앞으로 다루는 모델은 특정한 범위에 한정된 작업을 수행하기 위해 만들어진 모델이 아니라,
입출력 쌍을 활용한 다양한 유사 작업에 대해 스스로를 최적화하기 위해 자동으로 적응하는 모델.
즉 특정 작업에 대한 데이토러 학습한 일반화된 모델이다.
이 포스팅은 일반 함수의 적합fitting 을 자동화하는 방법에 대해 다룬다.
학습은 파라미터 추정에 불과하다
학습 개요
1. 입력 및 입력에 대응하는 출력인 실측 자료ground truth 와 가중치 초기값 주어짐.
2. 모델에 입력 데이터가 들어가고 (순방향 전달)
3. 실측값과 출력 결과값을 비교해 오차 계산.
4. 모델의 가중치parameter 최적화하기 위해 가중치를 오차값에 따라 일정 단위(가중치별 오류의 기울기gradient)만큼 변경
변경값은 합성 함수(역방향 전달)의 미분값을 연속으로 계산하는 규칙(chain rule) 통해 정해진다
5. 학습 때 사용하지 않았던 데이터에 대한 출력값과 실측값과의 오류가 일정 수준 이하로 떨어질때가지 반복.
손실 함수 lost function
: 학습 과정이 최소화하고자 하는 단일 값을 계산하는 함수.
- 일반적으로 훈련 샘플로부터 기대하는 출력값과 모델이 샘플에 대해 실제 출력한 값 사이의 차이 계산.
- 이 때 parameter 조정은 손실값이 적은 샘플의 출력을 변경하기 보다 가중치가 큰 샘플을 우선적으로 보정.
- 제곱을 사용한 차이가 절댓값을 사용한 차이보다 잘못된 결과에 더 많은 불이익을 준다
def loss_fn(t_p, t_c): sq_diffs = (t_p-t_c)**2 return sq_diffs.mean()
경사 하강 gradient descent
각 파라미터와 관련해 손실의 변화율을 계산해 손실이 줄어드는 방향으로 파라미터 값 바꿔나간다.
w*x +b
- 손실의 변화 비율에 비례해서 w를 바꾸는 편이 좋다. 특히 손실함수가 여러 파라미터를 가질수록 더 그렇다.
- 얼마만큼 바꿀지에 대한 스케일링 비율을 나타내는 이름은 ML에선 learning rate 라는 변수명 사용,
- gradient : 두 개 이상의 파라미터를 가진 모델에선 각 파라미터에 대한 손실함수의 편미분을 구하고 이 값을 미분 벡터에 넣는다.
- 미분 계산 -> 모델에 미분 적용 -> 경사 함수 정의
def grad_fn(t_u,t_c,t_p, w, b): dloss_dtp = dloss_fn(t_p,t_c) dloss_dw = dloss_dtp * dmodel_dw(t_u,w,b) dloss_db = dloss_dtp * dmodel_db(t_u,w,b) return torch.stack([dloss_dw.sum(),dloss_db.sum()])
모델적합을 위한 반복
훈련루프
- epoch : 훈련 샘플을 가지고 반복적으로 파라미터를 조정하는 훈련의 한 단위.
- 훈련루프 예시
def training_loop(n_epochs, learning_rate, params, t_u, t_c): for epoch in range(1,n_epochs+1): w,b= params t_p = model(t_u,w,b) # 순방향 전달 loss = loss_fn(t_p, t_c) grad = grad_fn(t_u,t_c,t_p,w,b) # 역방향 전달 params = params - learning_rate *grad print('epoch %d, Loss %f' % (epoch,float(loss))) return params
오버피팅이나 언더피팅이 발생하지 않도록 params 조정 해야한다
-> Hyperparameter tuning
: 훈련을 통해 모델의 파라미터가 훈련되는 반면 하이퍼파라미터는 학습 자체를 제어하는 역할을 한다.
