컨벌루션 신경망
순방향 신경망의 한꼐를 극복하기 위해 1979년에 생체 신경망의 시각 정보 처리 방식을 모방해서 이미지를 처리하는 네오코그니트론이 제안되었고 이것과 역전파 알고리즘을 접목한 신경망이 나오게 되는데 그것이 컨볼루션 신경망입니다.
컨볼루션 신경망이 이미지 데이터를 어떻게 처리하고 성질이 무엇인지 그리고 한계와 한계를 위한 노력에 대해 이야기 해볼겁니다.
시각 패턴 인식을 위한 신경망 모델
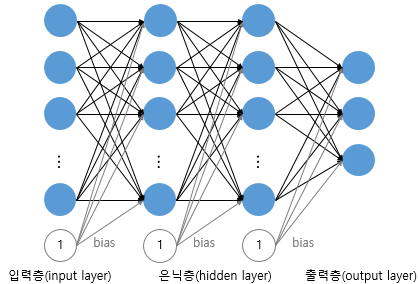
*이미지출처:https://wikidocs.net/24958
순방향 신경망으로 MNIST 필기체 숫자를 인식하려면 1차원 벡터로 변환해서 모델에 입력을 해야합니다. 그러면, 2차원 이미지였던 것이 1차원으로 펼쳐지게 되어서 인식의 어려움을 겪게 됩니다.
추가적으로, 이미지가 커질수록 데이터크기가 기하급수적으로 커지게 되어 엄청난 수의 파라미터 수도 증가하는 차원의 저주가 일어나게 되어 데이터 처리에 효율적이지 않습니다.
생체 시각 시스템을 모방한 인공 신경망
순방향 신경망으로는 이미지를 효율적으로 처리하지 못합니다. 그러면 어떻게 해야할까요?
일본의 공학자 쿠니히코 후쿠시마는 허블과 비셀이 발견한 동물 시각 시스템의 계층 모델을 인공 신경망으로 모델리하여 필기체 인식과 패턴 인식에 성공을합니다. 그것이 바로 네오코그니트론이고 훗날, 콘벌루션 신경망이 탄생하는데 지대한 영향을 미칩니다.
생체 신경망의 계층적 시각 정보 처리
- 뉴런은 아주 좁은 영역의 자극에 반응합니다.
수용영역: 뉴런이 자극을 받아들이는 영역
- 뉴런마다 다른 모양의 특징을 인식하도록 뉴런의 역할이 나뉩니다.
- 뉴런은 계층 구조를 이루며 시각 정보를 계층적으로 처리합니다.
네오코그니트론의 구조
생체 신경망의 처리 경로를 모방하고 단순 세포 계층과 복합 세포 계층을 정의했습니다. 그리고, 이 둘을 묶어서 여러 계층을 쌓은 신경망의 구조를 만듭니다.
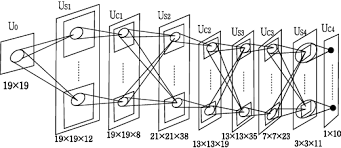
단순 세포 계층은 시각 정보의 다양한 특징을 학습하고, 복합 세포 계층은 특징의 크기를 줄이는 방식으로 수용 영역을 넓히면서 특징에 대한 위치 불변성을 제공합니다.
콘벌루션 신경망의 탄생
얀 르쿤은 네오코그니트론에 영향을 받아 콘벌루션 신경망을 제안하여 네오코그니트론의 설계 사상과 모델 구조를 따르고, 역전파 알고리즘을 학습 알고리즘으로 채택합니다.
콘벌루션 신경망은 보편적인 인공 신경망으로 활용이 되고, 특징을 인식하는 주요 연산을 합니다.
얀 르쿤은 최초의 모델인 르넷-5를 만들었습니다.

-
콘벌루션 계층: 콘벌루션 연사능로 특징을 학습합니다.
-
서브샘플링계층: 풀링 연산으로 위치불변성을 제공합니다.
-
위의 둘을 완전 연결 계층으로 연결하여 모델링합니다.
