
👩🏻🤝👩🏻 ReplicaSet
컨트롤러는 쿠버네티스의 두뇌를 담당하여 쿠버네티스 오브젝트를 모니터링하고 반응하는 프로세스이다.
Replication Controller
복제 컨트롤러에 대해 이야기 해보자!
Replica란 무엇이고, Replication Controller는 왜 필요한걸까?
애플리케이션을 실행하는 단일 파드가 있다고 가정한다.
어떤 이유로 애플리케이션과 파드가 죽게 되면 사용자는 더이상 애플리케이션에 접근할 수 없다.
따라서 사용자의 애플리케이션 접근 권한을 보장하기 위해 동시에 실행되는 둘 이상의 파드를 동작시킬 수 있다.
1) 고가용성 (High Availability)
복제 컨트롤러는 쿠버네티스 클러스터에서 파드의 여러 인스턴스를 실행할 수 있도록 고가용성을 제공한다.

여러 개의 파드가 아닌 하나의 파드만 유지하기 위해서도 복제 컨트롤러를 사용할 수 있다.
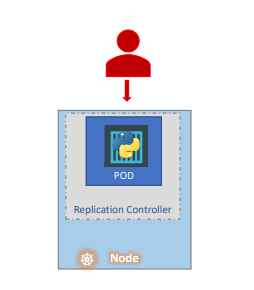
이경우에는 기존 파드에 문제가 발생하면 복제 컨트롤러가 자동으로 새 파드를 생성해준다.
😎 따라서 복제 컨트롤러는 특정 파드가 항상 실행되도록 보장해준다
2) 로드 밸런싱 & 스케일링 (Load Balancing & Scaling)
복제 컨트롤러는 부하를 분산하기 위해 여러 파드를 생성해준다.
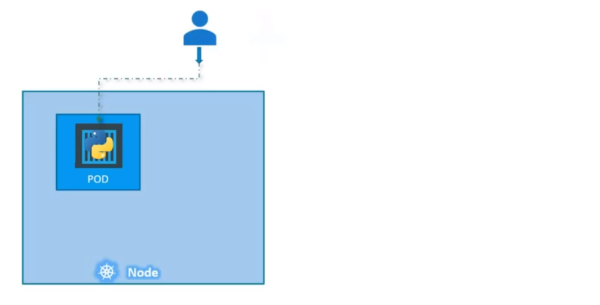
사용자에게 서비스를 제공하는 하나의 애플리케이션 파드가 있다.
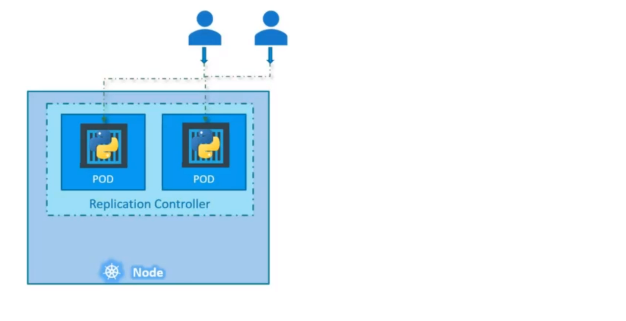
사용자 수가 증가하면 파드를 추가하여 로드밸런싱을 수행한다.
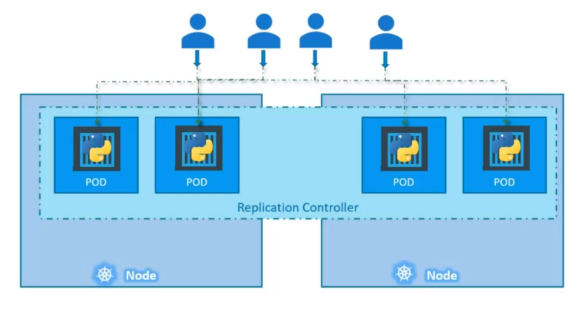
파드의 증가로 해당 노드의 리소스가 부족해지면 클러스터의 다른 노드에 파드를 추가로 배포한다.
복제 컨트롤러는 클러스터 내의 노드들에 걸쳐있기 때문에 여러 노드에서 파드와 애플리케이션 로드 밸런싱과 오토 스케일링에 도움을 줄 수 있다.
Replication Controller와 Replica Set
복제 컨트롤러와 레플리카셋의 용도는 같다. 그러나 차이점이 존재한다.
