스파르타 코딩 강의로 배운 상권과 유동인구 데이터 분석입니다.
다른 데이터를 살펴보고 다양한 전처리 방법에 대해 알아보겠습니다.
<이용할 데이터>
- 상권 데이터 - 상가의 종류, 위치, 분류 코드 등의 데이터
- 유동인구 데이터 - 서울의 시간, 연령대 별 유동인구 수 데이터
| 상권 데이터 분석 |
1. 라이브러리 & 데이터 가져오기
import pandas as pdcommercial = pd.read_csv('./data/commercial.csv') commercial
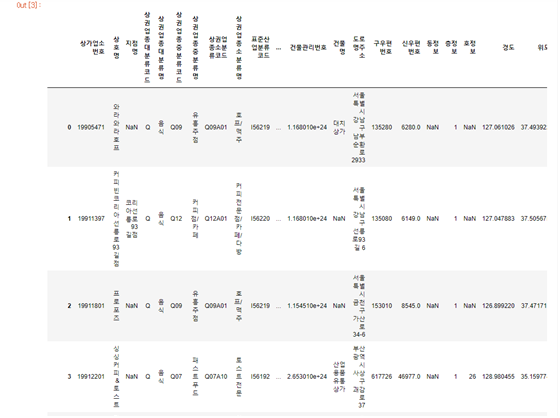
2. 데이터 살펴보기
데이터 확인
commercial.tail(5)

컬럼 살펴보기
list(commercial)

1) 상가업소번호 - 가게가 중복이 되는지 확인하기 위해 필요
commercial.groupby('상가업소번호')['상권업종소분류명'].count().sort_values(ascending=False)
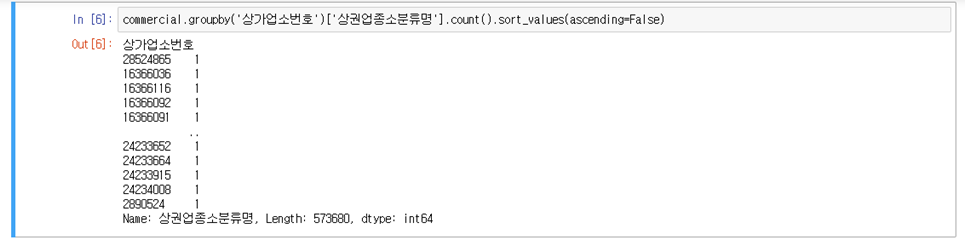
- 데이터의 라인 수 - 573680개의 상가번호 → 중복없음!
2) 상권업종소분류명 - 치킨집을 분류하기 위한 이름
category_range = set(commercial['상권업종소분류명']) print(category_range, len(category_range))

- 메모장에 옮겨서 '치킨' 키워드로 검색 : 간단한 일은 간단한 방법으로!
- "후라이드/양념치킨" 발견
3) 도로명주소 - 치킨집의 위치를 파악하기 위해 필요
- 서울특별시의 구 별 데이터가 필요
- 우리가 가진 데이터는 시군구 데이터 → 데이터 전처리 필요
3. 데이터 전처리
3-1. 도로명 잘라 정리하기
구 별로 데이터를 분석하기 위해 한 덩어리인 도로명 주소를 시, 군, 나머지로 잘라 줍니다.