콘벌루션 신경망의 구조
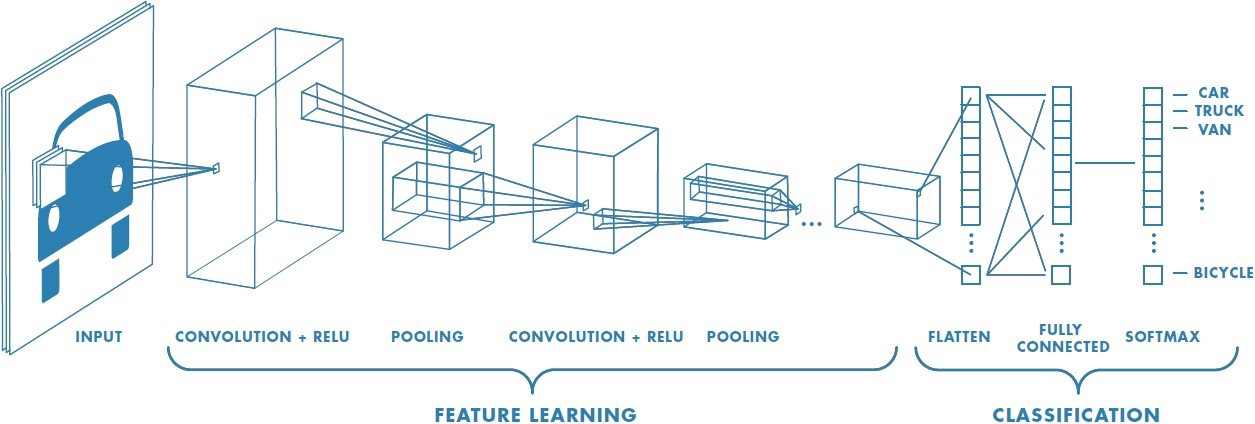
*콘벌루션 계층과 서브샘플링 게층이 번갈아가면서 반복되어 연결되는 구조
컨볼루션 계층은 연산을 통해 이미지의 다양한 특징을 학습하고, 서브샘플링 계층은 풀링 연산을 통해서 이미지의 크기를 줄여 특징의 작은 이동에 대한 위치 불변성을 갖게 합니다.
컨벌루션 연산과 서브샘플링 연산이 많이 실행이 되면 될수록 뉴런의 수용 영역은 점점 넓어지게 되어서 복잡한 특징까지도 계층적으로 인식이 가능합니다.
컨벌루션 연산
컨볼루션은 두 함수를 곱해서 적분하는 연산으로, 함수 f에 다른 함수 g를 적용하여 새로운 함수 h를 만들 때 이용이됩니다.
컨벌루션 연산

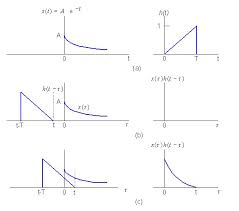
위의 식을 설명하자면, 두 연속 함수 f(t) 와 g(t)의 콘볼루션 연산 (f* g)(t)는 적분식으로 정의합니다. 이때, 함수 g(t)는 콘볼루션 필터 혹은 콘벌루션 커널이라고 부릅니다.
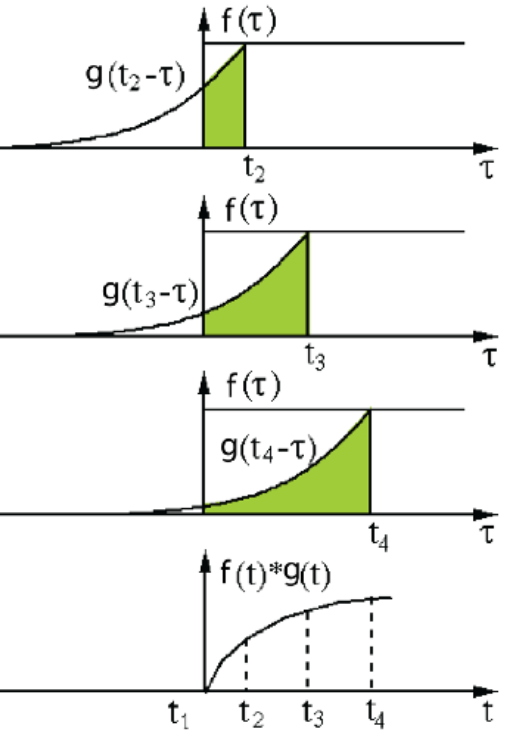
*반전

다시 이동하여 f와g(t-)를 내적하여 적분한 형태로 표현을 합니다.
