
아키텍처에 기반하여 올바른 데이터베이스를 고르기 위한 질문들
- 읽기를 많이 하는지 쓰기를 많이 하는지 혹은 균형 잡힌 상태인지
- 확장성을 고려하여 처리량은 얼마나 필요한지
- 얼마만큼의 데이터를 얼마나 오래 보관할지, 평균 객체 크기는 얼마이며 작은지 또는 큰지 아니면 평균에 가까운지 파악
- 데이터 액세스하는 방법과 보안이 갖춰졌는지 파악
- 데이터 내구성, 즉 얼마나 오래 보존할지
- 데이터 쿼리에서 기본 키를 사용하는지 또한 조인할지 여부
- 정형인지 반정형인지, 검색할 필요가 있는지
- RDBMS와 NoSQL 중 뭘 원하는지
- 라이선스 비용이 있는지, 클라우드 네이티브 데이터베이스로 전활할 수 있는지
Database Types
- RDBMS (= SQL / OLTP):
RDS,Aurora- great for joins- NoSQL database:
DynamoDB(~JSON),ElastiCache(key / value pairs),Neptune(graphs) - no joins, no SQL- Object Store:
S3(for big objects) /Glacier(for backups / archives)- Data Warehouse (= SQL Analytics / BI):
Redshift(OLAP),Athena- Search:
ElasticSearch(JSON) - free text, unstructured searches- Graphs:
Neptune- displays relationships between data
RDS
- Managed PostgreSQL / MySQL / Oracle / SQL Server
- Must provision an EC2 instance & EBS Volume type and size
- Support for Read Replicas and Multi AZ
- Security through IAM, Security Groups, KMS, SSL in transit
- Backup / Snapshot / Point in time restore feature
- Managed and Scheduled maintenance
- Monitoring through CloudWatch
- Use case: Store relational datasets (RDBMS / OLTP), perform SQL queries, transactional inserts / update / delete is available
RDS for Solutions Architect
- Operations: small downtime when failover happens, when maintenance happens, scalinng in read replicas / ec2 instance / restore EBS implies manual intervention, application changes.
- Security: AWS responsible for OS security, we are responsible for settign up KMS, security groups, IAM policies, authorizing users in DB, using SSL
- Reliability: Multi AZ feature, failover in case of failures
- Performance: depends on EC2 instance type, EBS volume type, ability to add Read Replicas. Storage auto-scaling & manual scaling of instances
- Cost: Pay per hour based on provisioned EC2 and EBS
Aurora
- Compitable API for PostgreSQL / MySQL
- Data is held in 6 replicas, across 3 AZ
- Auto healing capability
- Multi AZ, Auto Scaling Read Replicas
- Read Replicas can be Global
- Aurora database can be Global for DR or latency purposes
- Auto scaling of storage from 10GB to 128TB
- Define EC2 instance type for aurora instances
- Same security / monitoring / maintenance features as RDS
- Aurora Serverless - for unpredictable / intermittent workloads
- Aurora Multi-Master - for continous writes failover
- Use case: same as RDS, but with less maintenance / more flexibility / more performance
Aurora for Solutions Architect
- Operations: less operations, auto scaling storege
- Security: AWS responsible for OS security, we are responsible for setting up KMS, security groups, IAM policies, authorizing users in DB, using SSL
- Reliability: Multi AZ, highly available, possibly more than RDS, Aurora Serverless option, Aurora Multi-Master option
- Performance: 5x performance (according to AWS) due to architectural optimizations. Up to 15 Read Replicas (only 5 for RDS)