commercial[['시', '구', '상세주소']] = commercial['도로명주소'].str.split(' ', n=2, expand=True) commercial.tail(5)
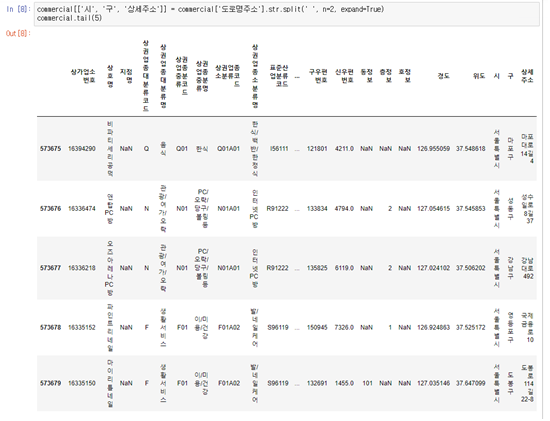
3-2. 서울시 데이터만 남기기
seoul_data = commercial[commercial['시']=='서울특별시'] seoul_data.tail(5)
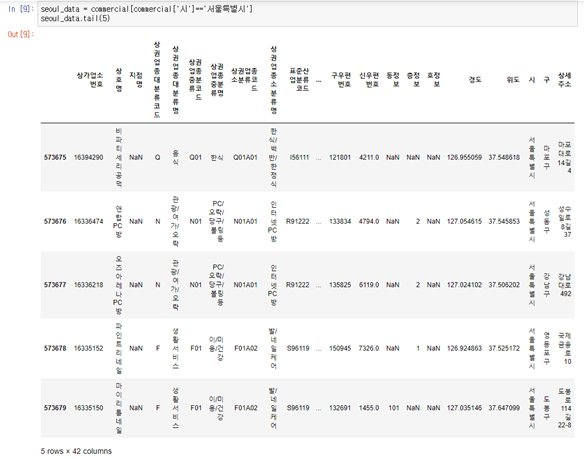
정말 서울시만 남았는지 확인
city_type = set(seoul_data['시']) print(city_type, len(city_type))

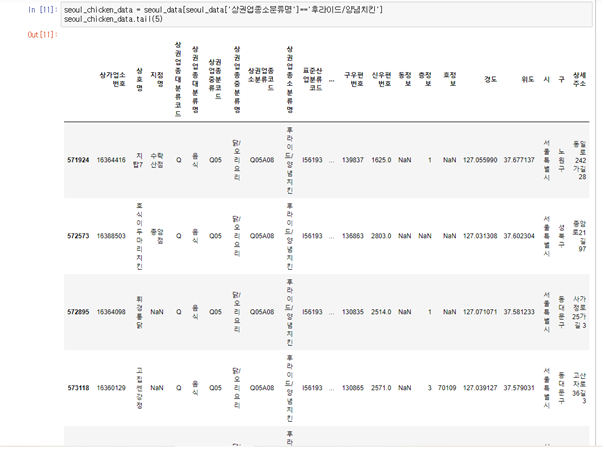
3-3. 치킨집 데이터만 남기기
seoul_chicken_data = seoul_data[seoul_data['상권업종소분류명']=='후라이드/양념치킨'] seoul_chicken_data.tail(5)
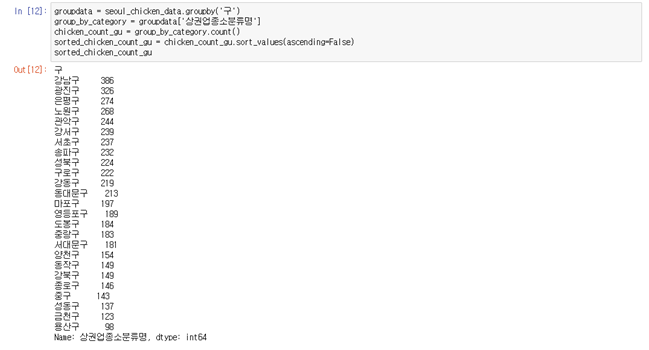
3-4. 구 별로 정리하기
groupdata = seoul_chicken_data.groupby('구') group_by_category = groupdata['상권업종소분류명'] chicken_count_gu = group_by_category.count() sorted_chicken_count_gu = chicken_count_gu.sort_values(ascending=False) sorted_chicken_count_gu
4. 시각화
