
JOIN
두 개 이상의 테이블에서 데이터를 검색하고 결합하는 데 사용된다.
특히, JOIN 을 사용하면 테이블의 데이터를 효율적으로 중복을 방지하고 데이터 일관성을 유지할 수 있다.
JOIN절은SELECT문에서FROM다음에 위치하며,
JOIN할 테이블 이름과 두 테이블을 연결하는 조건(ON) 을 지정한다.SELECT * FROM table1 JOIN table2 ON table1.key = table2.key;
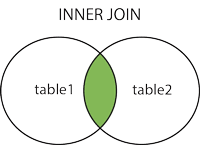
JOIN에는 여러 가지 유형이 있는데, 그 중에서도 가장 일반적인 유형은INNER JOIN이다.
INNER JOIN은 두 개의 테이블에서 일치하는 데이터만 보여준다.또한
LEFT JOIN,RIGHT JOIN등 다양한JOIN유형이 있다.
각각의JOIN유형은 데이터베이스 관리 시스템에 따라 다를 수 있으므로, 사용하는 데이터베이스에 따라 문법을 확인해야 한다.
INNER JOIN
두 테이블의 공통된 정보(key) 를 기준으로 테이블을 연결해서 한 테이블처럼 보는 것을 의미한다.
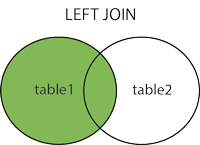
LEFT JOIN
key 값을 사용하여 두 테이블을 연결한다.
왼쪽 테이블을 기준으로 하여 모른 왼쪽 테이블의 레코드를 보여주며, 오른쪽 테이블에 일치하는 레코드가 없는 경우에는 NULL 값으로 표시된다.
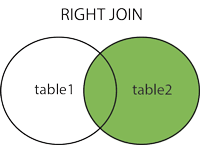
RIGHT JOIN
LEFT JOIN 과 반대.
또한 이 외에도 다양한 JOIN 유형이 있으나, 각각의 JOIN 유형은 데이터베이스 관리 시스템에 따라 다를 수 있으므로, 사용하는 데이터베이스에 따라 문법을 확인해야 한다.
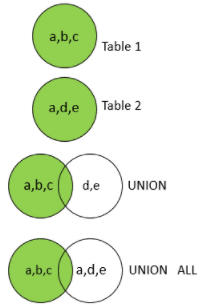
UNION
위의 JOIN 이 두 개 이상의 테이블을 결합하는 데 사용됐다면,
UNION 은 두 개 이상의 SELECT 문 결과를 하나의 결과 집합으로 합치기 위해 사용된다.
이때 SELECT 문의 열 수, 열의 자료형, 열의 이름 등이 모두 일치해야 하며, 중복된 행은 하나의 행으로만 표시된다.
또한, UNION ALL 은 중복된 행도 모두 포함시킨다.
따라서 UNION ALL 은 UNION 에 비해 속도가 빠르지만, 결과 집합의 크기가 더 커지므로 주의해서 사용해야 한다.
UNION과UNION ALL의 기본 문법SELECT column1, column2, ... FROM table1 UNION [ALL] SELECT column1, column2, ... FROM table2 [WHERE condition];여기서 [ALL]은 생략할 수 있으며, WHERE 절도 선택적으로 사용할 수 있다. 결과 집합의 열 수와 데이터 유형이 일치하지 않으면 오류가 발생한다.
ORDER BY절은 마지막SELECT문에만 적용되기 때문에 여러SELECT문에 적용되는ORDER BY절은 무시된다.예를 들어, 아래와 같이 두 개의
SELECT문을UNION으로 합치고,ORDER BY절을 적용하고자 한다면,
아래의 쿼리에서는ORDER BY절이 마지막SELECT문인 두 번째SELECT문에만 적용되기 때문에, 결과 집합에서 age 열로 정렬된 결과를 얻을 수 없다.SELECT name, age FROM table1 UNION SELECT name, age FROM table2 ORDER BY age DESC;따라서 아래와 같이
UNION으로 합쳐진 결과 집합을 서브쿼리로 만들고,
그 서브쿼리에ORDER BY절을 적용해야 한다
이를 위해서는 서브쿼리에 별칭을 부여하고, 그 별칭을 가지고ORDER BY절을 적용해야 한다.SELECT * FROM ( SELECT name, age FROM table1 UNION SELECT name, age FROM table2 ) AS t ORDER BY t.age DESC;
따라서, JOIN 과 UNION 은 데이터를 결합하는 데 사용되지만 사용하는 시나리오가 다르다.
JOIN 은 서로 다른 테이블에서 관련 데이터를 가져와서 키값을 통해 하나의 결과로 통합할 때 사용하고,
UNION 은 두 개 이상의 SELECT 문을 결합하여 하나로 통합한다.
