프로세스가 담긴 큐
- Device Queue: Device I/O 처리를 기다리는 프로세스가 담긴 큐
스케줄러
- 장기 스케줄러(Long-term scheduler or Job scheduler)
어떤 프로세스에 메모리를 할당하여 ready queue로 보낼지 결정하는 역할
- 많은 프로세스들이 한꺼번에 한정된 메모리에 올라갈 경우, 대용량 메모리(예. 디스크)에 임시로 저장
- 메모리와 디스크 사이의 스케줄링 담당
- 프로세스에 memory(및 각종 리소스)를 할당(admit)
- degree of Multiprogramming 제어 (실행 중인 프로세스의 수 제어)
- 프로세스의 상태: New ▶ Ready
- 단기 스케줄러(Short-term scheduler or CPU scheduler)
Ready Queue 에 존재하는 프로세스(Ready 상태) 중 어떤 프로세스를 running(CPU 할당) 시킬지 결정
- CPU 와 메모리 사이의 스케줄링 담당
- 프로세스에 스케줄링 알고리즘에 따라 CPU 를 할당(scheduler dispatch)
- 프로세스의 상태: Ready ▶ Running ▶ Waiting ▶ Ready
- 중기 스케줄러(Medium-term scheduler or Swapper)
swapping(swap in/swap out): 여유 공간 마련을 위해 프로세스를 통째로 메모리에서 디스크로 쫓아내는 역할
- 프로세스에게서 memory를 deallocate(할당 해제)
- degree of Multiprogramming 제어
- 현 시스템에서 메모리에 너무 많은 프로그램이 동시에 올라가는 것을 조절
- 프로세스의 상태: Ready ▶ Suspended
정리
장기 스케줄러: 메모리-디스크 스케줄링 / New-Ready
중기 스케줄러: CPU-메모리 스케줄링 / Ready-Running-Waiting-Ready
단기 스케줄러: 메모리-디스크 스케줄링 / Ready-Suspended (Swapping)
CPU 스케줄러
선점형 vs 비선점형
선점형 스케줄러
- 하나의 프로세스가 다른 프로세스 대신에 프로세서(CPU)를 차지할 수 있음
- 프로세스 running 중에 스케줄러가 이를 중단시키고 다른 프로세스로 교체 가능
비선점형 스케줄러
- 하나의 프로세스가 끝나지 않으면 다른 프로세스는 CPU를 사용할 수 없음
- 프로세스가 자발적으로 blocking 상태로 들어가거나, 실행이 끝났을 때에만 다른 프로세스로 교체 가능
- 모든 프로세스가 공평한 조건으로 CPU를 사용할 수 있게 해주며, 반응시간 예측 가능
CPU 스케줄러 종류
- FCFS(First Come First Served)
-
비선점형(Non-Preemptive) 스케줄링 방식
-
먼저 도착한 프로세스가 CPU를 먼저 할당받음
-
큐를 이용해 쉽게 구현 가능
-
Convoy effect(콘보이 현상) 발생 가능
콘보이 현상(Convoy effect)
소요시간이 긴 프로세스가 먼저 도달하여 효율성을 낮추는 현상 발생
(CPU를 매우 오래 사용하는 프로세스가 도착하게 되면, 다른 프로세스가 CPU를 사용하는데 기다리는 대기 시간이 매우 커지는 현상)
- SJF(Shortest-Job-First)
- 비선점형(Non-Preemptive) 스케줄링 방식
- 다른 프로세스가 먼저 들어왔어도 수행시간이 짧은 프로세스가 먼저 CPU를 할당받음
- starvation(기아 현상): 공평하지 못함 (수행시간이 긴 프로세스의 경우 계속 대기해야 함)
- SRTF(Shortest Remaining Time First)
- 선점형(Preemptive) 스케줄링 방식
- 새로운 프로세스가 도착할 때마다 새로운 스케줄링
- 현재 수행중인 프로세스의 남은 Burst time보다 더 짧은 시간을 가지는 새로운 프로세스에게 CPU 할당
- starvation과 CPU 사용시간 측정 불가 문제 발생
- Priority Sceduling(우선순위 스케줄링)
선점형(Preemptive) 스케줄링 방식
더 높은 우선순위 프로세스가 도착하면 실행중인 프로세스를 멈추고 CPU를 선점
비선점형(Non-Preemptive) 스케줄링 방식
더 높은 우선순위의 프로세스가 도착하면 Ready Queue의 Head에 넣는다
-
우선순위가 가장 높은 프로세스에게 CPU를 할당하는 스케줄링 방법
-
starvation과 무기한 봉쇄(Indefinite Blocking) 문제 발생
Indefinite Blocking, 무기한 봉쇄
CPU가 실행 준비는 되어있으나 CPU를 사용하지 못하는 프로세스를 계속해서 기다리는 상태
무기한 봉쇄 해결방법: aging
아무리 우선순위가 낮은 프로세스라도 오래 기다리면 우선순위를 높여주자!