4-1. bar plot
구 별 치킨 상가 수의 그래프
import matplotlib.pyplot as plt # Apple은 'AppleGothic', Windows는 'Malgun Gothic' plt.rcParams['font.family'] = "Malgun Gothic" plt.figure(figsize= (10,5)) # 그래프의 사이즈 plt.bar(sorted_chicken_count_gu.index, sorted_chicken_count_gu) plt.title('구에 따른 치킨가게 수의 합계') # 그래프의 제목 plt.xticks(rotation=90) plt.show() # 그래프 그리기
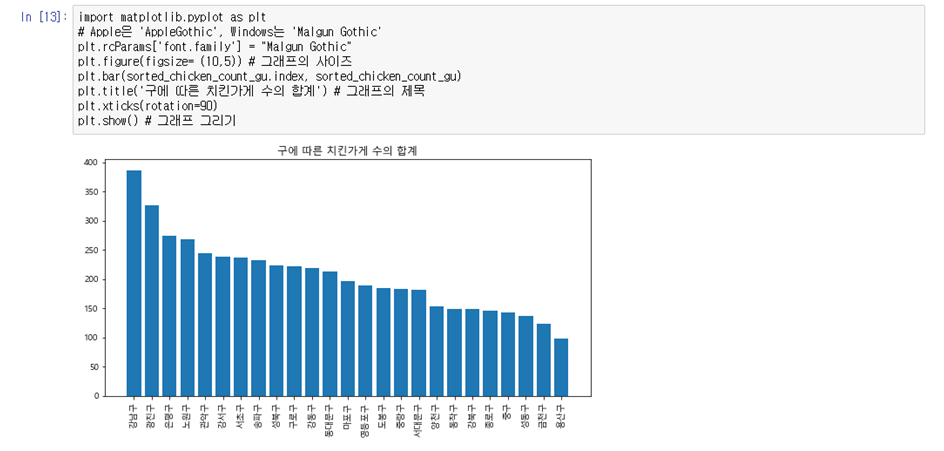
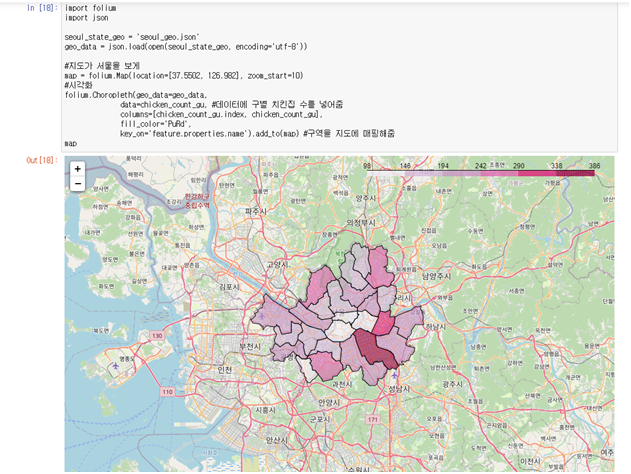
- 강남구, 광진구, 은평구 순으로 가장 많다.
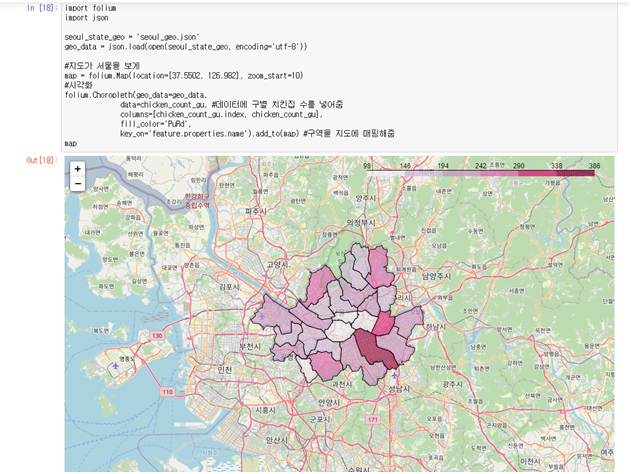
-> 구만 가지고는 인사이트를 얻기 힘들어 실제 지도에 표시
# 라이브러리 가져오기 //conda install -c conda-forge folium #folium 설치 import folium import jsonseoul_state_geo = './data/seoul_geo.json' geo_data = json.load(open(seoul_state_geo, encoding='utf-8'))#지도가 서울을 보게 map = folium.Map(location=[37.5502, 126.982], zoom_start=10) #시각화 