복제 컨트롤러
복제 컨트롤러 기술이 더 오래된 기술이며, 레플리카셋에 의해 대체되었다.
레플리카 셋
레플리카셋은 복제를 설정하는 새로운 권장 방법이다.
ReplicaController 생성
1) YAML 파일 생성
vim rc-definition.yaml2) 4개의 필수 요소 작성
apiVersion: v1
kind: ReplicationController
metadata:
name: myapp-rc
labels:
app: myapp
type: front-end
spec:
template:
# 무슨 내용이 들어가야 할까?spec
spec 부분은 오브젝트 내부에 무엇이 있는지 정의한다.
현재 ReplicaController를 생성하고 있으므로, 생성할 복제 컨트롤러가 관리하는데 필요한 파드의 template를 정의하면 된다.
spec:
template:
metadata:
name: myapp-pod
labels:
app: myapp
type: front-end
spec:
containers:
- name: nginx-container
image: nginx
replicas: 33) 파일 저장
esc를 누른 후 wq 커맨드로 파일을 저장한다.
- w : 쓰기 작업 저장
- q : 나가기
4) 오브젝트 생성
yaml 파일을 적용하여 ReplicaController를 생성한다.
kubectl create -f rc-definition.yaml
복제 컨트롤러가 생성되면서 설정한 개수(3)의 파드가 함께 생성된다.
kubectl get replicationcontroller
kubectl get pods

🤷♀️ create와 apply의 차이?
리소스가 존재하지 않을 경우에는 차이가 없지만 리소스가 이미 존재할 경우 create 명령에서 error가 발생하고, apply 명령은 업데이트가 된다.
ReplicaSet 생성
1) YAML 파일 생성
vim replicaset-definition.yaml2) 4개의 필수 요소 작성
apiVersion: v1이 아닌app/v1으로 작성해야 한다. v1으로 작성하면 에러가 발생한다. (레플리카 셋은app/v1버전으로 생성 가능하다.)kind:ReplicaSetmetadata: 파드의 이름과 label을 설정한다.spec: Replica Controller와 유사하게 template을 작성해주어야 한다.template: 복제할 pod의 템플릿이 들어가며, 템플릿 아래에는metadata와spec이 들어간다.replicas: 복제본 수- ✨
selector: ReplicaSet에는selector부분을 꼭 작성해주어야 한다.
selector
selector 섹션은 어떤 파드가 ReplicaSet 아래에 있는지 식별하는 역할을 한다.
selector의 하위 항목에는 matchLabels 속성이 있다.
matchLabels는 파드의 labels와 매칭되는 정보이다. 이 속성은 지정된 라벨과 같은 라벨을 가진 파드를 연결한다.
apiVersion: app/v1
kind: ReplicaSet
metadata:
name: myapp-replicaset
labels:
app: myapp
type: front-end
spec:
template:
metadata:
name: myapp-pod
labels:
app: myapp
type: front-end
spec:
containers:
- name: nginx-continaer
image: nginx
replicas: 3
selector:
matchLabels:
type: front-end3) 파일 저장
esc를 누른 후 wq 커맨드로 파일을 저장한다.
- w : 쓰기 작업 저장
- q : 나가기
4) 오브젝트 생성
yaml 파일을 적용하여 ReplicaController를 생성한다.
kubectl create -f replicaset-definition.yaml
레플리카 셋이 생성되면서 설정한 개수(3)의 파드가 함께 생성된다.
kubectl get replicaset
kubectl get pods

Label과 Selector
labels와 selector 속성은 무엇이고, labels를 지정하는 이유는 무엇일까?
ReplicaSet의 역할은 파드를 모니터링하고, 파드가 존재하지 않거나 관리하고 있는 파드에 문제가 생기면 새 파드를 배포함으로써 복제본 수를 유지한다.
그렇다면 ReplicaSet은 어떤 파드를 모니터링 해야 할지 알고 있어야 한다. 바로 여기서 파드의 labels가 사용된다.
labels는ReplicaSet에 대한 필터 역할을 한다.
결론
selector의 matchLabels에 기입된 label과 관리할 대상 파드의 labels를 일치시켜, 해당 label을 가지고 있는 pod를 대상으로 모니터링하고, 관리할 수 있다.