- Round Robin
- 현대적인 CPU 스케줄링 방식
- 각 프로세스는 동일한 크기의 할당 시간(time quantum)을 갖고, 할당 시간이 지나면 프로세스는 선점당하고 ready queue의 제일 뒤에서 대기
- CPU 사용시간이 랜덤한 프로세스들이 섞여있을 경우 효율적
- 공정한 스케줄링
- 적당한 time quantum이 필요
출처
- https://technote-mezza.tistory.com/71?category=916578
- https://dheldh77.tistory.com/entry/%EC%9A%B4%EC%98%81%EC%B2%B4%EC%A0%9C-%EC%8A%A4%EC%BC%80%EC%A4%84%EB%9F%ACScheduler
📚 동기와 비동기
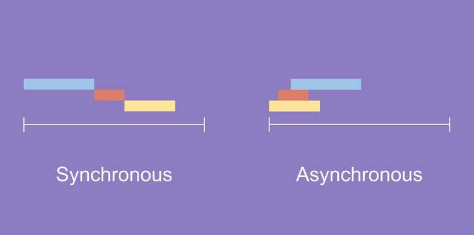
동기(Synchronous)
데이터의 요청과 결과가 한 자리에서 동시에 일어남
- 요청을 하면 요청한 자리에서 결과가 주어져야 함
- 사용자가 데이터를 서버에 요청한다면 서버에게 요청에 따른 응답을 받기 전까지 사용자는 다른 활동을 할 수 없음
비동기(Asynchronous)
데이터의 요청과 결과가 동시에 일어나지 않음
- 요청한 결과가 동시에 주어지지 않음
- 서버에게 데이터를 요청한 후 응답을 기다리며 다른 활동 수행과 다른 요청이 가능
👀 동시란?
요청에 대한 응답을 받기 전가지 blocking 상태
📚 프로세스 동기화
Critical Section(임계 영역)
동일한 자원을 동시에 접근하는 작업(e.g. 공유하는 변수 사용, 동일 파일을 사용하는 등)을 실행하는 코드 영역
임계 영역 문제
임계 구역으로 지정되어야 할 코드 영역이 임계 구역으로 지정되지 않았을 때 발생할 수 있는 문제
임계 영역 문제를 해결하기 위한 조건
-
상호 배제(Mutual Exclusion): 임계 영역에는 하나의 프로세스만 진입 가능
프로세스 P1이 Critical Section에 진입해있는 상태라면 다른 프로세스들은 Critical Section에 접근할 수 없음 -
진행(Progress)
임계 영역에 들어간 프로세스가 없는 상태에서 진입을 시도하는 프로세스가 여러 개라면 어느 프로세스가 진입할지 결정되어야 함 -
한정 대기(Bounded Waiting): 대기 시간이 유한
다른 프로세스의 Starvation(기아, 오랜 시간동안 CPU 할당받지 못한 상태)을 방지하기 위해 임계 영역에 진입했던 프로세스는 다음 진입 시도에서 제한
해결 방법
Mutex Lock
임계 영역에 진입하는 프로세스는 lock를 획득하고 임계 영역을 빠져나올 때 lock을 반납하는 방식으로, lock을 획득한 프로세스만 임계 영역에 진입할 수 있도록 한다.