- Cost: Pay per hour based on EC2 and storage usage. Possibly lower costs compared to Enterprise grade databases such as Oracle
ElastiCache
- Managed Redis / Memcached (similar offering as RDS, but for caches)
- In-memory data store, sub-millisecond latency
- Must provision an EC2 instance type
- Support for Clustering (Redis) and Multi AZ, Read Replicas (sharding)
- Security through IAM, Security Groups, KMS, Redis Auth
- Backup / Snapshot / Point in time restore feature
- Managed and Scheduled maintenance
- Monitoring through CloudWatch
ElastiCache for Solutions Architect
- Operations: same as RDS
- Security: AWS responsible for OS security, we are responsible for setting up KMS, security groups, IAM policies, users (Redis Auth), using SSL
- Reliability: Clustirng, Multi AZ
- Performance: Sub-millisecond performance, in memory, read replicas for sharding, very popular cache option
- Cost: Pay per hour based on EC2 and storage usage
DynamoDB
- AWS proprietary technology, managed NoSQL database
- Serverless, provisioned capacity, auto scaling, on demand capacity
- Can replace ElastiCache as key/value store (storing session data for example)
- Highly Available, Multi AZ by default, Read and Writes are decoupled, DAX for read cache
- Reads can be eventually consistent or strongly consistent
- Security: authentication and authorization is done through IAM
- DynamoDB Streams to integrate with AWS Lambda
- Backup / Restore feature, Global Table feature
- Monitoring through CloudWatch
- Can only query on primary key, sort key, or indexes
- Use Case: Serverless applications development (small documents 100s KB), distributed serverless cache, doesn't have SQL query language available, has transactions capability from Nov 2018
DynamoDB for Solutions Architect
- Operations: no operations needed, auto scaling capability, serverless
- Security: full security through IAM policies, KMS encryption, SSL in flight
- Reliability: Multi AZ, Backups
- Performance: single digit millisecond performance, DAX for caching reads, performance doesn't degrade if your application scales
- Cost: Pay per provisioned capacity and storage usage (no need to guess in advance any capacity - can use auto scaling)
S3
- S3 is a key/value storer for objects
- Great for big objects, not so great for small objects
- Serverless, scales infinitely, max object size is 5TB
- Strong consistency
- Tiers: S3 Standard, S3 IA, S3 One Zone IA, Glacier for backups
- Features: Versioning, Encryption, Cross Region Replication, etc...
- Security: IAM, Bucket Policies, ACL
- Encryption: SSE-S3, SSE-KMS, SSE-C, client side encryption, SSL in transit
- Use Case: static files, key value store for big files, website hosting
S3 for Solutions Architect
- Operations: no operations needed
- Security: IAM, Bucket Policies, ACL, Encryption (Server/Client), SSL
- Reliability: 99.999999999% durability / 99.99% availability, Multi AZ, CRR
- Performance: scale to thousands of read / writes per second, transfer acceleration / multi-part for big files