복제본 수 관리 방법
1) YAML 변경
- yaml 파일 내용 변경
replicas항목 값을 변경해준다. (3 -> 6)
apiVersion: app/v1
kind: ReplicaSet
metadata:
name: myapp-replicaset
labels:
app: myapp
type: front-end
spec:
template:
...
replicas: 6
selector:
matchLabels:
type: front-end- ReplicaSet 업데이트
아래 명령어로ReplicaSet의 구성이 변경되어 업데이트 된다.
kubectl replace -f replicaset-definition.yaml
kubectl apply -f replicaset-definition.yaml2) YAML 내용을 scale 커맨드로 변경
kubectl scale --replicas=6 -f replicaset-definition.yamlscale 커맨드를 통해 구성 파일 내의 replica의 수를 업데이트 할 수 있다.
3) scale 커맨드로 직접 변경
kubectl scale --replicas=6 replicaset myapp-replicaset구성 파일 내용은 변경되지 않지만 오브젝트 타입(ReplicaSet)과 오브젝트 이름(myapp-replicaset)을 직접 기입하여 레플리카 수를 변경할 수 있다.

💻 Deployment
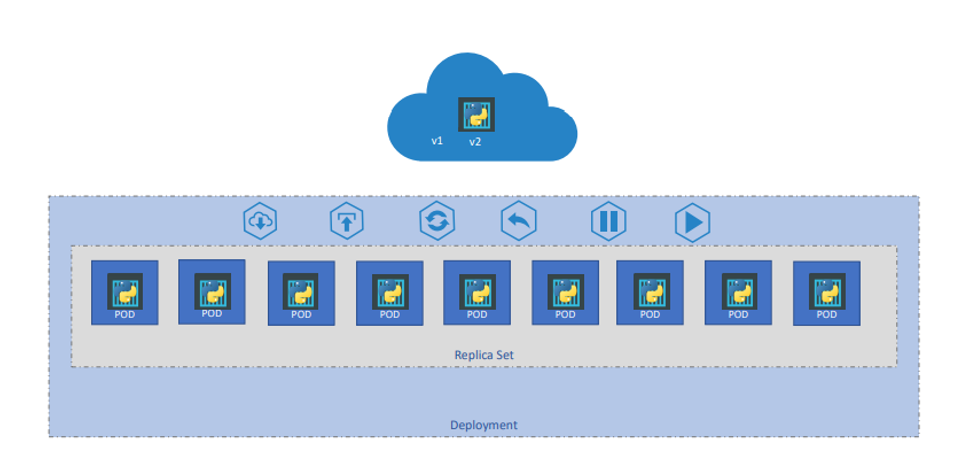
- 배포해야 할 웹 서버가 있고, 웹 서버의 인스턴스가 많이 필요한 상황이다.
- 애플리케이션의 새로운 버전이 나올 때마다 인스턴스를 원활하게 업그레이드 하기를 원한다.
- 롤링 업데이트 : 인스턴스 전체를 한번에 업그레이드 하지 않고 하나씩 업그레이드 하고자 한다.
- 롤백 : 업그레이드 중 오류가 발생하면, 최근 변경사항을 원래의 상태로 되돌려야 할 수 있다.
이러한 요구사항을 쿠버네티스의 Deployment를 사용하여 만족할 수 있다.

Deployment는 원활한 업그레이드를 통해 롤링 업데이트 사용, 롤백, 중지, 재개하는 기능을 제공한다.
롤아웃 상태 보기
kubectl rollout status deployment/myapp-deployment
# 결과
Waiting for rollout to finish: 1 out of 3 new replicas have been updated...롤아웃 기록 확인하기
kubectl rollout history deployment/myapp-deployment
# 결과
deployments "nginx-deployment"
REVISION CHANGE-CAUSE
1 kubectl apply --filename=https://k8s.io/examples/controllers/nginx-deployment.yaml
2 kubectl set image deployment/nginx-deployment nginx=nginx:1.16.1
3 kubectl set image deployment/nginx-deployment nginx=nginx:1.161이전 단계로 롤백하기
kubectl rollout undo deployment/nginx-deployment
# 결과
deployment.apps/nginx-deployment rolled back특정 단계로 롤백하기
kubectl rollout undo deployment/nginx-deployment --to-revision=2
# 결과
deployment.apps/nginx-deployment rolled back레플리카 수 늘리기 (확장)
kubectl scale deployment/nginx-deployment --replicas=10
# 결과
deployment.apps/nginx-deployment scaled디플로이 생성
1) 구성 파일 작성
텍스트 편집기를 통해 구성 파일을 작성한다.