*알파벳은 달라도 의미는 같습니다.
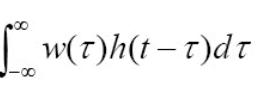
식에 대한 설명을 하면, (f* g)(t)는 시간에 대한 함수로 두 함수를 t의 전구간에서 내적하면 새로운 함수가 만들어지게됩니다.
그러나, 위의 w()식은 t의 함수가 아니라 고정이 되어있고 h(t-)함수는 시간축 t를 따라서 전 구간에서 슬라이딩하며 내적합니다.
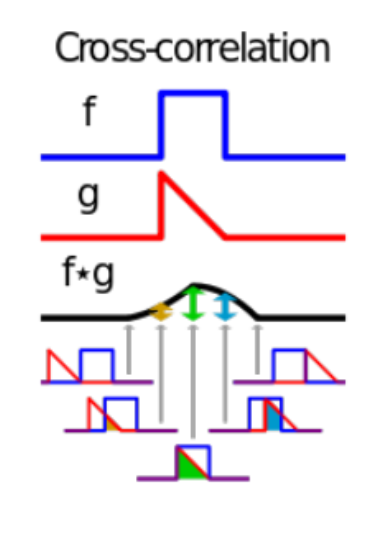
교차상관 연산
교차상관 연산은 컨불루션 연산과 유사합니다. 두 함수의 유사도를 측정하는 연산으로 콘벌루션 연산에서 반전을 시키지 않는 형태입니다. 동일한 연산과정입니다.
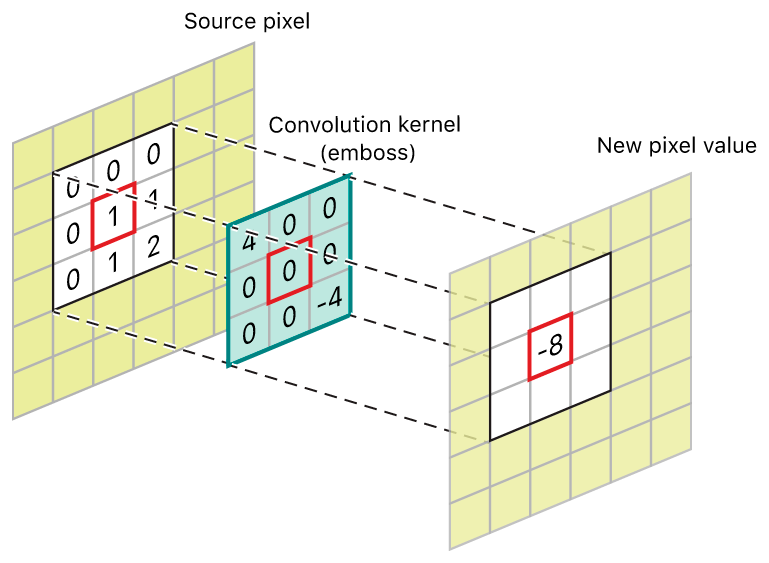
이미지 콘벌루션 연산
위에서 말했듯이 콘벌루션 연산은 이미지의 특징을 추출하거나 변환 시 사용을 한느 것으로 경계선 검출, 스무딩, 샤프닝과 같은 이미지 처리를 하는 것입니다.
경계선 검출 이미지 컨볼루션 연산 정의
이미지에 대한 콘벌루션 연산을 식

x: 2차원 이미지, w: 콘벌루션 필터 , (i,j): 픽셀 인덱스, 이미지에 대한 콘벌루션 연산 (x w)(i,j)
이미지는 입력함수가 되고 콘벌루션 필터는 가중치 함수가 되어 픽셀 단위로 가중합산을 합니다.
이미지를 처리할 때는 교차연산을 이용합니다.
이미지 컨볼루션 연산 과정
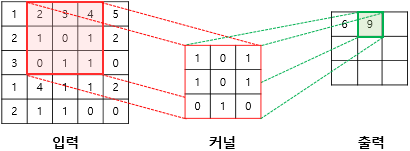
콘벌루션 필터의 슬라이딩 순서
가로 방향으로 한 줄을 슬라이딩하고 나서 세로 방향으로 한 칸씩 아래로 이동하는 순서로 진행이됩니다.