folium.Choropleth(geo_data=geo_data, data=chicken_count_gu, #데이터에 구별 치킨집 수를 넣어줌 columns=[chicken_count_gu.index, chicken_count_gu], fill_color='PuRd', key_on='feature.properties.name').add_to(map) #구역을 지도에 매핑해줌 map
| 유동인구 데이터 |
1. 라이브러리 & 데이터 불러오기
import pandas as pdpopulation = pd.read_csv('./data/population07.csv')
2. 데이터 살펴보기
데이터 확인
population.tail(5)
컬럼 살펴보기
list(population) #['일자', '시간(1시간단위)', '연령대(10세단위)', '성별', '시', '군구', '유동인구수']

1) 연령대
set(population['연령대(10세단위)']) #{20, 30, 40, 50, 60, 70}

- 20대부터 70대의 분포
2) 시
set(population['시']) # {'서울'}

3) 군구
set(population['군구'])
- 여러 개의 구가 있음
2. 데이터 전처리
구별 유동인구
sum_of_population_by_gu = population.groupby('군구')['유동인구수'].sum() sum_of_population_by_gu
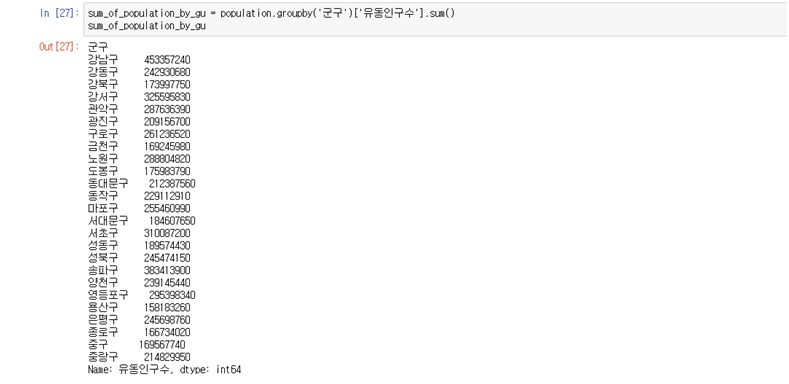
- 항목별로 구별 유동인구수의 총합을 살펴봄
3. 데이터 시각화
3-1. 구별 유동인구 시각화
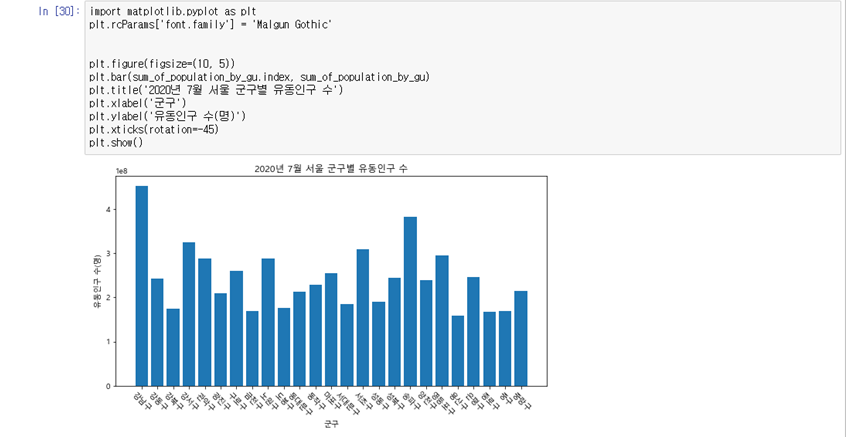