입력 정규화
- 입력값을 변경해서 기울기가 서로 큰 차이가 나지 않게 만든다.
- 입력값의 범위가 -1.0에서 1.0사이를 벗어나지 않도록 바꾼다.
(위 예제엔 t_u 에 0.1을 곱하면 이와 유사하게 된다.)- 문제가 커지고 복잡해질 경우 정규화는 모델 수렴을 개선하는 데 사용할 수 있는 쉽고 효과적인 방법이다.
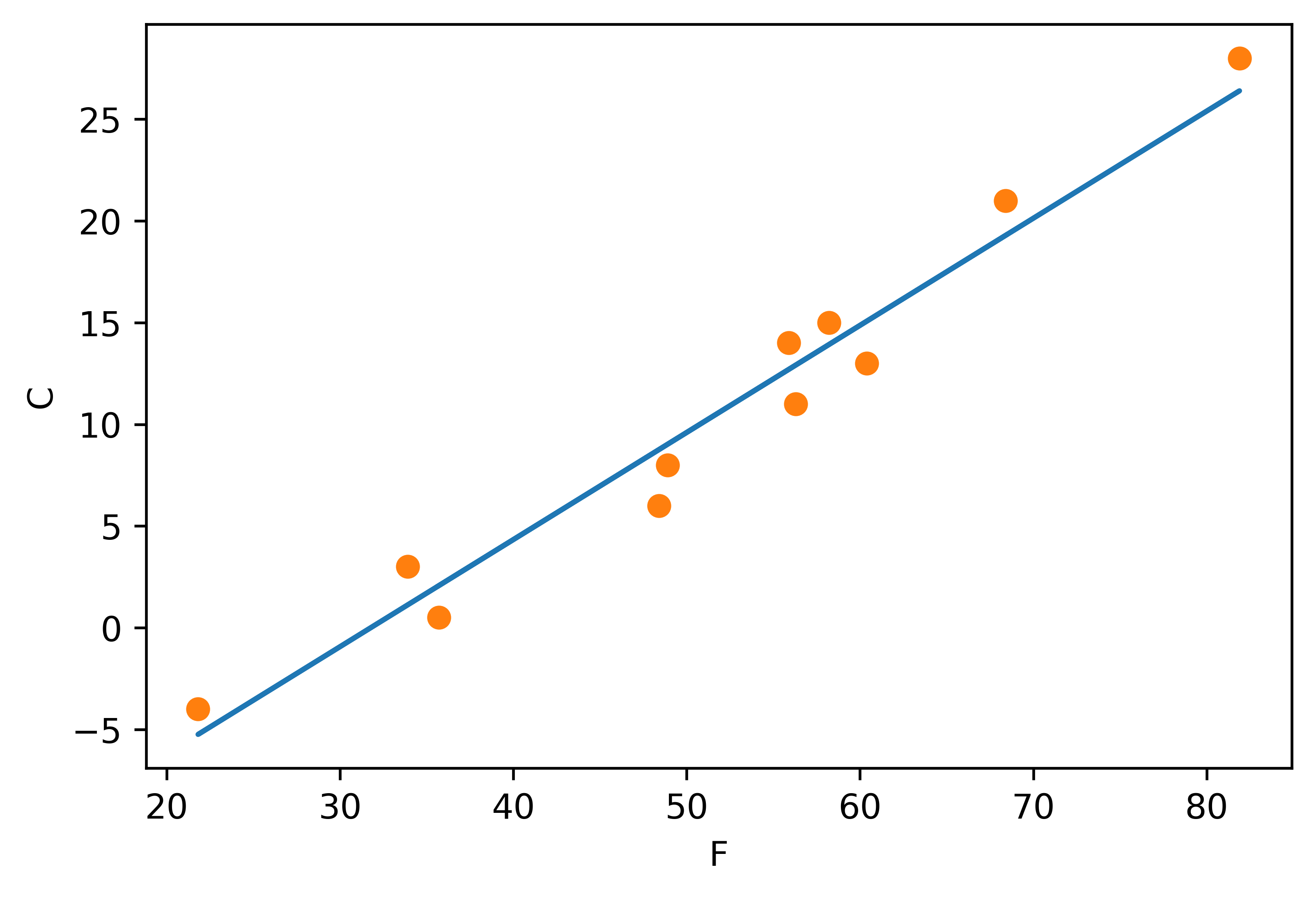
시각화
- argument unpacking 활용
from matplotlib import pyplot as plt t_p = model(t_un, *params) # 모르는 값을 정규화하여 훈련, 인자도 언패킹하고 있다. # *params 는 parmas 요소를 개별 인자로 전달 fig = plt.figure(dpi = 600) plt.xlabel("F") plt.ylabel("C") plt.plot(t_u.numpy(), t_p.detach().numpy()) plt.plot(t_u.numpy(), t_c.numpy(), 'o')
자동미분, 역전파
기울기 자동 계산
- autograd
파이토치 텐서는 자신이 어디로부터 왔는지, 즉 어느 텐서에서 어떤 연산을 수행해서 만들어진 텐서인지 기억
-> 미분을 최초 입력까지 연쇄적으로 적용해 올라갈 수 있다.
-> 순방향 식이 주어지면 아무리 복잡하더라도 입력 파라미터와 관련해 표현식에 대한 기울기를 자동으로 제공.params = torch.tensor([1.0,0.0], requires_grad = True) print(params.grad is None) loss = loss_fn(model(t_u, *params),t_c) loss.backward() params.grad #True #tensor([4517.2969, 82.6000]) - 각 요소에 대한 손실값의 미분을 포함
- requires_grad = True
: 연산의 결과로 만들어지는 모든 텐서를 이은 전체 트리를 기록하라고 요청- 일반적으로 모든 파이토치 텐서는 grad 속성 가지는데, 주로 값은 None
