LLM (본 논문에서는 PLMs)은 large scale of parameters 가진다
➡ Data-Scarce & Resource-Limited 상황에서 Inefficient
- Catastrophic forgetting issues
- Limited storage infrastructure
PEFT 등장
Only fine-tunes the minority of the original parameters
- Effectively decrease parameters
- BUT also lead concerns
- Breaks the model structure
- Inference delays

Two types of Methods
- Structured Methods
- Extra introduced blocks : LoRA, Prompt-Tuning
- Internal original blocks : BitFit
- Non-structured Methods

HiFi
- Fine-tuning the relatively significant heads in MHA(multi-head attention module)
- = Highly informative and Strongly correlated attention heads
- 이유 : LLM 대부분 Transformer 기반 & MHA plays a crucial role
- Two Big Challenges
- How to measure the individual importance of a head?
- How to measure the relative importance between heads?

Information Richness

- W_h ➡️ O_h 근사
- O_h(x) SVD
- Singular values {σt} decays slower == informative & contains more meaningful principal components
- Information richness of an attention head as Ih(Wh|x)
- Monte-Carlo
- Stable results can be obtained using a small n (e.g., 300)
Correlation

- Weights 간 Correlation ➡️ Outputs 간 Correlation 으로 근사
- O`h = average O over the sequence axis
- Correlation between two heads (h, h′) is computed by the covariance
- strong positive and negative should be considered equally ➡️ 절댓값
- Unbiased estimation of covariance (불편추정량)
- Monte-Carlo

Joint Optimization
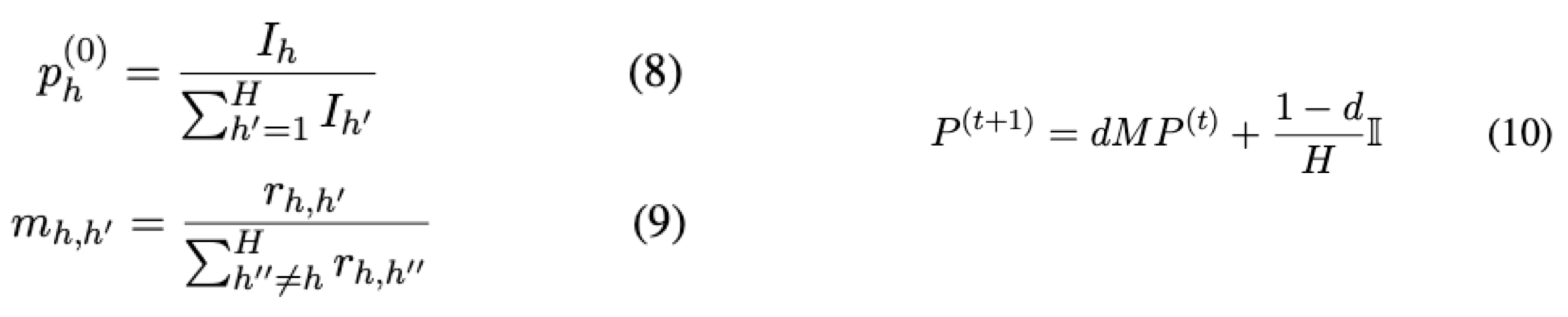
- Heads into directed fully-connected graph
- p_h^(0) = Initial probability per node
- m_h,h` = Probability of moving from node h to another node h′
- P (0) = [p(0), p(0), · · · , p(0)]⊤ : Probability vector
- State transition probability matrix M = [mh,h′]H×H
- PageRank
- d = damping factor

- d = damping factor

Ablation
- Q1: Does the correlation (rh,h′ ) between heads really matter?
- Q2: Are the higher information richness (Ih) of heads more important for the model?
- Q3: Is it enough to only take the correlation (rh,h′ ) into consideration, while ignoring the information richness (Ih)?
- Q4: Does PageRank algorithm really work?


막상 하면 모르니까 일단 하자.