# 폰트 설정 import matplotlib.pyplot as plt plt.rcParams['font.family'] = 'Malgun Gothic'#그래프 그리기 python plt.figure(figsize=(10, 5)) plt.bar(sum_of_population_by_gu.index, sum_of_population_by_gu) plt.title('2020년 7월 서울 군구별 유동인구 수') plt.xlabel('군구') plt.ylabel('유동인구 수(명)') plt.xticks(rotation=-45) plt.show()
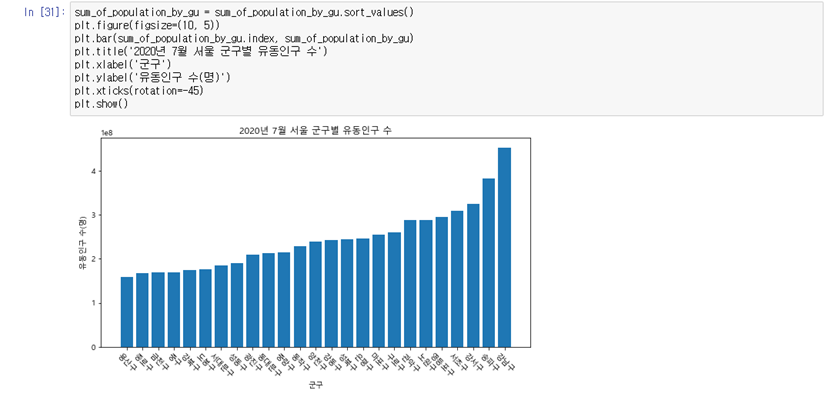
# 정렬된 결과 보이기 sum_of_population_by_gu = sum_of_population_by_gu.sort_values() plt.figure(figsize=(10, 5)) plt.bar(sum_of_population_by_gu.index, sum_of_population_by_gu) plt.title('2020년 7월 서울 군구별 유동인구 수') plt.xlabel('군구') plt.ylabel('유동인구 수(명)') plt.xticks(rotation=-45) plt.show()
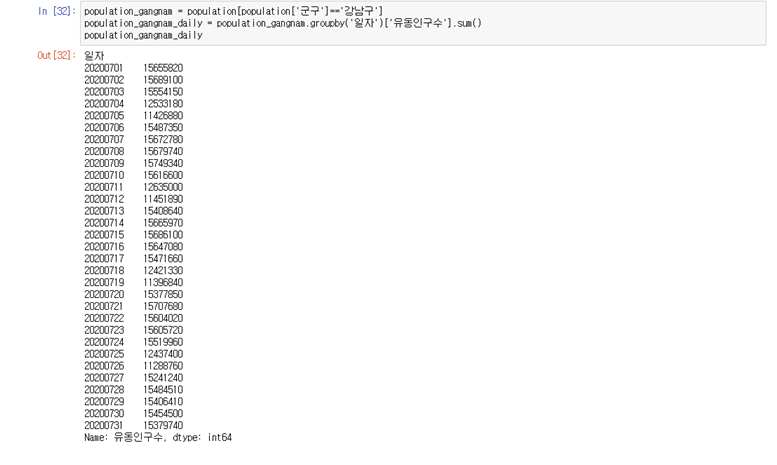
3-2. 강남구의 일별 유동량
population_gangnam = population[population['군구']=='강남구'] population_gangnam_daily = population_gangnam.groupby('일자')['유동인구수'].sum() population_gangnam_daily
