참여 사이트 : https://www.kaggle.com/c/2019-2nd-ml-month-with-kakr/data
필요한 라이브러리
- xgboost = 1.3.3
- lightgbm = 3.1.1
- missingno = 0.4.2
- scikit-learn
Baseline
-
Baseline셋팅하기
-
라이브러리, 데이터 가져오기
i) 필요한 라이브러리 import 하기
ii) 데이터 경로 지정하기
-
데이터 이해하기
i) 데이터 살펴보기
ii) 데이터를 통해 변수 부르기
iii) 학습데이터에서 라벨 제거하기
iv) 학습데이터와 테스트 데이터 합치기
v) 간단한 전처리
-
모델 설계(모델링)
i) blending : baseline 커널에서는 여러 가지 모델을 함께 사용 후 결과 섞기
ii) Ensemble: 여러 개의 학습 알고리즘을 사용하여 예측 결합을 통해서 최종 예측 도출
iii) Voting: 서로 다른 알고리즘을 가진 분류기 결합하여 분류 문제에서 쓰임
iv) Averaging: 회귀 문제에 사용된다. 가중평균하여 사용한다
v) Average Blending: 산술 평균하여 모델 만든다

vi) Cross Validation: 교차 검증을 통해 모델 성능 평가
vii) Make Submission File
cross_val_score()함수는 회귀모델을 할 경우 R^2점수를 반환하고 그 값이 1에 가까울 수록 모델이 잘 학습이 된 것입니다. 그리고 상대적 성능이기 때문에 직관적으로 파악 가능

-
하이퍼 파라미터 튜닝
i) 파라미터란?
모델 파라미터와 하이퍼 파라미터로 나뉘는데요 전자는 모델이 학습하면서 최적화가 되어야하는 것을 의미하고 후자는 모델이 학습하기 위해 미리 넣어주는 파라미터입니다.
ii) 내 입맛대로 데이터 재구성하기.
-
삭제
-
추가
-
기타 등등
iii) RMSE계산
-
train_test_split 함수 : 훈련 데이터셋과 검증 데이터 셋으로 나눔
-
mean_squared_error : RMSE 점수 계산
-
np.log1p()변환이 되므로 np.expm1()추가
-
random_state : 특정값 고정
iv) 그리디 탐색(grid search)
: GridSearchCV를 통해서 탐색하고자 하는 하이퍼파라미터 와 시도해볼 값을 지정하기만 하면 되는 것입니다.
그러면 교차 검증을 통해 평가 가능.
사람이 지정한 범주 내에서는 최적을 찾지만 그것이 무조건 최적인지는 의문이다.
적은 수 탐색에 유리
반복횟수로 컴퓨터 자원 제어
V) 랜덤 탐색(random search)
: 사람이 탐색할 하이퍼 파라미터의 공간만 정해두고 랜점으로 조합한다.
그러므로 최적의 조합을 찾을 수 있음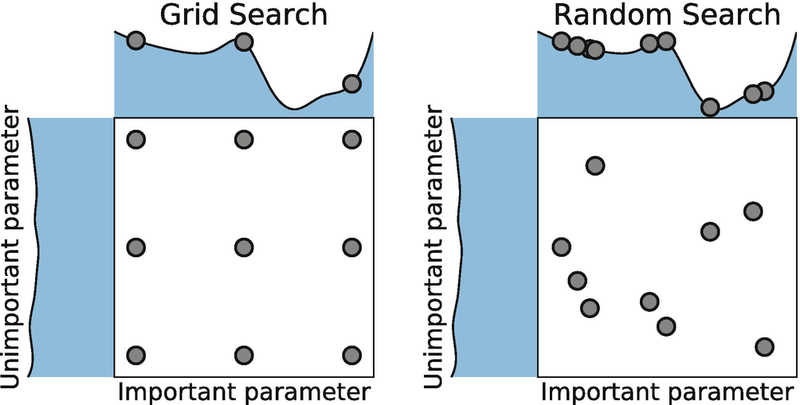
vi) Emsemble 방법
: 최상의 모델을 연결하는 것.
vii) 최상의 모델과 오차 분석
: 최상의 모델을 분석하며 문제에 대한 통찰
RandomForestRegressor가 정확한 예측 만들기 위한 상대적인 중요도을 알려준다
: 시스템이 특정한 오차를 만들었다면 왜 그런 문제가 생겼는지 이해하고 찾기