vim deployment-definition.yamlkind 항목만 제외하면 ReplicaSet과 작성 방법이 똑같다.
apiVersion: app/v1
kind: Deployment
metadata:
name: myapp-deployment
labels:
app: myapp
type: front-end
spec:
template:
metadata:
name: myapp-pod
labels:
app: myapp
type: front-end
spec:
containers:
- name: nginx-continaer
image: nginx
replicas: 3
selector:
matchLabels:
type: front-endDeployment는 ReplicaSet보다 더 높은 계층 구조에 위치하며, Deployment를 생성하면 ReplicaSet이 자동으로 생성된다.
2) 디플로이 생성
kubectl create -f deployment-definition.yaml
디플로이를 생성하면 replicaset과 pod가 함께 생성된다.
kubectl get deployments
kubectl get replicaset
kubectl get pods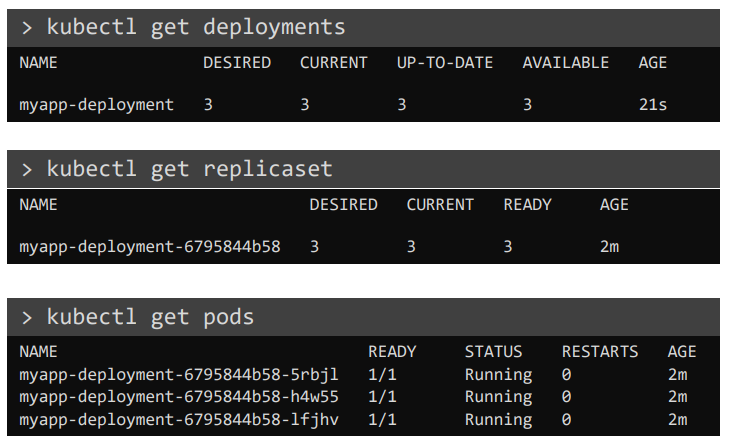
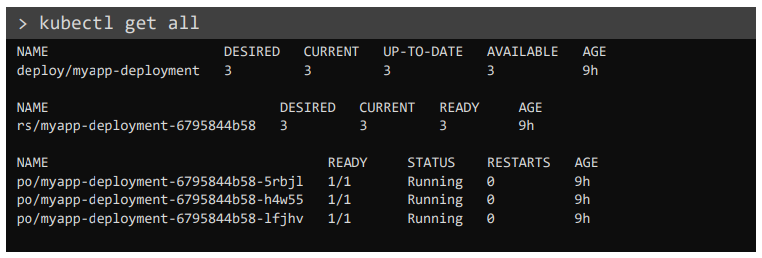
모든 오브젝트를 한번에 보는 커맨드
kubectl get all
💯 Certification Tip!
yaml 파일을 생성하고 편집하는 것이 다소 어려울 수 있다. 또한 시험 중 yaml 파일 복사, 붙여넣기가 불편할 수 있다.
이때 kubectl run 커맨드를 사용하면 yaml 파일 템플릿을 생성하는데 도움이 된다.
Create an NGINX pod
kubectl run nginx --image=nginxGenerate POD Manifest YAML file (-o yaml). Don't create it(--dry-run)
kubectl run nginx --image=nginx --dry-run=client -o yamlCrate a deployment
kubectl create deployment --image=nginx nginxGenerate Deployment Yaml file (-o yaml). Don't create it(--dry-run)
kubectl create deployment --image=nginx nginx --dry-run=client -o yamlGenerate Deployment Yaml file (-o yaml). Don't create it(--dry-run) with 4 Replicas (--replicas=4)
- 방법 1
kubectl create deployment --image=nginx nginx --dry-run=client -o yaml > nginx-deployment.yaml커맨드를 입력한 후 ls를 입력하면 nginx-deployment.yaml 파일이 생성된 것을 확인할 수 있다.
텍스트 편집기로 파일을 열어(vim nginx-deployment.yaml) replicas 항목 값을 4로 설정한다.
설정 후 디플로이를 생성한다
kubectl create -f nginx-deployment.yaml- 방법 2
kubectl create deployment --image=nginx nginx --replicas=4 --dry-run=client -o yaml > nginx-deployment.yamlk8s의 버전 중 1.19 이상의 버전에서는 --replicas 옵션으로 replicas 값을 설정할 수 있다.