이미지 콘벌루션 필터 설계 예시
경계선 검출
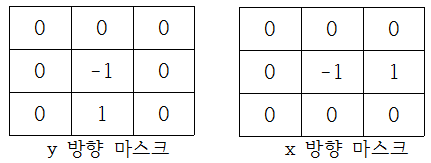
경계선 검출은 이미지에서 사물의 경계를 찾는 연산이고, 빛의 강도가 크게 변화므로 인접한 픽셀의 변화량을 계산하는 미분 필터를 사용합니다. 미분필터는 좌우 상하 픽셀값의 변화량을 계산하도록 설계합니다.
스무딩
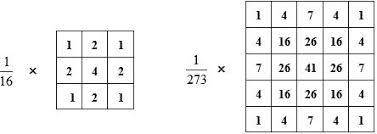
스무딩은 이미지의 색깔이 부드럽게 변하도록 만들어주는 연산으로, 선명한 이미지가 몽환적인 느낌의 흐릿한 이미지로 바뀝니다. 그리고, 가우시안 필터를 사용합니다.
샤프닝
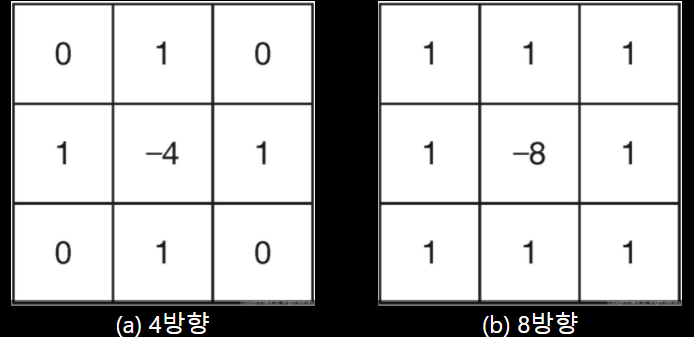
샤프닝은 이미지를 선명하게 만드는 연산으로 선명한 윤곽을 갖는 이미지를 만들기 위해서 2차 미분 계산하는 라플라스 필터를 사용합니다.
위의 내용처럼 연산의 목적에 맞게 컨벌루션 필터를 설계해야합니다.
콘벌루션 신경망의 콘벌루션 연산
*콘벌루션 신경망
이미지 특징 추출을 위해 필터를 학습하고, 뽑힌 특징들의 추상화 수준에 따라서 콘벌루션 연산을 계층화하면서 실행합니다.
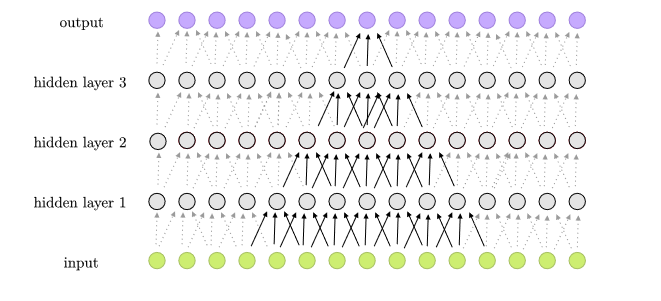
https://commons.wikimedia.org/wiki/File:1D_Convolutional_Neural_Network_feed_forward_example.png
{kind=link}
*콘벌루션 필터
-
다양한 특징 추출
-
특징이 많을 수로 필터의 개수 증가
-
필터의 크기와 개수는 계층별로 특징의 추상화 수준이 달라서 다르게 설계하도록 함
-
추상화 수준이 높을 수록 많은 필터가 필요함
-
필터의 값은 특징 추출이 잘 되도록 학습을 통해 정합니다.(최적의 값을 미리 정하지 않고 찾으면서 정합니다.)
- 입력 데이터의 형태
입력데이터가 이미지라면, 이미지는 RGB채널이 있기에 3차원으로 표현하고, 이미지에 투명도를 추가하면 4채널,
흑백 이미지는 1채널입니다.
