아래와 같은 main 함수 코드가 있습니다. 여기서 문제가 될 만한 지점을 발견할 수 있나요?

main 함수 안의 첫 두 줄에서는 포인터 x와 y를 선언합니다.
그리고 x에는 malloc 함수를 이용해서 int 자료형 크기에 해당하는 메모리를 할당합니다.
그 다음에는 x와 y 포인터가 가리키는 지점에 각각 42와 13을 저장합니다.
여기서 문제가 될 만한 부분은 *y = 13 입니다. y는 포인터로만 선언되었을 뿐이지, 어디를 가리킬지에 대해서는 아직 정의가 되지 않았습니다.
따라서 초기화 되지 않은 *y는 프로그램 어딘가를 임의로 가리키고 있을 수도 있습니다.
따라서 그 곳에 13이라는 값을 저장하는 것이 오류를 발생시킬 수도 있는 것이죠.
아래 코드와 같이 y = x; 라는 코드를 더해주면, y는 x가 가리키는 곳과 동일한 곳을 가리키게 됩니다.
따라서 *y = 13; 으로 저장하면 x가 가리키는 곳에도 동일하게 13으로 저장될 것입니다.

트리는 연결리스트를 기반으로 한 새로운 데이터 구조입니다.
연결리스트에서의 각 노드 (연결 리스트 내의 한 요소를 지칭)들의 연결이 1차원적으로 구성되어 있다면, 트리에서의 노드들의 연결은 2차원적으로 구성되어 있다고 볼 수 있습니다.
각 노드는 일정한 층에 속하고, 다음 층의 노드들을 가리키는 포인터를 가지게 됩니다.
아래 그림은 트리의 한 예입니다. 나무가 거꾸로 뒤집혀 있는 형태를 생각하면 됩니다.
가장 높은 층에서 트리가 시작되는 노드를 ‘루트’라고 합니다. 루트 노드는 다음 층의 노드들을 가리키고 있고, 이를 ‘자식 노드’라고 합니다.
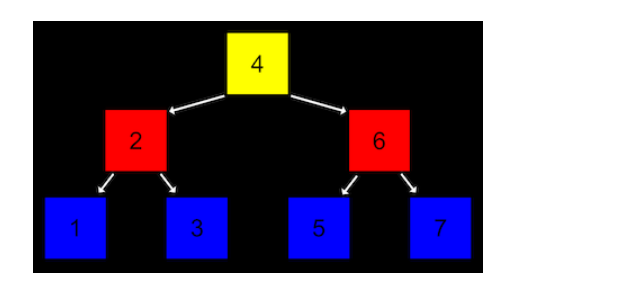
위 그림에 묘사된 트리는 구체적으로 ‘이진 검색 트리’ 입니다.
각 노드가 구성되어 있는 구조를 살펴보면 일정한 규칙을 알 수 있습니다.
먼저 하나의 노드는 두 개의 자식 노드를 가집니다.
또 왼쪽 자식 노드는 자신의 값 보다 작고, 오른쪽 자식 노드는 자신의 값보다 큽니다.
따라서 이런 트리 구조는 이진 검색을 수행하는데 유리합니다.
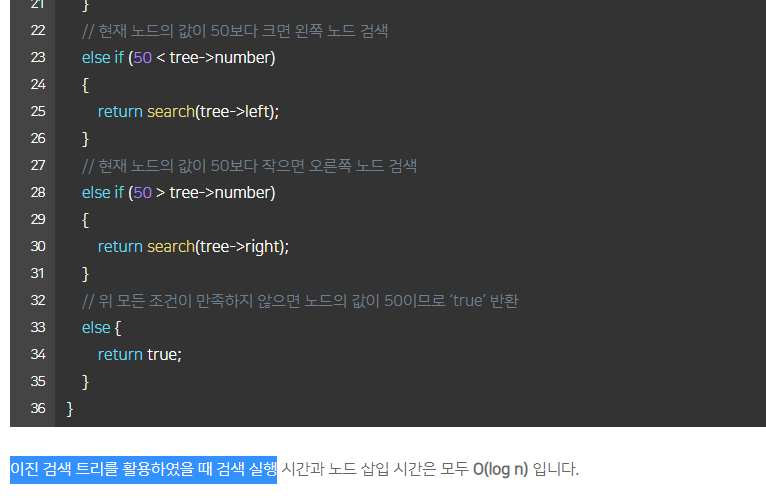
아래 코드에서는 이진 검색 트리의 노드 구조체와 “50”을 재귀적으로 검색하는 이진 검색 함수를 구현하였습니다.