🔊 Services
쿠버네티스의 Services는 내부 구성요소 간, 외부에 있는 애플리케이션과 통신할 수 있게 해주는 역할을 한다.
예를 들어, 애플리케이션이 프론트엔드 그룹, 백엔드 그룹, 데이터 그룹으로 구성되어 있다고 생각해보자!
이러한 파드 그룹을 연결해주는 것이 Service이다.
Service를 통해 사용자가 애플리케이션의 프론트엔드에 접근할 수 있고, 백엔드와 프론트엔드 파드가 통신할 수 있으며, 외부 데이터 베이스와 연결할 수 있다.
External Communication
웹 애플리케이션 파드를 배포할 경우, 외부에서 사용자가 웹페이지에 접속하는 방법은 무엇일까?
기본 설정을 살펴보자!
- 파드가 속해있는 worker node의 IP 주소는
192.168.1.2이다. - 현재 사용자의 노트북 또한 같은 네트워크 상에 있으며, IP 주소는
192.168.1.10이다. - 노드의 내부에 생성되는 파드 IP의 네트워크 주소는
10.244.0.0이다. - 접속하려는 파드의 IP는
10.244.0.2이다.
현재 사용자의 IP 주소와 파드의 IP는 다른 네트워크 주소를 가지므로, ping을 보내거나 접속할 수 없다.
이 경우, 쿠버네티스 노드와 SSH 연결을 통해 curl이나 노드 내에서 웹페이지 내용을 확인할 수 있다.
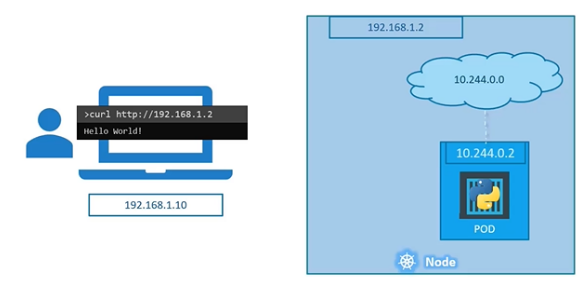
그러나 이 방법은 쿠버네티스 노드 내부에서 파드에 접근하는 것이므로, 사용자의 노트북에서 파드에 접속할 수 있는 다른 방법을 선택해야 한다.
따라서 노트북->노드, 노드->파드로 노트북에서 보낸 요청을 파드로 전달해주어야 하는데 이 역할을 하는 것이 쿠버네티스의 Service이다.
Service Type
쿠버네티스에는 3가지 타입의 Service가 존재한다.
1) NodePort
노드 포트로 내부의 파드 포트에 접근가능하게 하는 서비스
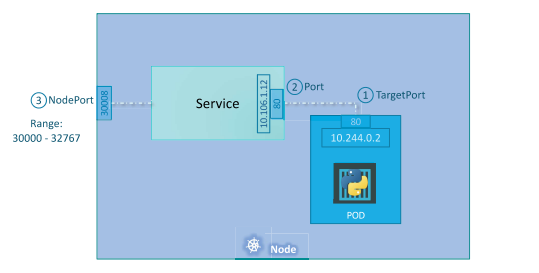
TargetPort: 실제 접속하려는 파드의 포트, Service가 최종적으로 요청을 전달하는 포트Port: 서비스 자체의 포트, 라고 부른다. 서비스는 노드 내의 가상 서버와 같으며,ClusterIP:Port로 들어온 요청을TargetPort로 전달한다.NodePort: 외부에서 내부 파드에 액세스하기 위해 사용할 포트, 노드포트는 30000~32767 사이의 범위에서 값을 가짐
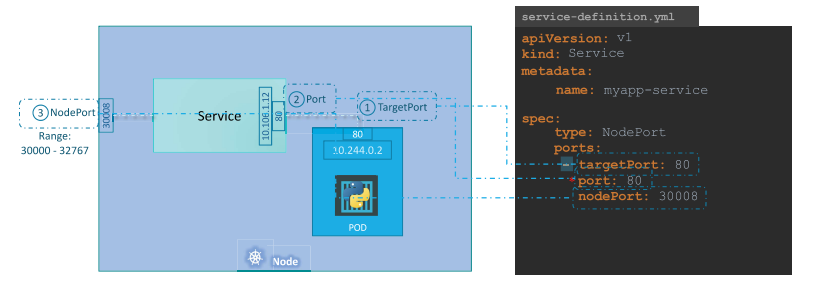
서비스 생성 방법
1) 구성 파일 작성
vim service-definition.yml구성파일 내용
- apiVersion: v1
- kind: Service
- metadata: 이름과 라벨 등 서비스에 대한 정보
- spec: 서비스 역할을 정의하는 부분
- type: 서비스 타입 (
NodePort,ClusterIP,LoadBalancer) - ports: 포트 관련 정보, 리스트 형태로 여러 개의 포트 매핑을 가진다.