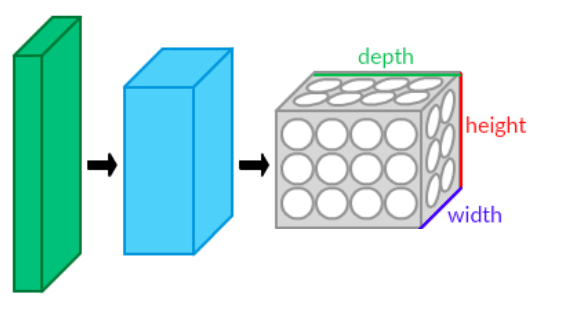
*Tensor(신경망의 입력 데이터)
[Width] X [Height] X [Depth]
-
[Width] X [Height]: 공간 특징을 말합니다.
-
[Depth]: 채널의 특징을 표현하는 것입니다.
ex)컬러 이미지 : [Depth] = 3, 투명도 포함 컬러 이미지: [Depth]=4, 흑백 이미지: [Depth]=1
- 컨벌루션 필터의 형태
*Tensor(컨벌루션 필터)
[Width] X [Height] X [Depth]
채널 방향으로 슬라이딩 하지 않기에 필터의 [Depth]는 입력의 [Depth]와 같습니다.
https://developer.apple.com/documentation/accelerate/blurring_an_image
- 컨볼루션 필터의 크기와 개수
-
콘벌루션 필터 크기에 따라 뉴런의 수용 영역이 달라집니다.
-
크기가 작으면 조금씩 늘려가면서 특징을 학습합니다.
-
크기가 크면 빠르게 확장하면서 특징을 학습합니다.
즉, 컨볼루션 필터 크기에 따라 신경망의 성능이 달라지기에 최대화하여 설정해야 하고, 보통 3x3, 5x5, 7x7크기를 사용합니다.
필터의 개수는 또한 이미지의 복잡도에 따라 달라지기에 이미지의 특징이 다양할수록 더 많은 콘벌루션 필터를 사용해야 한다는 것을 유의해야합니다.
- 표준 콘벌루션 연산
모든 채널에 대해 합쳐서 픽셀별로 가중합산을 합니다.
- 콘벌루션 신경망의 뉴런은 어디에 있을까?
실제로 연산 과정을 하는 뉴런은 보이지 않지만 이미지와 컨벌루션 필터가 가중 합산 연산을 할 시 하나의 뉴런이 실행이 된 것으로 볼 수 있습니다.
- 지역 연결을 갖고 가중치를 공유하는 뉴런
지역연결은 컨벌루션 필터와 겹쳐진 영역만 연결되는 뉴런입니다.
이러한 컨볼루션 필터는 모든 뉴런에서 재사용이됩니다.
그로 인해 컨볼루션 신경망의 뉴런은 지역 연결을 가지면서 가중치를 공유하는 뉴런이라는 특징을 갖게 됩니다.
- 액티배이션 맵의 생성
액티배이션 맵은 컨벌루션 연산 결과로 만들어지는 이미지를 말하고, 이런 이름이 붙은 이유는 뉴런의 출력(액티베이션)과 뉴런의 출력 모양(맵)으로 만들어지기 때문입니다.
또한, 입력 데이터의 특징을 추출한 결과이기에 피처 맵(feature map)라고도 불립니다.
참고로, 컨볼루션 필터 개수와 액티베이션 맵의 채널 수와 같습니다.
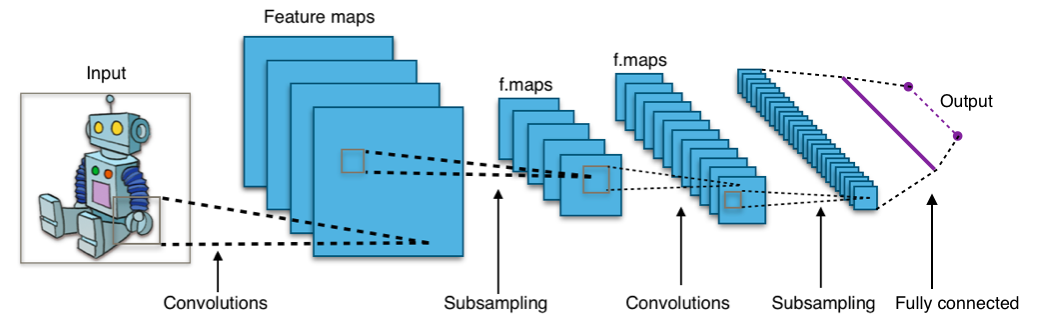
https://commons.wikimedia.org/wiki/File:Typical_cnn.png
{kind=link}
- 두 번째 계층의 콘벌루션 연산
컨벌루션 필터의 채널 수는 입력 데이터의 채널 수와 같아야한다.
