
📌(선형)SVM - 목적
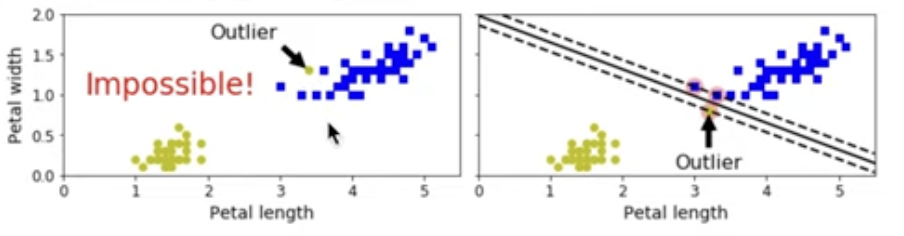
support vector = 데이터의 경계와 가장 가까이 있는 데이터. 경계를 정의한다.
데이터를 가장 잘 분류하는 Hyperplane을 찾자.
= Margin이 최대가 되는 Hyperplane을 찾자.
- Margin ? = support vector 사이의 거리.
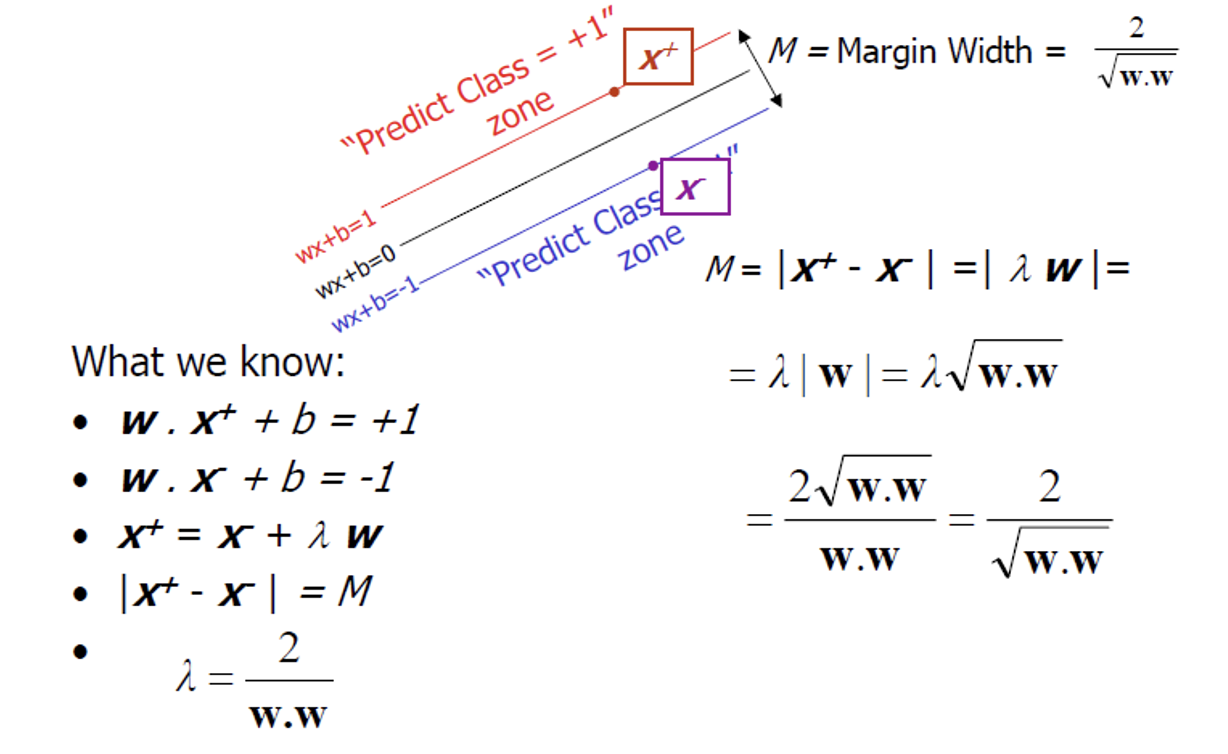
Margin 구하는 과정
1. 점과 직선사이의 거리
2. 벡터 이용

결정함수
Feature space를 2개로 분할한다.
