GTSRB(교통표지판 분류 문제)에 대한 Classifier model 비교
Computer Vision
- 목적 : 교통 표지판 이미지 데이터를 이용하여 여러 분류 모델을 구현하고 분류기별 성능 비교
- 과정 : 대량의 이미지 데이터를 전처리 - support vector machine, random forest, cnn 세 모델의 성능 차이 확인
캐글 데이터셋 특징 파악
1. 데이터 확인
 - 캐글에서 제공하는 교통표지판 데이터 셋 (GTSRB dataset provided by Kaggle)
- 캐글에서 제공하는 교통표지판 데이터 셋 (GTSRB dataset provided by Kaggle)
German Traffic Sign Benchmark는 2011년 IJCNN(International Joint Conference on Neural Networks)에서 개최된 다중 클래스, 단일 이미지 분류 챌린지이다. 독일 신경 정보학 연구원들이 교통표지판을 예측하기 위해서 만든 데이터이며, 평균적으로 32x32 크기를 가지는 color 이미지로서, 43개 교통표지판과 관련된 약 4만 개의 이미지를 포함한다. 그림 2에서와 같이 제공하는셋은 3개의 이미지 폴더와 3개의 csv 파일로 이루어져 있다. train 데이터를 통해 머신러닝을 학습하고, 학습된 모델을 시험하기 위해 test 데이터를 사용한다. 캐글 교통표지판 csv 데이터 셋을 살펴보면, classID, 즉 label이 있는 지도 학습 (supervised learning)으로 모두 결측치가 없어 정보가 없는 이미지는 존재하지 않음을 알 수 있었다.
- meta 데이터 셋 정보
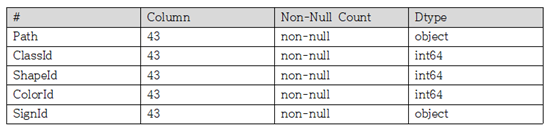
- train 데이터 셋 정보
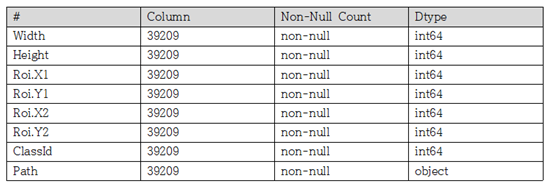
- test 데이터 셋 정보
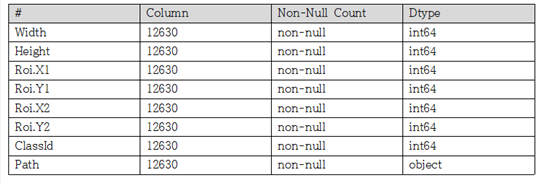
2. 데이터 전처리
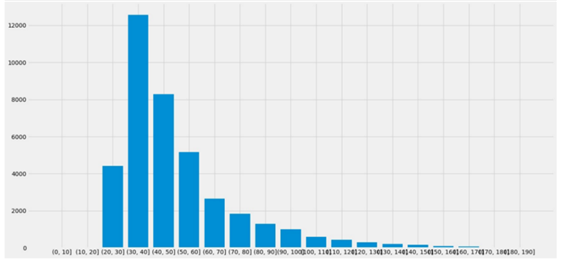
먼저 이미지의 폭과 높이를 확인하기 위해 seaborn 라이브러리 함수 countplot()을 사용하여 확인하였다. 이미지 크기가 모두 다양해 서로 다른 feature의 개수가 있는 것이기에 이를 통일해주는 전 처리가 필요하다. subplot() 함수를 사용하여 히스토그램을 확인하면 그림과 같았다. 30~35의 폭 또는 높이를 갖는 이미지가 제일 많아 대다수를 차지하는 크기인 32x32 크기로 통일하여 배열에 저장해주었다.
또 순차적인 학습을 위해 학습용 이미지를 불러와 Train_images에 array 형태로 저장하고, 같은 방식으로 평가용 이미지를 불러와 Test_images에 array 형태로 저장하였다.
Train_images = []
for i in tqdm(range(len(df_Train))):
img = load_img('./archive/'+df_Train['Path'][i], target_size = (image_height, image_width))
img = img_to_array(img)
Train_images.append(img)
Test_images = []
for i in tqdm(range(len(df_Test))):
img = load_img('./archive/'+df_Test['Path'][i], target_size = (image_height, image_width))
img = img_to_array(img)
Test_images.append(img)데이터에 대한 label은 csv 파일에 ClassId 열로 저장되어 있어 따로 array로 저장해 두었다.