- targetPort : 실제 파드 포트
- port : 서비스 오브젝트 포트
- nodePort : 노드 포트 (값을 입력하지 않으면 범위 내에서 자동으로 할당됨)
- selector : 연결할 파드의 label과 같은 label을 설정하여 매핑
- type: 서비스 타입 (
apiVersion: v1
kind: Service
metadata:
name: myapp-service
spec:
type: NodePort
ports:
- targetPort: 80
port: 80
nodePort: 30008
selector:
app: myapp
type: front-end2) 서비스 오브젝트 생성
- 구성 파일을 적용하여 서비스 생성
kubectl create -f service-definition.yml
- 서비스 오브젝트가 생성되었는지 확인
kubectl get services
curl커맨드를 통해 애플리케이션 내용 확인
curl http://192.168.1.2:30008
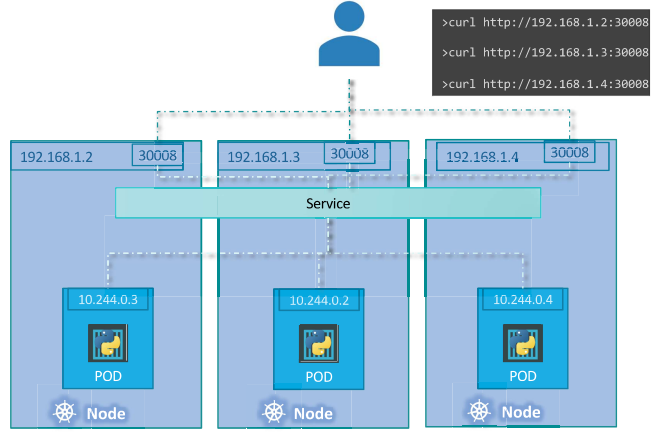
만약 동일한 애플리케이션이 동작하는 3개의 파드가 있고, 이 파드들이 동일한 label을 가지고 있을 경우에는 Service가 랜덤 알고리즘으로 요청을 전달할 파드를 선택하여 로드 밸런싱을 한다.
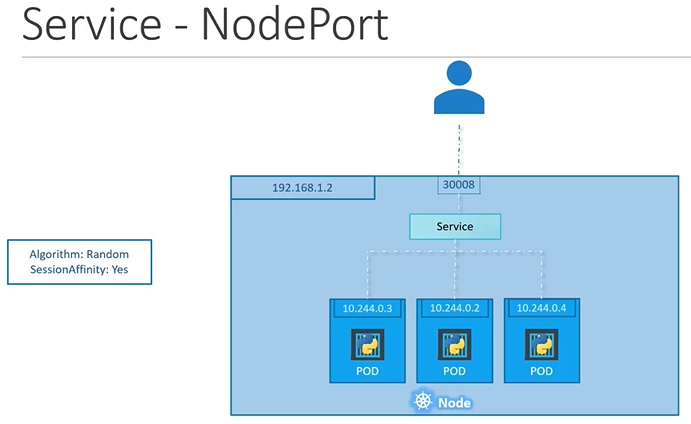
파드가 여러 노드에 분산되어 있는 경우, 서비스가 생성될 때 쿠버네티스가 자동으로 클러스터의 모든 노드에 대상 파드의 포트를 매핑한다.
이때 매핑된 노드 포트들은 모두 동일하다.
어떤 경우든지 파드가 추가되거나 삭제되면 서비스는 자동으로 업데이트 되어 새로운 파드로 요청을 전달해준다.
2) ClusterIP
ClusterIP 서비스는 서로 다른 서비스 간 통신이 가능하도록 클러스터 안에 Virtual IP를 생성한다.
3) LoadBalancer
loadBalancer 서비스는 파드들의 부하 분산 기능을 제공한다.