# 날짜를 string 타입으로 변경해야 숫자로 인식하지 않아 값이 줄여지지 않습니다. plt.figure(figsize=(12, 5)) date = [] for day in population_gangnam_daily.index: #날짜 인덱싱 date.append(str(day))plt.plot(date, population_gangnam_daily) plt.title('2020년 7월 서울 강남구 날짜별 유동인구 수') plt.xlabel('날짜') plt.ylabel('유동인구 수(천만명)') plt.xticks(rotation=-90) plt.show()
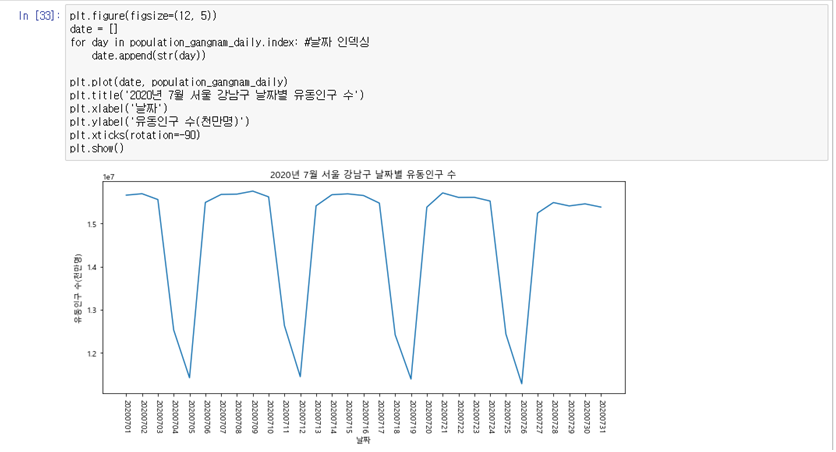
- 주말에 유동인구가 적다
3-3. 지도에 표현하기
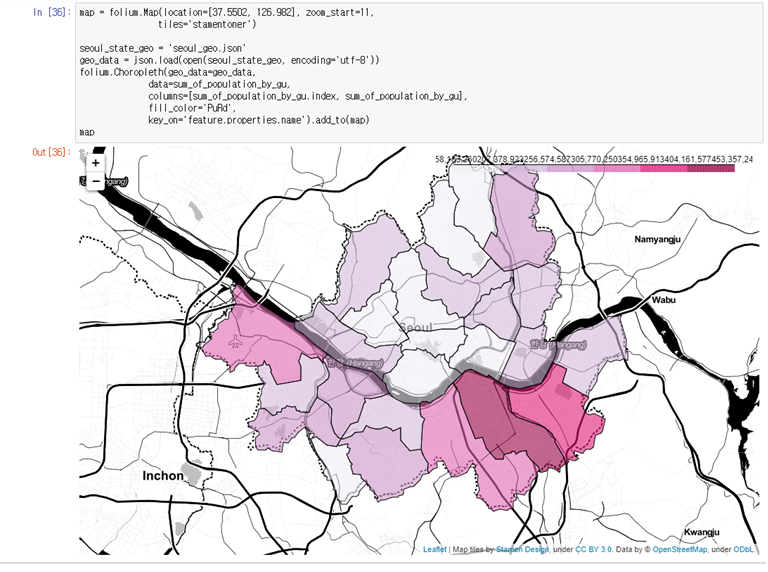
# 지도 만들어주기 map = folium.Map(location=[37.5502, 126.982], zoom_start=11, tiles='stamentoner')seoul_state_geo = './data/seoul_geo.json' geo_data = json.load(open(seoul_state_geo, encoding='utf-8')) folium.Choropleth(geo_data=geo_data, data=sum_of_population_by_gu, columns=[sum_of_population_by_gu.index, sum_of_population_by_gu], fill_color='PuRd', key_on='feature.properties.name').add_to(map) map
folium.Map은 설정값을 넣어주어야 합니다.- 위도경도를 나타내주는,