- Cost: pay per storage usage, network cost, requests number
Athena
- Fully Serverless database with SQL capabilities
- Used to query data in S3
- Pay per query
- Output results back to S3
- Secured through IAM
- Use Case: one time SQL queries, serverless queries on S3, log analytics
Athena for Solutions Architect
- Operations: no operations needed, serverless
- Security: IAM + S3 security
- Reliability: managed service, uses Presto engine, highly available
- Performance: queries scale based on data size
- Cost: pay per query / per TB of data scanned, serverless
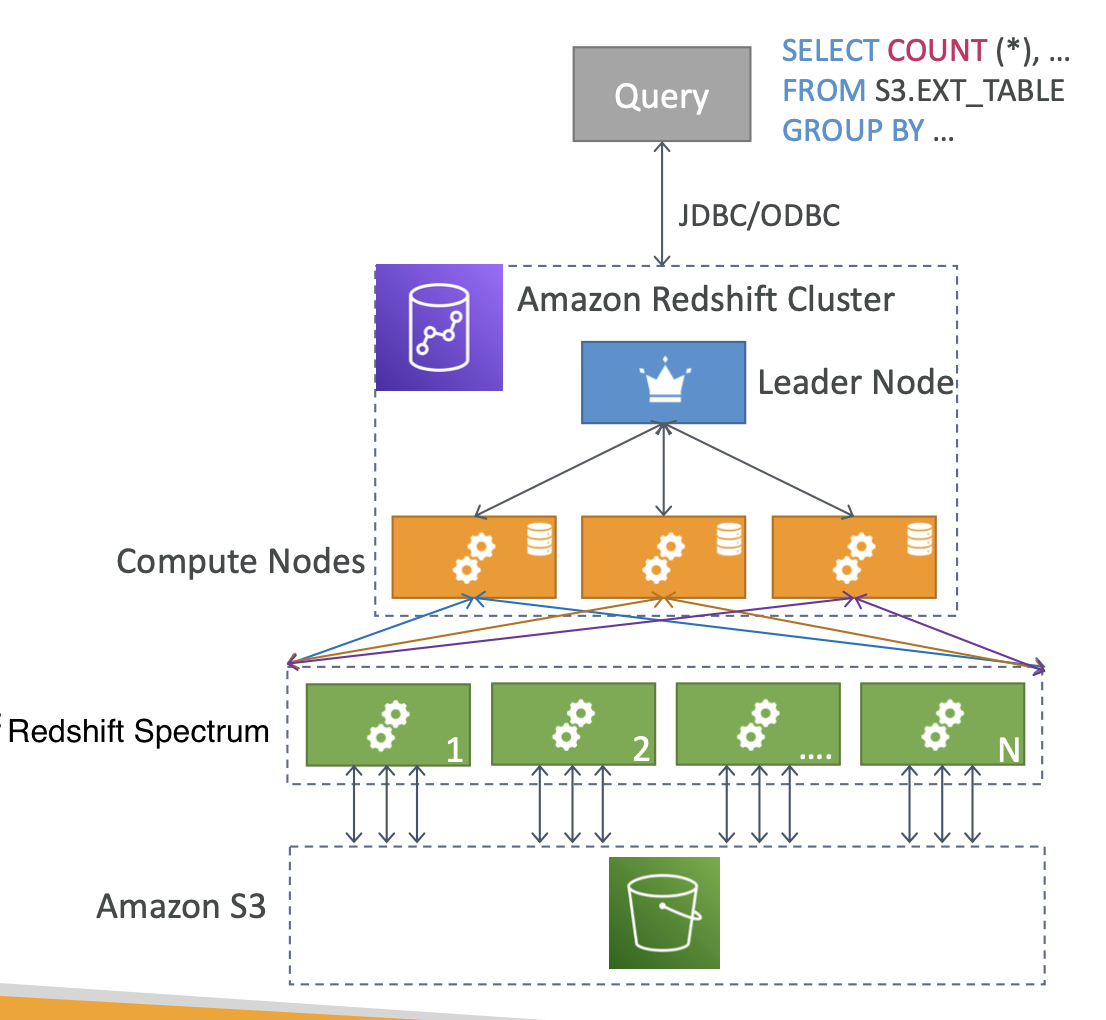
Redshift
- Redshift is based on PostgreSQL, but it's not used for OLTP
- It's OLAP - online anlytical processing (analytics and data warehousing)
- 10x better performance than other data warehouses, scale to PBs of data
- Columnar storage of data (instead of row based)
- Massively Parallel Query Execution (MPP)
- Pay as you go based on the instances provisioned
- Has a SQL interface for performing the queries
- BI tools such as AWS Quicksight or Tableau integrate with it
- Data is loaded form S3, DynamoDB, DMS, other DBs...
- From I node to 128 nodes, up to 128 TB of space per node
- Leader node: for query planning, results aggregation
- Compute node: for performing the queries, send results to leader
- Redshfit Spectrum: perform queries directly against S3 (no need to load)
- Backup & Restore, Security VPC / IAM / KMS, Monitoring
- Redshift
Enhanced VPC Routing:COPY / UNLOADgoes through VPCRedshift - Snapshots & DR
- Redshift has no "Multi-AZ" mode
- Snapshots are point-in-time backups of a cluster, stored internally in S3
- Snapshots are incremental (only what has changed is saved)
- You can restore a snapshot into a new cluster
- Automated: every 8 hours, every 5 GB, or on a schedule. Set retention
- Manual: snapshot is retained until you delete it
- You can configure Amazon Redshift to automatically copy snapshots (automated or manual) of a cluster to another AWS Region
Loading data into Redshift
- Amazon Kinesis Data Firehose
- S3 using COPY command
- EC2 Instance
Redshift Spectrum
- Query data that is already in S3 without loading it.
- Must have a Redshift cluster available to start the query
- The query is then submitted to thousands of Redshift Spectrum nodes
Redshift for Solutions Architect
- Operations: like RDS
- Security: IAM, VPC, KMS, SSL (like RDS)
- Reliability: auto healing features, cross-region snapshots copy
- Performance: 10x performance vs other data warehousing, compression
- Cost: pay per node provisioned, 1/10th of the cost vs other warehouses
- vs Athena: faster queries / joins / aggregations thanks to indexed
- Remember: Redshift = Analytics / BI / Data Warehouse
AWS Glue
- Managed extract, transform, and load (ETL) service
- Useful to prepare and transform data for analytics
- Fully serverless service
Neptune
- Fully managed graph database
- When do we use Graphs ?