Train_labels = []
Test_labels = []
Train_labels = df_Train['ClassId'].values
Test_labels = df_Test['ClassId'].values
len(Train_labels)3. 데이터 셋 교차검증
분석 대상인 데이터의 타당성을 검증하기 위해 보유한 데이터를 training set과 validation set으로 구분하여 training set 데이터로 학습 모형을 만들고 validation set 데이터로 성능을 계산한 후에 test set으로 학습 모델을 평가하는 방법으로 교차검증 (cross validation)이 있으며, 아래와 같은 방법으로 간단하게 구현할 수 있다.
# Spliting data into train and validation set for CNN
# for training : x_train, y_train
# for verification purposes : x_val, y_val
x_train, x_val, y_train, y_val = train_test_split(train_x_cnn, train_y, test_size=0.1, random_state=121)
print(x_train.shape, x_val.shape, y_train.shape, y_val.shape)머신러닝 튜토리얼 모델
GTSRB 데이터셋은 classID열이 존재하므로 label이 있는 지도 학습이다. 지도 학습 유형 중, 분류(classification) 알고리즘으로 진행이 가능하다. 또한 python의 sklearn을 통해 머신러닝 알고리즘을 적용하여 모델을 학습하였으며, 각 알고리즘에 대한 설명은 아래 링크에 추가로 달아놓았다.
분류 모델 구성
예측에 가장 적합한 모델을 개발하기 위해 머신러닝 알고리즘 3종류를 학습시킨 후 최적의 모델을 선정하였다. 머신러닝 알고리즘 SVR, DT, MLP을 이용한 SVM, Random Forest, CNN 모델을 비교하였다.
1. SVM 모델 구성
SVM은 제한된 샘플의 수를 일반화하기 위해 구조적 위험을 최소화하는 원칙에 기초한 머신러닝 알고리즘이다. SVM은 분류 및 회귀 문제에 사용될 수 있으며 회귀 문제의 경우 SVR(support vector regression), 분류 문제의 경우 SVC(support vector classification)라고 표현한다. SVR은 제한된 범위 안에서 가능한 많은 데이터가 들어가는 회귀선을 찾는 원리로 회귀를 수행한다. 선형 회귀가 아닌 경우에는 커널(kernel) 함수를 이용하여 가상의 차원을 추가하여 계산하며, RBF(radial basis function) 커널을 이용한 SVR은 예측 모델을 최적화하기 위해 조정할 수 있는 매개변수로서 C와 gamma를 조절할 수 있다. 경계를 결정하는 회귀선이 확정되면 학습용 데이터는 불필요하며 예측의 정확도가 높고, 사용이 편리하다는 장점이 있다.
주어진 데이터를 고차원 특징 공간으로 사상해주는 Radial Basis Function (RBF) 커널을 이용하고, gamma=0.00001, random state는 121로 설정하여 모델을 학습시켰다. 그림 6은 SVM 모델의 클래스별 분류 결과를 보여준다.
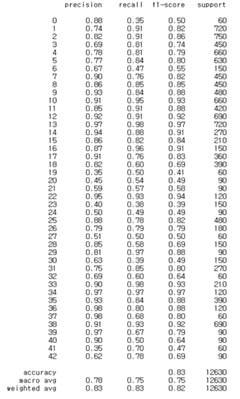
2. Random Forest(RF) 모델 구성
Random Forest는 무작위의 특성을 가지는 여러 개의 결정 트리를 생성하고, 각 트리의 특성 중요도를 취합하여 멀티 클래스를 예측하도록 학습하는 모델이다. RF 모델을 통해 생성된 여러 개의 결정 트리는 각각 다른 특성을 통하여 학습이 진행되기 때문에, 다양한 가능성을 고려할 수 있고, 더 넓은 시각으로 데이터를 바라볼 수 있다. RF 모델은 학습을 위해 필요한 결정 트리의 생성 개수를 지정해야 한다. 트리의 개수에 따라 증가하는 시간과 향상되는 정확도를 그래프로 확인해보았다.