- 값을 얻기 위해 requires_grad=True 지정, 모델을 호출해 손실값을 구한 다음 loss 텐서에 대해 backward를 호출.
- 미분함수 누적하기
- 파이토치는 연쇄적으로 연결된 함수들을 거쳐 손실에 대한 미분 계산하고, 값을 텐서(그래프의 말단노드)의 grad속성에 누적
store 가 아니고 accmulate- backward 호출은 미분을 말단 노드에 누적하는데,
앞서 backward가 호출되었다면 손실이 다시 계산되고 backward가 다시 호출되고 각 말단 노드의 기울기 값이
이전 반복문 수행 시 계산 되었던 기존값에 누적되어
부정확한 기울기값 초래.
이를 방지하기 위해 각 반복문에서 명시적으로 기울기를 0으로 초기화def training_loop(n_epochs, learning_rate, params, t_u, t_c): for epoch in range(1,n_epochs+1): if params.grad is not None: params.grad.zero_() t_p = model(t_u,*params) loss = loss_fn(t_p, t_c) loss.backward() with torch.no_grad(): params-= learning_rate *params.grad if epoch% 500 ==0: print('epoch %d, Loss %f' % (epoch,float(loss))) return params
최적화_optimizer
- 모델에 대해 매번 모든 파라미터를 직접 조정해야 하는 작업을 대신 해준다.
- torch.optim
- 모든 optimizer 생성자는 첫 번째 입력으로 파라미터 리스트(대개 requires_grad =True 로 설정된 텐서)를 받는다.
- zero_grad 와 step 메소드 제공
- zero_grad() : optimizer 생성자에 전달된 파라미터의 모든 grad 속성값을 0으로 만든다.