- High relationship data
- Social Networking: Users friends with Users, replied to comment on post of user and likes other comments
- Knowledge graphs (Wikipedia)
- Highly available across 3 AZ, with up to 15 read replicas
- Point-in-time recovery, continuous backup to Amazon S3
- Support for KMS encryption at rest + HTTPS
Neptune for Solutions Architecture
- Operations: similar to RDS
- Security: IAM, VPC, KMS, SSL (similar to RDS) + IAM Authentication
- Reliability: Multi-AZ, clustering
- Performance: best suited for graphs, clustering to improve performance
- Cost: pay per node provisioned (similar to RDS)
- Remember: Neptune = Graphs
Amazon OpenSearch Service
- Amazon OpenSearch is successor to Amazon ElasticSearch
- Example: In DynamoDB, you can only find by primary key or indexes
- With OpenSearch, you can search any field, even partially matches
- It's common to use OpenSearch as a complement to another database
- OpenSearch also has some usage for Big Data applications
- You can provision a cluster of instances
- Built-in integrations: Amazon Kinesis Data Firehose, AWS IoT, and Amazon CloudWatch Logs for data ingestion
- Security through Cognito & IAM, KMS encryption, SSL & VPC
- Comes with OpenSearch Dashboards (visualization)
OpenSearch for Solutions Architect
- Operations: similar to RDS
- Security: Cognito, IAM, VPC, KMS, SSL
- Reliability: Multi-AZ, clustering
- Performance: based on ElasticSearch project (open source), petabyte scale
- Cost: pay per node privisioned (similar to RDS)
- Remember: OpenSearch = Search / Indexing
- 다음 중 SQL 언어 호환성 및 삽입, 업데이트, 삭제와 같은 변환 프로세싱 기능을 통해 관계형 데이터셋의 저장을 보조해주는 데이터베이스는 무엇인가요 ?
- A. Amazon Redshift
B. Amazon RDS- C. Amazon DynamoDB
- D. Amazon ElasticCache
✅ Amazon Redshift는 온라인 트랜잭션 프로세싱(OLTP)에 사용될 수 없습니다. Redshift는 데이터 웨어하우징과 같은 온라인 분석 프로세싱(OLAP)을 위한 것입니다.
- 다음 중 Redis API와 호환이 가능한 캐싱 기능을 제공하는 AWS 서비스는 무엇인가요 ?
- A. Amazon RDS
- B. Amazon DynamoDB
- C. Amazon ElasticSearch
D. Amazon ElastiCache
✅ Amazon RDS에는 캐싱 기능이 없으며, JDBC 기반으로 Redis API와 호환되지 않으며 Amazon DynamoDB는 Redis 대용으로 사용할 수 있지만 Redis API를 지원하지 않습니다. Amazon ElastiCache는 완전 관리형 인메모리 데이터 스토어로, Redis 혹은 Memcached와 호환이 가능합니다.
- 온프레미스 MongoDB NoSQL 데이터베이스를 AWS로 이전하려 합니다. 데이터베이스 서버를 관리하고 싶지 않기 때문에 고가용성 및 높은 내구성과 신뢰성을 제공하며, 가급적이면 서버리스인 관리형 NoSQL 데이터베이스를 사용하려 합니다. 이런 경우, 어떤 데이터베이스를 선택해야 할까요 ?
- A. Amazon RDS
B. Amazon DynamoDB- C. Amazon Redshift
- D. Amazon Aurora
✅ Amazon DynamoDB는 키-값 문서, NoSQL 데이터베이스입니다.
- 여러분은 온라인 트랜잭션 프로세싱(OLTP)을 수행하려 합니다. 이 작업에는 오토 스케일링 기능이 내장되어 있고, 기반 스토리지에 대해 최대 복제본 수를 제공하는 데이터베이스를 사용하고자 합니다. 이 경우, 다음 중 어떤 AWS 서비스를 추천할 수 있을까요 ?
- A. Amazon ElastiCache
- B. Amazon Redshift
C. Amazon Aurora- D. Amazon RDS
✅ Amazon Aurora는 MySQL 및 PostgreSQL과 호환이 가능한 관계형 데이터베이스입니다. Aurora는 데이터베이스 인스턴스 당 최대 128TB까지 자동 스케일업하는 분산형, 내결함성 자가 복구 스토리지 시스템이라는 것이 특징입니다. 최대 15개의 지연 시간이 낮은 읽기 전용 복제본, 지정 시간 복구, Amazon S3로의 지속적인 백업 그리고 3개의 AZ에 대한 복제를 통해 높은 성능과 고가용성을 제공합니다.
