입력 계층(P68)
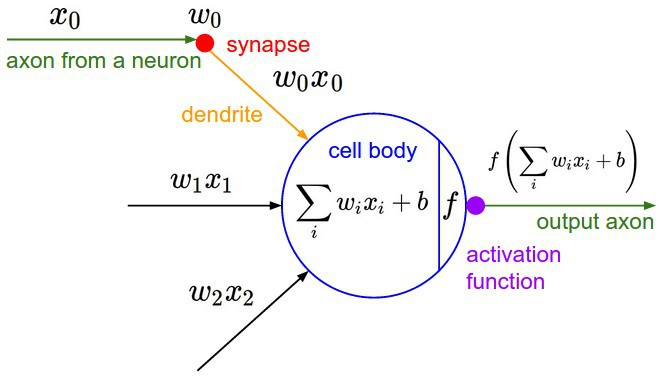
- 순방향 신경망: 입력데이터(벡터)을 전달. 그러므로 벡터의 크기가 곧 뉴런의 수.
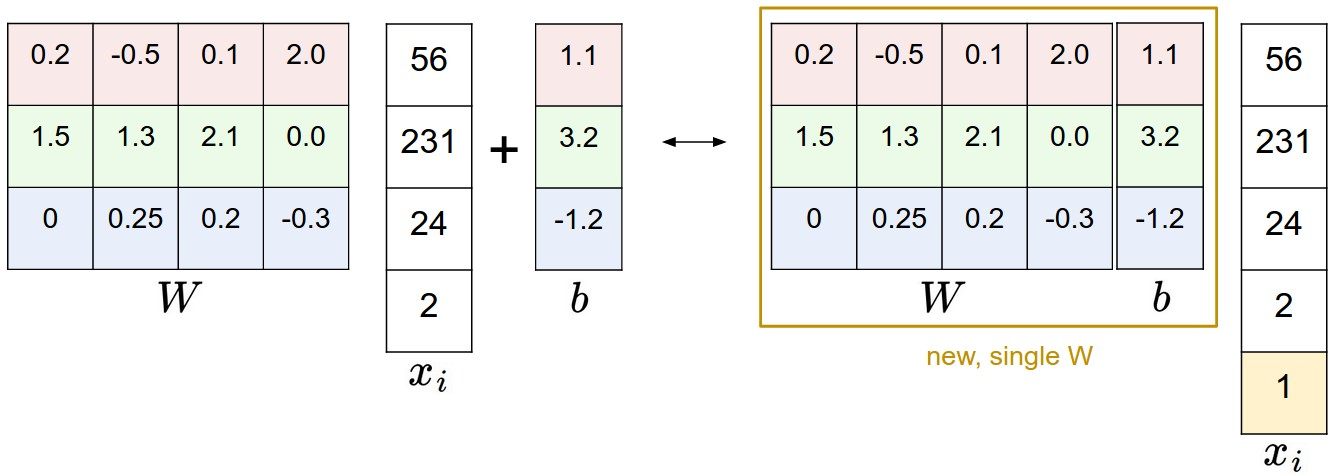
- 이미지가 입력데이터로 들어올 경우 1차원 벡터로 변환 후 입력 계층구성.
활성 함수(P69)
-
활성함수
- 입력된 데이터의 가중 합을 출력 신호로 변환(은닉 계층)
- 인공 신경망에서 이전 레이어에 대한 가중 합의 크기에 따라 활성 여부
- 레이어의 역할에 따라 선택적으로 적용

- 종류
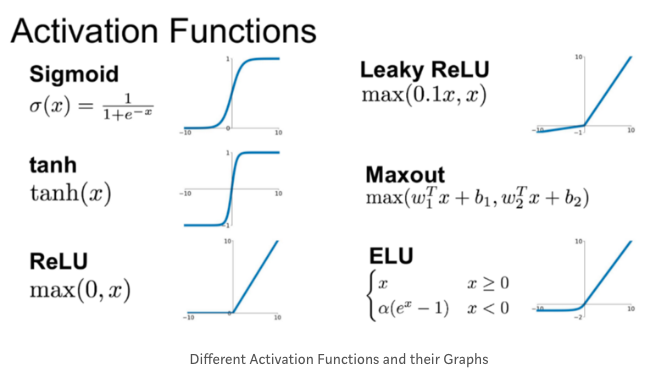
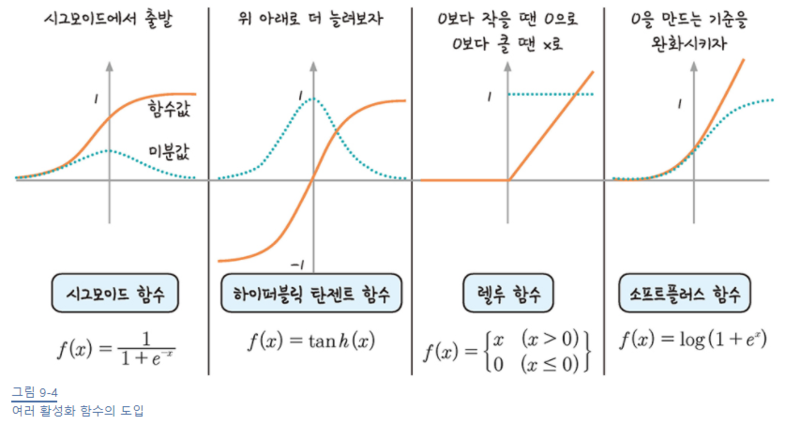
시그모이드
Preview
- 역사: 1984~1986에 역전파 알고리즘 등장으로 시그모이드 계열 함수 등장.
-
특징: 연산 속도 느리고 그레디언트 소실 원인 --> 신경망 학습에 좋지 않음
: 값을 고정 범위로 만들어주는 스퀴싱 기능이 필요한 구조에선 사용
스쿼싱 함수(P70)
-
특징
- 실수값을 고정 범위로 만들어준다
- 출력 계층에서 실숫값을 확률로 변환할 때 시그모이드나 소프트맥스 함수 사용
- 변수값 조절을 위한 게이트 연산 시, 게이트 값을 [0,1] 범위로 변환하기 위해 시그모이드 함수 사용
- 값의 범위가 존재하는 데이터 추출 시, 시그모이드나 하이퍼볼릭 탄젠트 사용하여 값의 범위 맞춤
계단함수(P70)
-
뉴런의 활성과 비활성 상태를 1과 0으로 표현
-
모든 구간에서 미분값이 0이므로 역전파 적용 불가