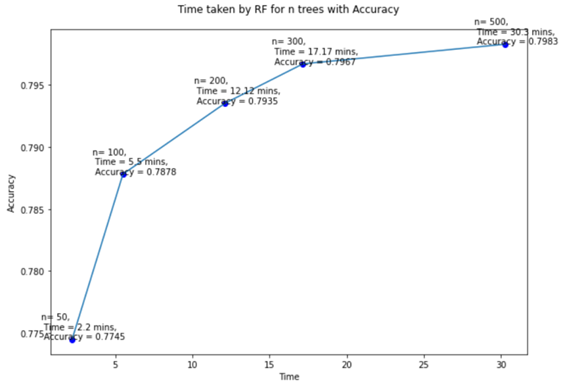
랜덤하게 생성된 트리가 모두 우수한 결과를 나타낸 것은 아니므로 분류 성능이 뛰어난 N개의 트리를 선택할 필요가 있다. 최상의 랜덤포레스트 모델을 선정하면 정확도가 약 80%까지 올라가는 모양을 보인다. 시간과 정확도를 고려하여 트리의 개수를 300개, random state를 121로 설정하여 학습시켰다. 학습시킨 결과 클래스별 정확도는 아래와 같다.
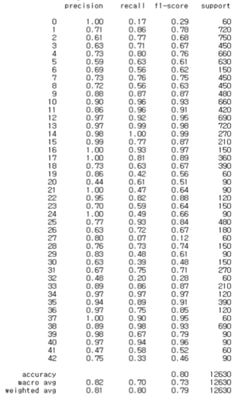
3. CNN 모델 구성
CNN 방법은 기존의 인공신경망을 연속적으로 나열하는 MNN (Multi-layer Neural Network) 방법을 이용하고 있다. CNN의 각 계층은 지역적 수용 필드(Local receptive field), 공유 가중치(Shared weight), 서브샘플링(Subsampling, Pooling)의 세 가지 아이디어가 적용되었으며 지역적 수용 필드, 공유 가중치를 반영하는 컨벌루션 계층(Convolution layer)과 서브샘플링 계층이 번갈아 수행되며 완전 연결 계층 (Fully Connected Layer)을 통해 분류 수행하는 계층모델이다. 기본적인 이 두 가지의 층은 여러 층으로 적재가 가능하다.
속도 제한 표지판을 인식하기 위하여 그림 11과 같은 4계층의 CNN을 구성하였다. 본 연구에서 사용된 CNN 아키텍처는 convolution 계층 4개, pooling 계층 3개, dropout 계층 5개, flatten 계층 1개로 구성되었다. 일반적으로 컨벌루션 계층과 서브샘플링 계층을 1개의 통합 계층으로 정의됨으로 만든 CNN 모델은 총 4개의 계층으로 구성되어 있다.
-
CNN 모델 구조

활성화 함수로는 ReLU 함수를 이용하였다. 기울기 감소 문제가 심하게 발생하지 않기 때문에 계산이 용이한 ReLU함수를 이용하여 모델을 구성하였다. 정수형태의 여러 클래스로 구성되어있기 때문에 다중 분류를 위해서 손실 함수는 categorical cross-entropy 함수를 사용하였다. adam optimizer을 사용하여 손실 함수의 최소값을 찾기 쉽도록 적용하였다. Dropout 계층의 비율은 0.2로 지정하였다.
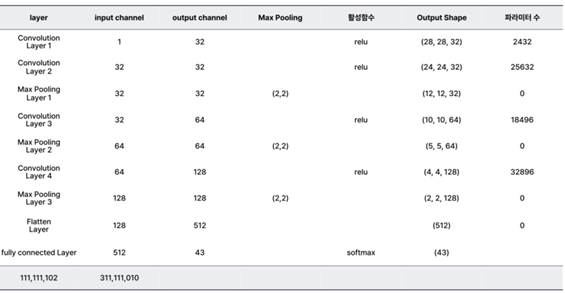
아래는 CNN 모델의 각 레이어별 입력 데이터와 출력 데이터의 크기, 네트워크가 학습시키는 파라미터의 개수 등을 요약한 표이다. -
전체 파라미터 수와 레이어별 Input/Output 요약
반복 횟수(epoch)를 10, batch size를 128로 주고 학습을 수행하면서 정확도와 손실의 변화를 그래프로 출력했다.
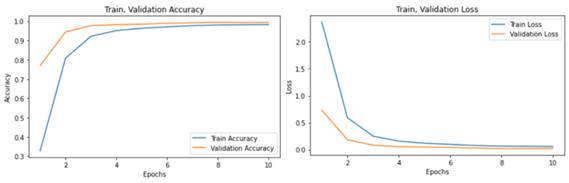
epoch가 증가할수록 정확도가 약 0.97까지 증가하는 추세를 보인다.
아래는 학습시킨 결과 클래스별 정확도이다.