- 한 스타트업 회사가 솔루션 아키텍트인 여러분에게 사용자들이 서로 친구가 될 수 있고, 서로의 포스트에 좋아요를 남길 수 있는 소셜 미디어 웹사이트 아키텍처의 구축을 도와달라고 한 상황입니다. 이 회사는 'Mike의 친구들이 남긴 포스트에는 몇 개의 좋아요가 있는가?'와 같은 복잡한 쿼리를 수행하려 합니다. 이 경우, 어떤 데이터베이스의 사용을 추천할 수 있을까요 ?
- A. Amazon RDS
- B. Amazon Redshift
C. Amazon Neptune- D. Amazon ElasticSearch
✅ Amazon Neptune은 빠르고 신뢰도가 높은 완전 관리형 그래프 데이터베이스 서비스로 고도로 연결된 데이터셋을 처리하는 애플리케이션을 구축하고 실행하는 데에 도움을 줍니다.
- 각각의 크기가 100MB인 한 세트의 파일들이 있는데, 이 파일을 안전하고 내구성이 높은 키-값 스토어에 저장하려 합니다. 이 경우, 다음 중 어떤 AWS 서비스를 사용하는 게 권장될까요 ?
- A. Amazon Athena
B. Amazon S3- C. Amazon DynamoDB
- D. Amazon ElastiCache
✅ Amazon S3는 키-값 스토어가 맞습니다. (키는 버킷 내 객체의 전체 경로입니다.)
- 큰 규모의 열 기반 데이터 세트에 대한 분석 쿼리 수행을 위해 효율적인 데이터베이스가 필요합니다. 이 데이터 웨어하우스에 대한 연결에는 Amazon QuickSight와 같은 보고 및 대시보드 도구를 사용하려 합니다. 이 경우, 어떤 AWS 기술을 사용하는 것을 추천할 수 있을까요 ?
- A. Amazon RDS
- B. Amazon S3
C. Amazon Redshift- D. Amazon Neptune
- S3 버킷 내에 많은 로그 파일이 저장되어 있는데. 로그를 필터링하고 인증되지 않은 작업을 시도한 사용자를 판별하기 위해 빠른 분석을, 가능하다면 서버리스로 수행하고자 합니다. 이 경우, 다음 중 어떤 AWS 서비스를 사용해야 할까요 ?
- A. Amazon DynamoDB
- B. Amazon Redshift
- C. Amazon S3 Glacier
D. Amazon Athena
✅ Amazon Athena는 대화식 서버리스 쿼리 서비스로, 표준 SQL을 사용해 S3 버킷 내의 데이터를 분석하는 데에 유용합니다.
- 여러분은 솔루션 아키텍트로서 Redshift 클러스터를 위한 재해 복구 계획을 준비해달라는 요청을 받았습니다. 어떻게 해야 할까요 ?
- A. 다중 AZ 활성화
B. 자동 스냅샷을 활성화한 후, Redshift 클러스터가 다른 AWS 리전으로 스냅샷을 자동으로 복사하게끔 구성- C. 스냅샷을 찍은 후, 새로운 Redshift 글로벌 클로스터로 복원
- 다음 중 클러스터와 데이터 리포지토리 간을 오가는 COPY 및 UNLOAD 트래픽이 VPC를 통해 이동하도록 강제하는 Redshift 기능은 무엇인가요 ?
A. 향상된(Enhanced) VPC 라우팅- B. 개선된(Improved) VPC 라우팅
- C. Redshift 스펙트럼
- DynamoDB 데이터 스토어로 사용하는 게임 웹사이트를 실행 중입니다. 사용자들은 이름 검색, 가능하다면 부분 일치 검색을 통해 다른 게이머들을 찾을 수 있는 기능을 요청해왔습니다. 이런 기능을 구현하려면 다음 중 어떤 AWS 기술이 권장될까요 ?
- A. Amazon DynamoDB
B. Amazon ElasticSearch- C. Amazon Neptune
- D. Amazon Redshift
✅ 검색(search)이라는 말이 나오면, 무조건 ElasticSearch를 떠올리면 됩니다.
- 이 AWS 서비스를 사용하면 몇 번의 클릭 만으로 ETL(추출, 변환, 로드)을 생성, 실행 및 모니터링할 수 있습니다.
A. AWS Glue- B. Amazon DynamoDB
- C. Amazon RDS
- D. Amazon Redshift
✅ AWS Glue는 추출, 변환 및 로드(ETL) 연산을 위한 서버리스 데이터 준비 서비스입니다.