location- 지도의 초기 확대 정도를 나타내주는
zoom_starttiles='stamentoner'옵션값은 지도의 길과 강 위주로 보여줍니다.
| 상권과 유동인구 같이 분석 |
1. 데이터 합치기
구 이름을 기준으로 합쳐 놓았던 데이터를 다시 행과 열의 데이터로 만들어 준다.
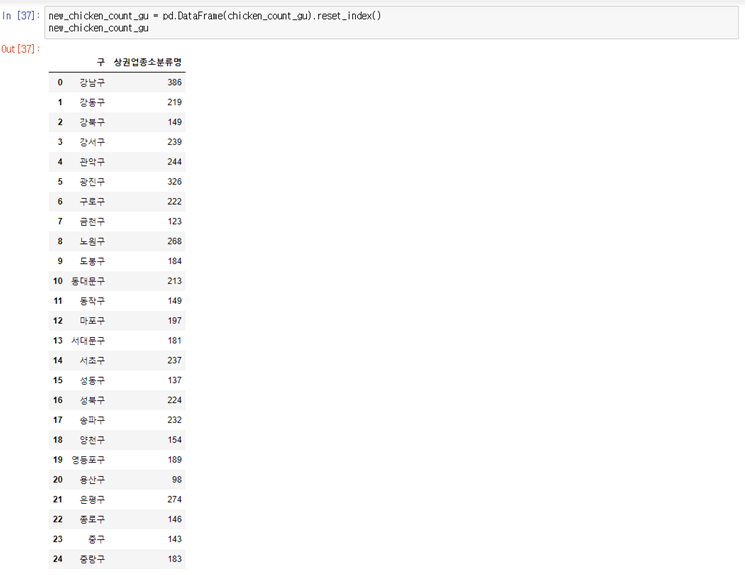
new_chicken_count_gu = pd.DataFrame(chicken_count_gu).reset_index() new_chicken_count_gu
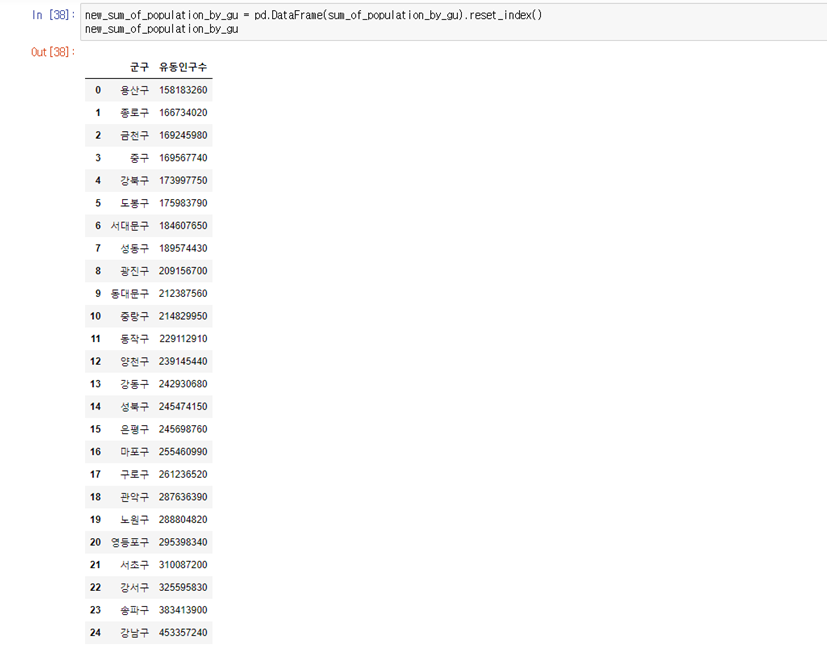
new_sum_of_population_by_gu = pd.DataFrame(sum_of_population_by_gu).reset_index() new_sum_of_population_by_gu
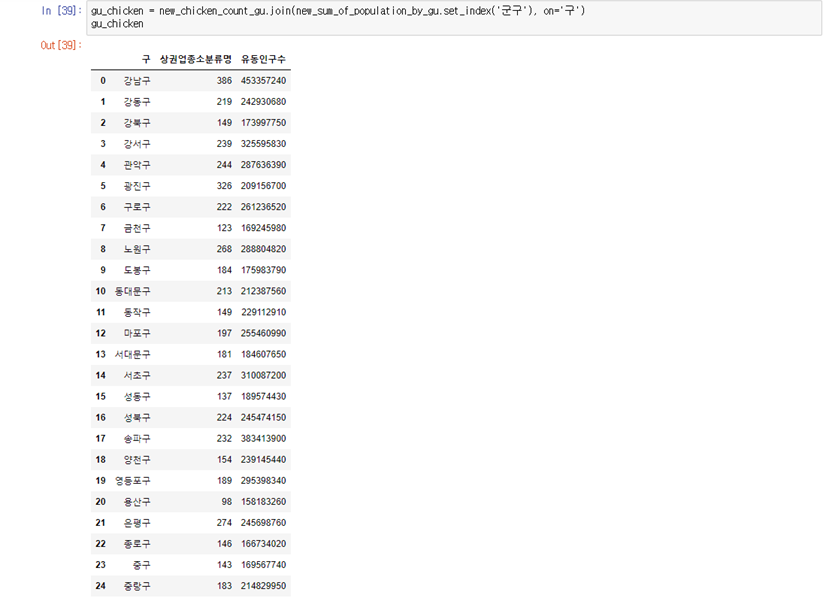
gu_chicken = new_chicken_count_gu.join(new_sum_of_population_by_gu.set_index('군구'), on='구') gu_chicken
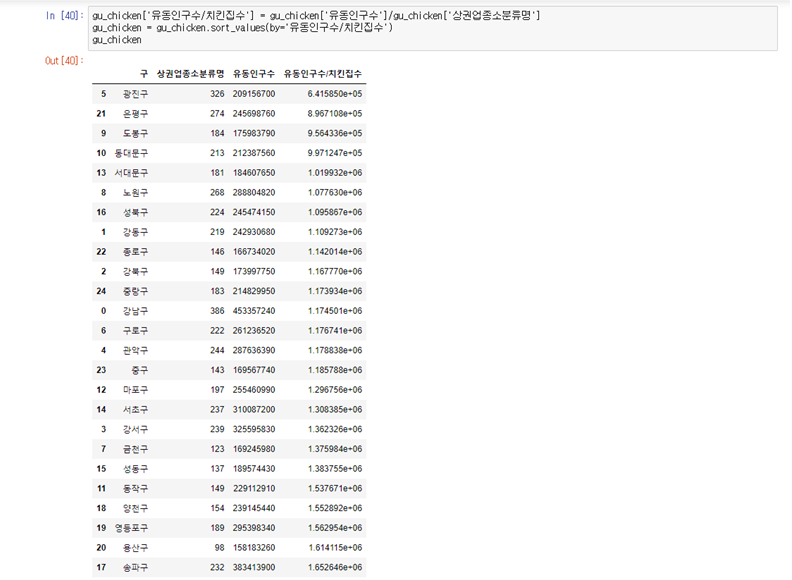
2. 치킨집당 유동인구수