- step() : 최적화 전략에 따라 파라미터 값 조정.
import torch.optim as optim params = torch.tensor([1.0,0.0], requires_grad = True) learning_rate = 1e-5 optimizer = optim.SGD([params], lr=learning_rate)
- SGD(stocastic gradient descent) : 확률적 경사 하강,
미니배치minibatch라고 불리는 여러 샘플 중 임의로 뽑은 일부에 대해 평균을 계산해서 얻기 때문에 확률적stochastic
단 옵티마이저는 손실값이 모든 샘플에서 얻은 것(순정)인지 일부를 임의로 선택해 얻은 것(확률적)인지 모르기에 알고리즘적으로 두 경우가 동일.def training_loop(n_epochs, optimizer, params, t_u, t_c): for epoch in range(1,n_epochs+1): t_p = model(t_u, *params) loss = loss_fn(t_p, t_c) optimizer.zero_grad() loss.backward() optimizer.step() if epoch % 500 == 0: print('Epoch %d, Loss %f'% (epoch,float(loss))) return params
- step 호출을 통해 직접 계산하지 않아도 params가 알아서 조정.
- backward 호출 전에 zero_grad() 이용해 기울기 값을 0으로 초기화 해야한다.
params = torch.tensor([1.0,0.0],requires_grad=True) learning_rate =1e-2 optimizer= optim.SGD([params], lr=learning_rate) training_loop( 5000, optimizer, params, t_un, t_c )-Adam은 학습률이 동적으로 변하는 좀 더 섬세한 optimizer, 비율 조정에도 영향을 덜 받는다.
훈련, 검증, 과적합
- 과적합Overfitting
- 적응성이 높은 모델은 많은 파라미터를 사용하여 주어진 데이터 포인트에 대해 손실을 최소화하도록 학습되지만,
이 상태가 데이터 포인트 사이나 데이터 포인트에서 벗어난 경우에 대해서도 잘 동작할 수 있는지 보장할 수 없다.
손실을 구하거나 음의 기울기를 따라 내려갈 때 사용했던 데이터와는 별개의 데이터를 사용하면 기대보다 높은 손실값을 얻을 수 있다.- 개선 방법
- 먼저 처리 과정에서 충분한 데이터가 주어졌는지 확인.
- 모델이 각 훈련 데이터에 대해 적합한 수준으로 맞춰질 수 있는지 여부.
- 손실 함수에 패널티항penalization term을 두어 모델의 적합fitting이 더 부드럽고 천천히 만들어지도록 함.
- 입력 샘플에 노이즈를 더한다.
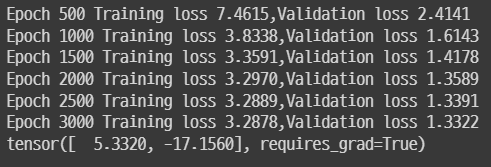
n_samples = t_u.shape[0] n_val = int(0.2*n_samples) shuffled_indices = torch.randperm(n_samples) train_indices = shuffled_indices[:-n_val] val_indices = shuffled_indices[-n_val:]def training_loop(n_epochs, optimizer, params, train_t_u, train_t_c,val_t_u,val_t_c): for epoch in range(1,n_epochs+1): train_t_p = model(train_t_u, *params) train_loss = loss_fn(train_t_p, train_t_c) val_t_p = model(val_t_u, *params) val_loss = loss_fn(val_t_p, val_t_c) optimizer.zero_grad() train_loss.backward() optimizer.step() if epoch % 500 == 0: #print('Epoch %d, Loss %f'% (epoch,float(loss))) print(f"Epoch {epoch} Training loss {train_loss.item():.4f}," f"Validation loss {val_loss.item():.4f}") return params params = torch.tensor([1.0,0.0],requires_grad=True) learning_rate =1e-2 optimizer= optim.SGD([params], lr=learning_rate) training_loop( 3000, optimizer, params, train_t_un, train_t_c,val_t_un,val_t_c)
- 통상적으로 훈련셋에 대해 더 잘 동작.
훈련의 목표는 훈련 손실과 검증 손실이 둘 다 줄어드는 형태가 되어 검증 손실이 훈련 손실에 매우 가깝게 다가가면서 두 값이 거의 같아지는 것.