Soft Margin, Hard Margin
Hard Margin : 모든 샘플이 올바르게 분류되도록 Margin을 설정하는 방식(Margin이 작음)
- 문제점 1. 데이터가 선형적으로 구분될 수 있어야 한다. 2. 이상치에 민감하다.
Soft Margin : 샘플 분류의 오류를 허용하고 Margin를 가능한 넓게 설정하는 방식(과적합 방지 및 오류에 덜 민감)
- (code) Hyperparameter C : Margin을 조절할 수 있다. C가 작을수록 soft하게 분류한다.
*SVM은 특성의 스케일에 민감하다. 따라서 Scaling하면 결정 경계가 좋아진다.
📌 비선형 SVM
선형적으로 분류할 수 없는 비선형 데이터에 대해 polynomial특성을 추가한 것
= Input Space(비선형)를 Feature Space(선형)으로 mapping function을 통해 변환한다.
- 문제점 *
- mapping function을 정의하기 어렵다
- mapping function을 풀기에 연산량이 너무 많다.
-> kernel이 고차원 변환 및 연산량 문제를 해결하게 하자.
추가할 수 있는 특성
- polynomial kernel
다항식 특성을 추가하는 것
- 낮은 차수의 다항식은 복잡한 데이터셋을 잘 표현하지 못하고, 높은 차수의 다항식은 특성 조합에 의해 많은 특성이 추가되어 모델이 부적합하게 만든다.
- b : 다항식의 계수, d : 다항식의 차수
- kernel trick
실제로는 특성을 추가하지 않으면서 다항식 특성을 추가한 것과 비슷한 효과 내는 것
- 실제로 특성이 추가되었지 않아서 엄청난 수의 특성 조합이 생기지 않는다.
- RBF kernel
각 샘플이 특정 landmark와 얼마나 닮았는지 유사도를 특성으로 추가하는 것
- landmark와 멀수록 0, 일치하면 1
- gaussian RBF kernel
exp(gamma ||x-l||^2 ) = (ㅣ2 norm)^2, 랜드마크에 가까울수록 영향력이 커지게 된다.
gamma? = 증가시키면 종모양 그래프가 좁아져서 각 샘플의 영향범위가 줄어든다. 감소시키면 넓은 종모양 그래프가 되어 샘플이 넓은 범위에 걸쳐 영향을 주므로 결정 경계가 더 부드러워진다. 즉 overfitting인 경우에는 감마를 감소시키고 underfitting인 경우에는 증가시켜야 한다.
모델의 복잡도를 조절하려면 gamma와 C를 함께 조정하는 것이 좋다.
- sigmoid
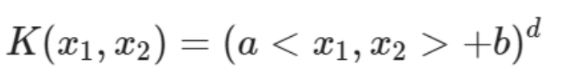

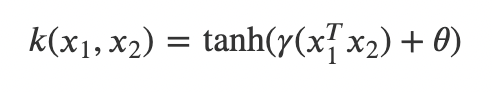
📌 SVM 회귀
목적
분류와 반대로, 일정한 Margin에 안에 가능한 많은 샘플이 들어가도록 하는 것. Margin 안에서 훈련 샘플이 추가되어도 모델의 예측에는 영향이 없다.
결정함수의 결괏값이 0보다 클 경우 1(양성클래스), 아니면 0(음성클래스)가 된다.
- (code) Hyperparameter ε, : Margin을 조절할 수 있다. ε가 클수록 Margin커짐!
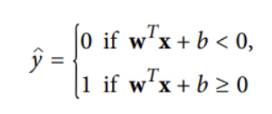
목적함수
결정함수의 기울기는 가중치 벡터(w)의 노름(norm, ||w||)와 같다.
= 기울기를 2로 나누는 것은 Margin에 2를 곱하는 것과 같다.
= 가중치 벡터가 작을수록 Margin이 커진다.
*Margin을 크게 하기 위해 ||w||을 최소화 하자.
||w||는 0에서 미분할 수 없으므로 목적함수의 (1/2)||w||^2를 최소화하자.
- Quadratic Programming을 공부해두면 앞으로 쓰일 곳이 많다!
참고
[https://excelsior-cjh.tistory.com/165]