- bool 값을 통한 무한루프(busy-waiting)를 통해 lock 구현 가능
Semaphores(세마포어)
내부 구조
- 정수형 변수 S: 자원의 개수 = 임계 영역에 진입 가능한 프로세스 수
- 동작 P(시도): 임계 구역 진입 시도
- 동작 V(증가): 자원 반납을 알려 대기중인 프로세스를 깨움
Binary semaphore(이진 세마포어)
- S가 0과 1 중 하나의 값만 가짐
- 상호배제나 프로세스 동기화의 목적으로 사용
- Mutex와 유사
Counting semaphore(카운팅 세마포어)
- S가 0 이상의 정수 값을 가질 수 있음
- Producer-Consumer 문제 등을 해결하기 위해 사용
뮤텍스와 세마포어의 차이점
- 세마포어는 뮤텍스가 될 수 있지만 뮤텍스는 세마포어가 될 수 없음
- 세마포어는 소유권이 없지만 뮤텍스는 lock의 소유가 가능하며 소유한 프로세스가 책임을 짐
- 현재 수행중인 프로세스가 아닌 다른 프로세스가 세마포어를 해제할 수 있지만 뮤텍스는 lock을 소유한 프로세스가 반드시 lock을 해제해야 함
- 세마포어는 시스템 범위에 걸쳐있고 파일 시스템 상의 파일 형태로 존재하지만 뮤텍스는 프로세스 범위를 가지며 프로세스가 종료될 때 자동으로 clean up 된다.
- 세마포어는 자원의 수만큼 프로세스가 임계영역에 접근할 수 있지만 뮤텍스는 오직 1개의 프로세스만 접근 가능
출처
- https://dduddublog.tistory.com/25
- https://pongsi.tistory.com/entry/OS-%ED%94%84%EB%A1%9C%EC%84%B8%EC%8A%A4-%EB%8F%99%EA%B8%B0%ED%99%94%EC%84%B8%EB%A7%88%ED%8F%AC%EC%96%B4-%EB%AA%A8%EB%8B%88%ED%84%B0-%EC%9E%84%EA%B3%84%EA%B5%AC%EC%97%AD
여기부터 다시 공부!
📚 메모리 관리 전략
메모리 관리 배경
각각의 프로세스 는 독립된 메모리 공간을 갖고, 운영체제 혹은 다른 프로세스의 메모리 공간에 접근할 수 없는 제한이 걸려있다. 단지, 운영체제 만이 운영체제 메모리 영역과 사용자 메모리 영역의 접근에 제약을 받지 않는다.
Swapping
메모리의 관리를 위해 사용되는 기법
표준 Swapping 방식으로는 round-robin 과 같은 스케줄링의 다중 프로그래밍 환경에서 CPU 할당 시간이 끝난 프로세스의 메모리를 보조 기억장치(e.g. 하드디스크)로 내보내고 다른 프로세스의 메모리를 불러 들일 수 있다.
- swap-in: 주 기억장치(RAM)으로 불러오는 과정
- swap-out: 보조 기억장치로 내보내는 과정
단편화 (Fragmentation)
프로세스들이 메모리에 적재되고 제거되는 일이 반복되다보면, 프로세스들이 차지하는 메모리 틈 사이에 사용하지 못할 만큼의 작은 자유공간 증가
- 외부 단편화: 메모리 공간 중 사용하지 못하게 되는 일부분. 물리 메모리(RAM)에서 사이사이 남는 공간들을 모두 합치면 충분한 공간이 되는 부분들이 분산되어 있을때 발생한다고 볼 수 있다.
- 내부 단편화: 프로세스가 사용하는 메모리 공간 에 포함된 남는 부분. 예를들어 메모리 분할 자유 공간이 10,000B 있고 Process A 가 9,998B 사용하게되면 2B 라는 차이 가 존재하고, 이 현상을 내부 단편화라 칭한다.
압축
외부 단편화를 해소하기 위해 프로세스가 사용하는 공간들을 한쪽으로 몰아, 자유공간을 확보하는 방법
- 단점: 작업효율이 좋지 않다.