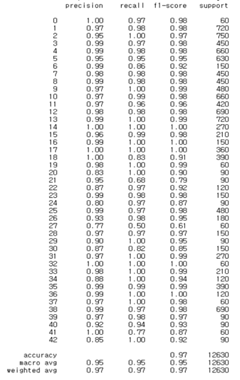
모델 성능 평가
학습 모델의 성능을 객관적이고 정량적으로 평가하기 위해 모델의 효율성을 판단하는 척도로 사용되는 정확도 (accuracy), F1 score 등을 파악했다.
-
분류기 성능 요약

SVM 모델, RF 모델, CNN 모델을 테스트한 결과 가장 높은 예측 성능을 보이는 알고리즘은
Convolution Neural Network (96.90%), Support Vector Machine (82.57%), 그 다음으로 Random Forest (79.67%) 순으로 정확도를 확인하였다.
support vector machine이 시간이 제일 오래걸리면서 정확도도 비교적 낮은 모양을 보였다. 랜덤 포레스트 분류기는 높은 차원의 특징벡터에 대해 SVM보다 빠른 속도로 분류할 수 있다는 장점이 있다. 정확도로는 CNN 모델이 약 97 퍼센트로 가장 높은 성능을 보인다. -
모델별 성능 비교
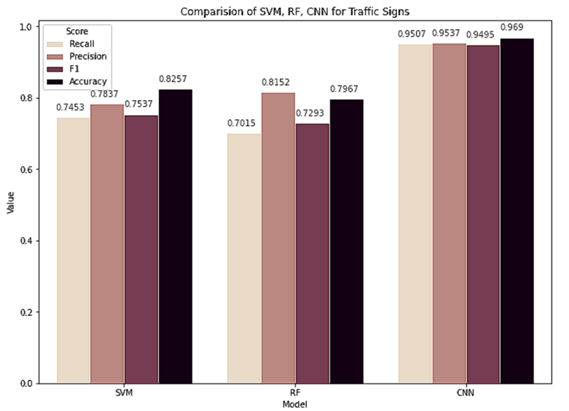
모델별 성능을 시각화하였을 때 랜덤 포레스트 모델이 SVM 모델과 비교하여 정확도는 떨어지지만 정밀도는 근소하게 높은 것을 확인할 수 있다. CNN 모델의 성능은 두 모델과 비교할 때 압도적인 성능을 보이는 것을 확인했다.
예측
가장 성능이 좋았던 CNN 모델을 이용하여 학습이 잘 수행되었는지 확인해보았다. 25개의 테스트 데이터를 불러와 실제 class와 예측 class를 출력했다. 예측된 결과를 비교해 보면 붉은색 글씨가 실제 정답과 불일치한 데이터로 2개의 불일치한 정답이 보인다.
- 샘플 데이터 25개의 분류 결과

결론
머신러닝 진행 시 데이터 가져오기, 데이터 전처리, 데이터 시각화, 데이터 검증, 데이터 정규화 등을 체계적으로 학습할 수 있는 분류 모델 성능을 비교하는데 목적을 두었다. 각 학습 과정에서 문제 해결에 필요한 부분 위주로 코딩이 간단하게 설계했다.
SVM, Random forest, cNN 세 모델을 비교분석 하였으며, 각 모델의 차이점과 알고리즘에 따른 학습 결과를 확인할 수 있었다. 모델을 살펴보면 기초적인 머신러닝 수준에서 각 모델마다 머신러닝이 어떻게 진행되는지를 중점적으로 간단하게 예제를 들어 설명하고 있으며, 각 모델의 성능을 확인할 수 있다. 실험 결과에서 전체적인 성능을 비교했을 때 CNN 모델이 SVM 모델이나 RF 모델에 비해 높은 인식률을 보여주었다. 성능이 가장 좋은 필터를 선택함으로써 의미있는 특징을 추출할 수 있게 되었으며, 추후 과정으로 화질을 개선하는 전처리를 통해 더 높은 성능의 표지판 인식률을 가진 분류기를 개발할 수 있다. 낮은 해상도와 대비로 인해 흐릿한 이미지를 개선하기 위한 히스토그램 정규화 또는 히스토그램 스트레칭을 적용하여 표지판의 숫자와 배경의 구분을 두드러지게 하고 그에 따른 성능 변화가 있는지 확인할 것이다. 또 각 계층마다 좀 더 의미 있는 특징이 추출될 수 있도록 컨벌루션 필터의 최적가중치를 연구하여 CNN 구조를 개선할 수 있을 것이다.