- 뉴런의 활성함수 실행
각 계층의 뉴런은 동일한 3차원 텐서 형태로 배열이 되어었고 활성 함수를 이용하여 모든 뉴런에 활성 함수를 적용합니다.
- 순방향 신경망의 계층과 비교
-
데이터가 1차원에서 3차원으로 확장(뉴런의 배열도 같이 확장)
-
뉴런은 컨벌루션 필터 크기의 지역 연결을 갖음
-
같은 채널의 뉴런들은 가중치를 공유함
컨벌루션 신경망에서 서브 샘플링 연산
서브 샘플링은 데이터를 낮은 빈도로 샘플링 했을 시 샘플을 근사하는 연산으로 데이터가 이미지이면 크기를 줄여나가는 연산이 되므로 다운 샘플링이라고도 불립니다.
- 풀링 연산을 이용한 서브 샘플링
이미지 상에서 필터를 슬라이딩하면서 구하는 연산으로 주로 평균(average pooling)이나 최댓값(Max pooling)을 구할 때 사용하지만 간혹 최소, 가중합산, L2 노름 때도 사용이 됩니다.
*max pooling
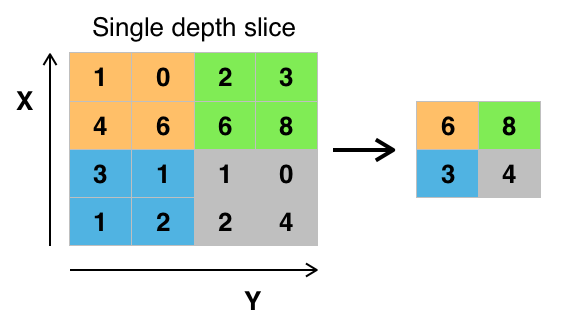
https://commons.wikimedia.org/wiki/File:Max_pooling.png
{kind=link}
*average pooling
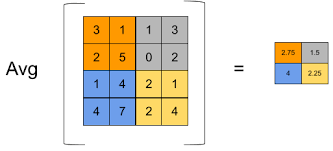
- 컨벌루션을 이용한 서브 샘플링 연산
슬라이딩 간격을 조정해서 하면 가능합니다.
- 컨벌루션 신경망에서의 풀링 연산
계층별로 풀링 필터의 크기와 슬라이딩 간격을 지정해주기에 채널 수가 유지가 됩니다.
- 풀링필터의 크기와 위치 불변성
핵심은 풀링 필터의 크기를 구할 때 어느 정도 크기의 수용 영역 안에서 위치 불변성을 줄 것인가 결정하는 것으로 보통은 2X2 필터를 많이 사용은 하지만 최대 성능을 낼 수 있도록 정해야 합니다.
- 그림으로 보는 컨벌루션 신경
스트라이드(stride)
스트라이드는 필터의 슬라이딩 간격을 말하는 것으로 보통 stride=2를 설정하여 사용을 하고, 간격에 따라 출력하는 이미지의 크기가 달라집니다.
*공식
O = (N-F)/S + 1
*N: 입력 데이터 크기, F: 컨벌루션 필터 크기, S: 스트라이드, O: 출력 데이터 크기
패딩
사실, 컨벌루션 연산을 하면 필터가 입력 이미지 내에서만 슬라이딩을 하기에 출력이미지의 크기가 당연히 입력 이미지 보다 작게 되어 횟수의 제한이 걸리게 됩니다.
그러므로 픽셀을 추가하여 이미지의 크기를 유지하는 방법인 패딩을 사용해야 합니다.
0 = {(N+2P)-F}/S +1
*N: 입력 데이터 크기, P:패딩, F: 컨벌루션 필터 크기, S: 스트라이드, O: 출력 데이터 크기