Paging(페이징)
하나의 프로세스가 사용하는 메모리 공간이 연속적이어야 한다는 제약을 없애는 메모리 관리 방법
-
외부 단편화와 압축 작업을 해소 하기 위해 생긴 방법
-
물리 메모리는 Frame 이라는 고정 크기로 분리되어 있고, 논리 메모리(프로세스가 점유하는)는 페이지라 불리는 고정 크기의 블록으로 분리됨.(페이지 교체 알고리즘에 들어가는 페이지)
-
장점: 페이징 기법을 사용함으로써 논리 메모리는 물리 메모리에 저장될 때, 연속되어 저장될 필요가 없고 물리 메모리의 남는 프레임에 적절히 배치됨으로 외부 단편화를 해결 가능
-
단점 : 내부 단편화 문제의 비중이 늘어나게 됨
예를들어 페이지 크기가 1,024B 이고 프로세스 A 가 3,172B 의 메모리를 요구한다면 3 개의 페이지 프레임(1,024 * 3 = 3,072) 하고도 100B 가 남기때문에 총 4 개의 페이지 프레임이 필요한 것이다. 결론적으로 4 번째 페이지 프레임에는 924B(1,024 - 100)의 여유 공간이 남게 되는 내부 단편화 문제가 발생하는 것이다.
Segmentation(세그멘테이션)
페이징에서처럼 논리 메모리와 물리 메모리를 같은 크기의 블록이 아닌, 서로 다른 크기의 논리적 단위인 세그먼트(Segment)로 분할 사용자가 두 개의 주소로 지정(세그먼트 번호 + 변위) 세그먼트 테이블에는 각 세그먼트의 기준(세그먼트의 시작 물리 주소)과 한계(세그먼트의 길이)를 저장
- 단점 : 서로 다른 크기의 세그먼트들이 메모리에 적재되고 제거되는 일이 반복되다 보면, 자유 공간들이 많은 수의 작은 조각들로 나누어져 못 쓰게 될 수도 있다.(외부 단편화)
가상 메모리
다중 프로그래밍을 실현하기 위해서는 많은 프로세스들을 동시에 메모리에 올려두어야 한다. 가상메모리는 프로세스 전체가 메모리 내에 올라오지 않더라도 실행이 가능하도록 하는 기법 이며, 프로그램이 물리 메모리보다 커도 된다는 주요 장점이 있다.
가상 메모리 개발 배경
실행되는 코드의 전부를 물리 메모리에 존재시켜야 했고, 메모리 용량보다 큰 프로그램은 실행시킬 수 없었다. 또한, 여러 프로그램을 동시에 메모리에 올리기에는 용량의 한계와, 페이지 교체등의 성능 이슈가 발생하게 된다. 또한, 가끔만 사용되는 코드가 차지하는 메모리들을 확인할 수 있다는 점에서, 불필요하게 전체의 프로그램이 메모리에 올라와 있어야 하는게 아니라는 것을 알 수 있다.
가상 메모리가 하는 일
가상 메모리는 실제의 물리 메모리 개념과 사용자의 논리 메모리 개념을 분리한 것으로 정리할 수 있다. 이로써 작은 메모리를 가지고도 얼마든지 큰 가상 주소 공간을 프로그래머에게 제공할 수 있다.
가상 주소 공간
한 프로세스가 메모리에 저장되는 논리적인 모습을 가상메모리에 구현한 공간이다. 프로세스가 요구하는 메모리 공간을 가상메모리에서 제공함으로써 현재 직접적으로 필요치 않은 메모리 공간은 실제 물리 메모리에 올리지 않는 것으로 물리 메모리를 절약할 수 있다.
예를 들어, 한 프로그램이 실행되며 논리 메모리로 100KB 가 요구되었다고 하자. 하지만 실행까지에 필요한 메모리 공간(Heap영역, Stack 영역, 코드, 데이터)의 합이 40KB 라면, 실제 물리 메모리에는 40KB 만 올라가 있고, 나머지 60KB 만큼은 필요시에 물리메모리에 요구한다고 이해할 수 있겠다.
Demand Paging(요구 페이징)
프로그램 실행 시작 시에 프로그램 전체를 디스크에서 물리 메모리에 적재하는 대신, 초기에 필요한 것들만 적재하는 전략을 요구 페이징이라 하며, 가상 메모리 시스템에서 많이 사용된다. 그리고 가상 메모리는 대개 페이지로 관리된다. 요구 페이징을 사용하는 가상 메모리에서는 실행과정에서 필요해질 때 페이지들이 적재된다. 한 번도 접근되지 않은 페이지는 물리 메모리에 적재되지 않는다.
프로세스 내의 개별 페이지들은 페이저(pager)에 의해 관리된다. 페이저는 프로세스 실행에 실제 필요한 페이지들만 메모리로 읽어 옮으로써, 사용되지 않을 페이지를 가져오는 시간낭비와 메모리 낭비를 줄일 수 있다.