해시 테이블은 ‘연결 리스트의 배열’입니다. 여러 값들을 몇 개의 바구니에 나눠 담는 상황을 생각해 봅시다.
각 값들은 ‘해시 함수’라는 맞춤형 함수를 통해서 어떤 바구니에 담기는 지가 결정 됩니다.
각 바구니에 담기는 값들은 그 바구니에서 새롭게 정의되는 연결 리스트로 이어집니다.
이와 같이 연결 리스트가 담긴 바구니가 여러개 있는 것이 ‘연결 리스트의 배열’, 즉 ‘해시 테이블’이 됩니다.
쉬운 예로 아래 그림과 같이 사람의 이름이 해시 테이블에 저장되며, 해시 함수는 ‘이름의 가장 첫 글자’인 경우를 생각해 보겠습니다.
그 경우 알파벳 개수에 해당하는 총 26개의 포인터들이 있을 수 있으며, 각 포인터는 그 알파벳을 시작으로 하는 이름들을 저장하는 연결 리스트를 가리키게 됩니다.
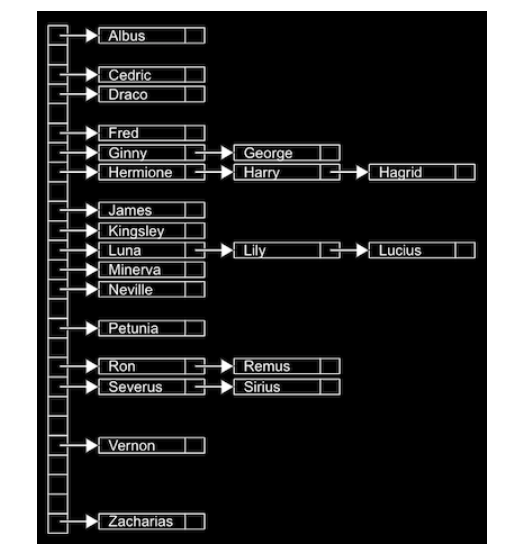
만약 해시 함수가 이상적이라면, 각 바구니에는 단 하나의 값들만 담기게 될 것입니다.
따라서 검색 시간은 O(1)이 됩니다.
하지만 그렇지 않은 경우, 최악의 상황에는 단 하나의 바구니에 모든 값들이 담겨서 O(n)이 될 수도 있습니다.
일반적으로는 최대한 많은 바구니를 만드는 해시 함수를 사용하기 때문에 거의 O(1)에 가깝다고 볼 수 있습니다.
‘트라이’는 기본적으로 ‘트리’ 형태의 자료 구조입니다.
특이한 점은 각 노드가 ‘배열’로 이루어져있다는 것입니다.
예를 들어 영어 알파벳으로 이루어진 문자열 값을 저장한다고 한다면 이 노드는 a부터 z까지의 값을 가지는 배열이 됩니다.
그리고 배열의 각 요소, 즉 알파벳은 다음 층의 노드(a-z 배열)를 가리킵니다.
아래 그림과 같이 Hermione, Harry, Hagrid 세 문자열을 트라이에 저장해보겠습니다.
루트 노드를 시작으로 각 화살표가 가리키는 알파벳을 따라가면서 노드를 이어주면 됩니다.
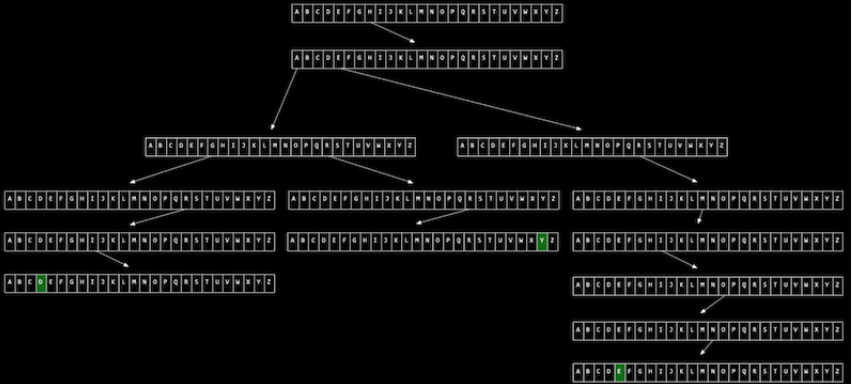
위와 같은 트라이에서 값을 검색하는데 걸리는 시간은 ‘문자열의 길이’에 의해 한정됩니다.
단순히 문자열의 각 문자를 보며 트리를 탐색해나가기만 하면 되니까요.
일반적인 영어 이름의 길이를 n이라고 했을 때, 검색 시간은 O(n)이 되지만, 대부분의 이름은 그리 크지 않은 상수값(예, 20자 이내)이기 때문에 O(1)이나 마찬가지라고 볼 수 있습니다.
큐
큐는 메모리 구조에서 살펴봤듯이 값이 아래로 쌓이는 구조입니다.
값을 넣고 뺄 때 ‘선입 선출’ 또는 ‘FIFO’라는 방식을 따르게 됩니다. 가장 먼저 들어온 값이 가장 먼저 나가는 것이죠.
은행에서 줄을 설 때 가장 먼저 줄을 선 사람이 가장 먼저 업무를 처리하게 되는 것과 동일합니다.
배열이나 연결 리스트를 통해 구현 가능합니다.
스택
반면 스택은 역시 메모리 구조에서 살펴봤듯이 값이 위로 쌓이는 구조입니다.
따라서 값을 넣고 뺄 때 ‘후입 선출’ 또는 ‘LIFO’라는 방식을 따르게 됩니다. 가장 나중에 들어온 값이 가장 먼저 나가는 것이죠.
뷔페에서 접시를 쌓아 뒀을 때 사람들이 가장 위에 있는(즉, 가장 나중에 쌓인) 접시를 가장 먼저 들고 가는 것과 동일합니다.
역시 배열이나 연결 리스트를 통해 구현 가능합니다.
딕셔너리
딕셔너리는 ‘키’와 ‘값’이라는 요소로 이루어져 있습니다.
‘키’에 해당하는 ‘값’을 저장하고 읽어오는 것이죠. 마치 대학교에서 ‘학번’에 따라서 ‘학생’이 결정되는 것과 동일합니다.
일반적인 의미에서 ‘해시 테이블’과 동일한 개념이라고도 볼 수 있습니다.
역시 ‘키’를 어떻게 정의할 것인지가 중요합니다.
