
통계 분석 기법을 이용한 가설 검정
가설 검정
기술 통계_descriptive statistics
: 데이터를 요약해 설명하는 통계 분석 기법추론 통계_inferential statistics
: 숫자를 요약하는 것을 넘어 어떤 값이 발생할 확률을 계산 하는 통계 분석 기법
우연히 나타날 확률이 작다면 통계적으로 유의하다_statistically significant
우연히 나타날 확률이 크다면 통계적으로 유의하지 않다_not statistically significant- 일반적으로 통계 분석을 수행했다는 것은 추론 통계를 이용해 가설 검정을 했다는 의미.
유의확률_significance probability,p-value
: 실제로는 집단 간 차이가 없는데 우연히 차이가 있는 데이터가 추출될 확률통계적 가설 검정_statistical hypothesis test
: 유의확률을 이용해 가설을 검정하는 방법
t 검정 - 두 집단의 평균 비교하기
- t 검정_t-test은 두 집단의 평균에 통계적으로 유의한 차이가 있는지 알아볼때 사용하는 통계 분석 기법
ex1)import pandas as pd mpg = pd.read_csv('mpg.csv') mpg.query('category in ["compact","suv"]') .groupby('category',as_index=False) .agg(n= ('category','count'),mean = ('cty','mean')) ################################################### category n mean 0 compact 47 20.12766 1 suv 62 13.50000
- 각 데이터 추출 후 scipy 패키지의 ttest_ind() 를 이용하면 t 검정 가능.
- t 검정은 비교하는 집단의 분산이 같은지 여부에 따라 적용 공식 달라짐. 같다고 가정하고 equal_var=True 입력
compact = mpg.query('category == "compact"')['cty'] suv = mpg.query('category == "suv"')['cty'] from scipy import stats stats.ttest_ind(compact,suv,equal_var =True) ########################################### Ttest_indResult(statistic=11.917282584324107 , pvalue=2.3909550904711282e-21)
- pvalue = 유의확률, p-value 가 0.05 미만이면 '집단 간 차이가 통계적으로 유의하다'
ex2)
mpg.query('fl in ["r","p"]') .groupby('fl',as_index=False) .agg(n=('fl','count'),mean=('cty','mean')) ########################################## fl n mean 0 p 52 17.365385 1 r 168 16.738095regular = mpg.query('fl=="r"')['cty'] premium= mpg.query('fl=="p"')['cty'] stats.ttest_ind(regular,premium,equal_var = True) ######################## Ttest_indResult(statistic=-1.066182514588919 ,pvalue=0.28752051088667036)
- p-value 가 0.05보다 큰 0.2875...
=>실제로는 차이가 없는데 우연에 의해 차이가 관찰될 확률이 28.75%. 즉 통계적으로 유의하지 않다.
상관분석_correlation analysis
: 두 연속 변수가 서로 관련이 있는지 검정하는 기법
- 도출한 상관계수_correlation coefficient 를 보면 관련성의 정도 파악 가능.
- 0~1 사이의 값을 지니며 1에 가까울수록 관련성이 크다.
양수면 정비례, 음수면 반비례.economics = pd.read_csv('economics.csv') economics[['unemploy','pce']].corr() ########################### unemploy pce unemploy 1.000000 0.614518 pce 0.614518 1.000000
- 상관계수가 +0.61 이므로, 정비례 관계
stats.pearsonr(economics['unemploy'],economics['pce']) ############### (0.6145176141932082, 6.773527303291316e-61)
- stats.pearsonr() 출력 첫 번째 값이 상관계수, 두 번째 값이 유의확률.
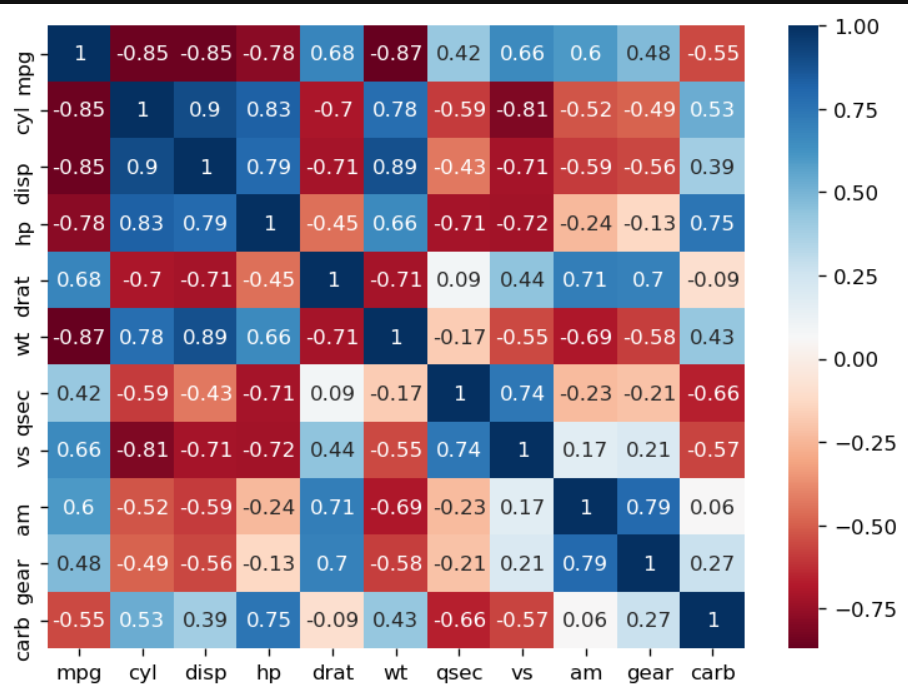
#상관행렬 만들기 car_cor = mtcars.corr() car_cor = round(car_cor,2) ###################### mpg cyl disp hp drat wt qsec vs am gear carb mpg 1.00 -0.85 -0.85 -0.78 0.68 -0.87 0.42 0.66 0.60 0.48 -0.55 cyl -0.85 1.00 0.90 0.83 -0.70 0.78 -0.59 -0.81 -0.52 -0.49 0.53 disp-0.85 0.90 1.00 0.79 -0.71 0.89 -0.43 -0.71 -0.59 -0.56 0.39 hp -0.78 0.83 0.79 1.00 -0.45 0.66 -0.71 -0.72 -0.24 -0.13 0.75 drat 0.68 -0.70 -0.71 -0.45 1.00 -0.71 0.09 0.44 0.71 0.70 -0.09 wt -0.87 0.78 0.89 0.66 -0.71 1.00 -0.17 -0.55 -0.69 -0.58 0.43 qsec 0.42 -0.59 -0.43 -0.71 0.09 -0.17 1.00 0.74 -0.23 -0.21 -0.66 vs 0.66 -0.81 -0.71 -0.72 0.44 -0.55 0.74 1.00 0.17 0.21 -0.57 am 0.60 -0.52 -0.59 -0.24 0.71 -0.69 -0.23 0.17 1.00 0.79 0.06 gear 0.48 -0.49 -0.56 -0.13 0.70 -0.58 -0.21 0.21 0.79 1.00 0.27 carb -0.55 0.53 0.39 0.75 -0.09 0.43 -0.66 -0.57 0.06 0.27 1.00히트맵 만들기
plt.rcParams.update({'figure.dpi' : '120', #해상도 설정 'figure.figsize' : [7.5,5.5]}) # 가로세로크기 # sns.heatmap(car_cor, annot=True, # 상관계수 표시 cmap='RdBu') # 컬러맵

막상 하면 모르니까 일단 하자.