Page fault trap(페이지 부재 트랩)
페이지 교체
요구 페이징 에서 언급된대로 프로그램 실행시에 모든 항목이 물리 메모리에 올라오지 않기 때문에, 프로세스의 동작에 필요한 페이지를 요청하는 과정에서 page fault(페이지 부재)가 발생하게 되면, 원하는 페이지를 보조저장장치에서 가져오게 된다. 하지만, 만약 물리 메모리가 모두 사용중인 상황이라면, 페이지 교체가 이뤄져야 한다.(또는, 운영체제가 프로세스를 강제 종료하는 방법이 있다.)
기본적인 방법
물리 메모리가 모두 사용중인 상황에서의 메모리 교체 흐름이다.
- 디스크에서 필요한 페이지의 위치를 찾는다
- 빈 페이지 프레임을 찾는다.
- 페이지 교체 알고리즘을 통해 희생될(victim) 페이지를 고른다.
- 희생될 페이지를 디스크에 기록하고, 관련 페이지 테이블을 수정한다.
- 새롭게 비워진 페이지 테이블 내 프레임에 새 페이지를 읽어오고, 프레임 테이블을 수정한다.
- 사용자 프로세스 재시작
페이지 교체 알고리즘
FIFO 페이지 교체
가장 간단한 페이지 교체 알고리즘으로 FIFO(first-in first-out)의 흐름을 가진다. 즉, 먼저 물리 메모리에 들어온 페이지 순서대로 페이지 교체 시점에 먼저 나가게 된다는 것이다.
- 장점: 이해하기도 쉽고, 프로그램하기도 쉽다.
- 단점: 오래된 페이지가 항상 불필요하지 않은 정보를 포함하지 않을 수 있다(초기 변수 등).
처음부터 활발하게 사용되는 페이지를 교체해서 페이지 부재율을 높이는 부작용을 초래할 수 있다.
Belady의 모순: 페이지를 저장할 수 있는 페이지 프레임의 갯수를 늘려도 되려 페이지 부재가 더 많이 발생하는 모순이 존재한다.
최적 페이지 교체(Optimal Page Replacement)
Belady의 모순을 확인한 이후 최적 교체 알고리즘에 대한 탐구가 진행되었고, 모든 알고리즘보다 낮은 페이지 부재율을 보이며 Belady의 모순이 발생하지 않는다. 이 알고리즘의 핵심은 앞으로 가장 오랫동안 사용되지 않을 페이지를 찾아 교체하는 것이다. 주로 비교 연구 목적을 위해 사용한다.
- 장점: 알고리즘 중 가장 낮은 페이지 부재율을 보장한다.
- 단점:
- 구현의 어려움이 있다.
- 모든 프로세스의 메모리 참조의 계획을 미리 파악할 방법이 없기 때문이다.
LRU 페이지 교체(LRU Page Replacement)
LRU: Least-Recently-Used
최적 알고리즘의 근사 알고리즘으로, 가장 오랫동안 사용되지 않은 페이지를 선택하여 교체한다.
- 특징
대체적으로 FIFO 알고리즘보다 우수하고, OPT알고리즘보다는 그렇지 못한 모습을 보인다.
LFU 페이지 교체(LFU Page Replacement)
LFU: Least Frequently Used
참조 횟수가 가장 적은 페이지를 교체하는 방법이다. 활발하게 사용되는 페이지는 참조 횟수가 많아질 거라는 가정에서 만들어진 알고리즘이다.
- 특징
어떤 프로세스가 특정 페이지를 집중적으로 사용하다, 다른 기능을 사용하게되면 더 이상 사용하지 않아도 계속 메모리에 머물게 되어 초기 가정에 어긋나는 시점이 발생할 수 있다
최적(OPT) 페이지 교체를 제대로 근사하지 못하기 때문에, 잘 쓰이지 않는다.
MFU 페이지 교체(MFU Page Replacement)
MFU: Most Frequently Used
참조 회수가 가장 작은 페이지가 최근에 메모리에 올라왔고, 앞으로 계속 사용될 것이라는 가정에 기반한다.
- 특징
최적(OPT) 페이지 교체를 제대로 근사하지 못하기 때문에, 잘 쓰이지 않는다.