gu_chicken['유동인구수/치킨집수'] = gu_chicken['유동인구수']/gu_chicken['상권업종소분류명'] gu_chicken = gu_chicken.sort_values(by='유동인구수/치킨집수') gu_chicken
#그래프 확인 plt.figure(figsize=(10,5)) plt.bar(gu_chicken['구'], gu_chicken['유동인구수/치킨집수']) plt.title('치킨집 당 유동인구수') plt.xlabel('구') plt.ylabel('유동인구수/치킨집수') plt.xticks(rotation=90) plt.show()
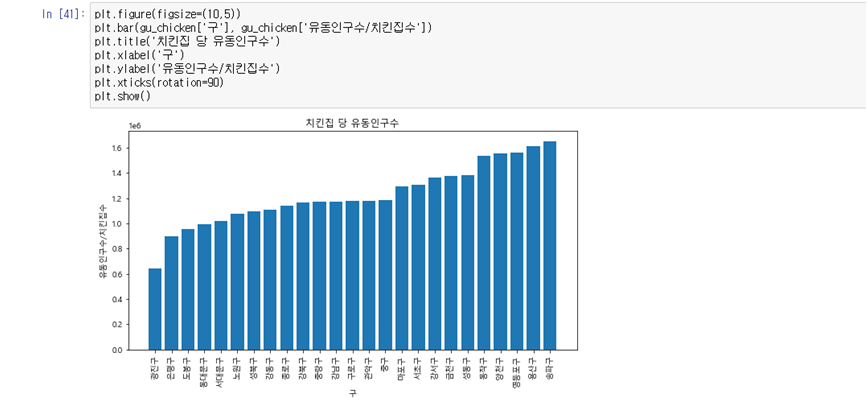
<결과 분석>
- 유동인구가 많은 곳이 장사가 잘된다고 할 수는 없지만 치킨집 당 유동인구수가 많은 곳에 치킨집을 개점해서 노출을 많이시켜야겠다 등의 전략을 세울수는 있습니다. 히트맵을 통하여 유동인구수와 치킨집수의 상관관계도 분석할 수 있을 것 같습니다.
<느낀 점 & 깨달은 것>
- 치킨 키워드를 찾는 것을 함수를 통하여 검색할 수도 있었지만 메모장에서 Ctrl+F를 이용해 검색하는 것이 더 쉬운 방법이었다. 무조건 코드를 이용하기 보다 쉬운 방법이 있으면 효율적으로 함께 사용할 수 있도록 해야겠다고 생각했다.
- 라이브러리
folium을 통한 시각화를 처음 해봤다. 분류예측을 주로 해보기도 하였고 전공공부에서는 나온 적이 없어 처음 들어본 라이브러리였다. 좀더 찾아보니folium을 이용해서 히트맵을 그리면 지도에서 밀도를 시각화할 수 있도록 할 수 있다고 한다. 이것도 추후 공부할 예정이다.

📩 qtly_u@naver.com
안녕하세요 혹시 유동인구 데이터 출처 알 수 있을까요?