시그모이드 함수(P71~72)
-
계단함수는 역전파를 사용할 수 없지만 이 함수는 미분 가능하다.
-
S자 형태
-
함숫값의 범위 [0,1]
-
모든 구간에서 미분이 가능하고 증가함수이기에 미분값은 항상 양수이다.
-
양수만 출력하므로 학습 기울기가 진동하여 학습속도 느림.
-
최적화 경로가 최적해를 향해 바로 못 가고 좌우로 진동하면서 간다.
-
지수함수가 포함되어 연산 비용이 많이 든다
-
그래디언트 포화가 발생하여 학습이 중단
*포화: 입력값이 변해도 함숫값이 변화하지 않는 상태
*그래디언트 포화: 시그모이드 함수 끝부분에서 미분값이 0으로 포화되는 상태
-- 이 의미가 원함수가 특정 값에 수렴을 하게 되면 미분값이 고정이 되어서 0이 된다는 것인가요?
- 그레이디언트가 0으로 포화되면 그레이디언트 손실이 일어나 학습 진행 안됨

- 진동, 발산 개념
https://m.blog.naver.com/since201109/220838840503
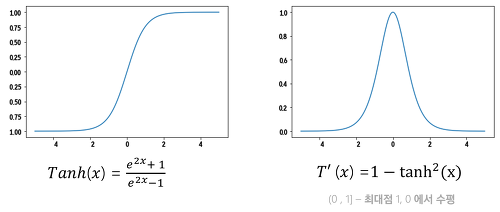
하이퍼볼릭 탄젠트 함수(P72)
-
S형함수이다.
-
함숫값이 [-1, 1]이다
-
함수 정의에 지수 함수가 포함되어 있어서 연산 비용이 많이 든다
-
그래디언트 포화가 발생하여 학습이 중단
-
시그모이드 함수의 선형 변환식
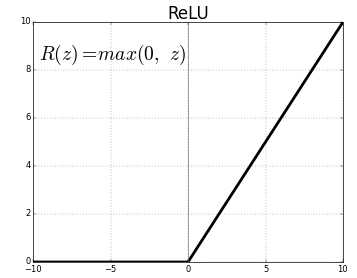
ReLU
Preview
- 역사: 2011년 딥러닝 시대, ReLU계열의 활성 함수들 등장
- 특징: 선형성 -> 연산 속도 빠름 , 학습 과정 안정화
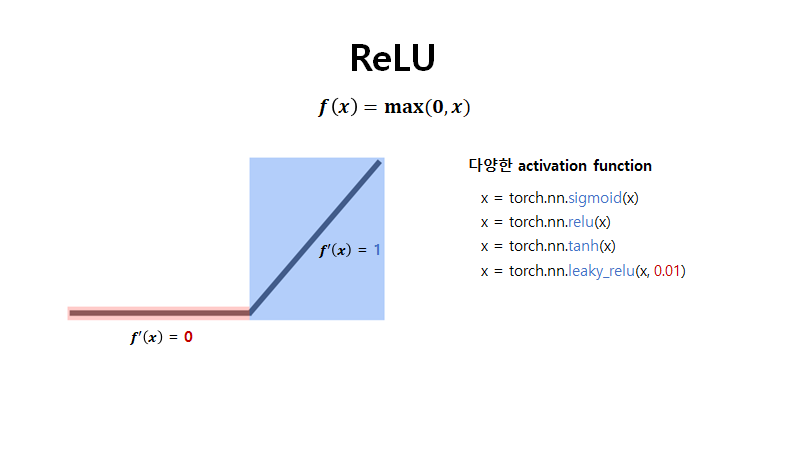
ReLU함수(P73)
-
입력값 >= 0이라면 그대로 통과
-
입력값이 < 0이라면 0을 출력(음수구간의 데이터는 0이 되어서 추가 연산량이 줄어든다)
-
즉, 입력값이 양수인 경우에만 활성 상태
-
포화문제 해결
-
연산이 단순하기 때문에 추론이 빠르다
-
미분 계산이 필요 없다
-
양수구간이 선형함수이기에 그레디언트 소실이 생기지 않아 안정적 학습이 가능하다
-
양수만 출력하기에 학습 경로가 진동하면서 학습 속도가 느려짐
-
죽은 ReLU가 발생하여 학습이 진행되지 않을 수 있다(P74)
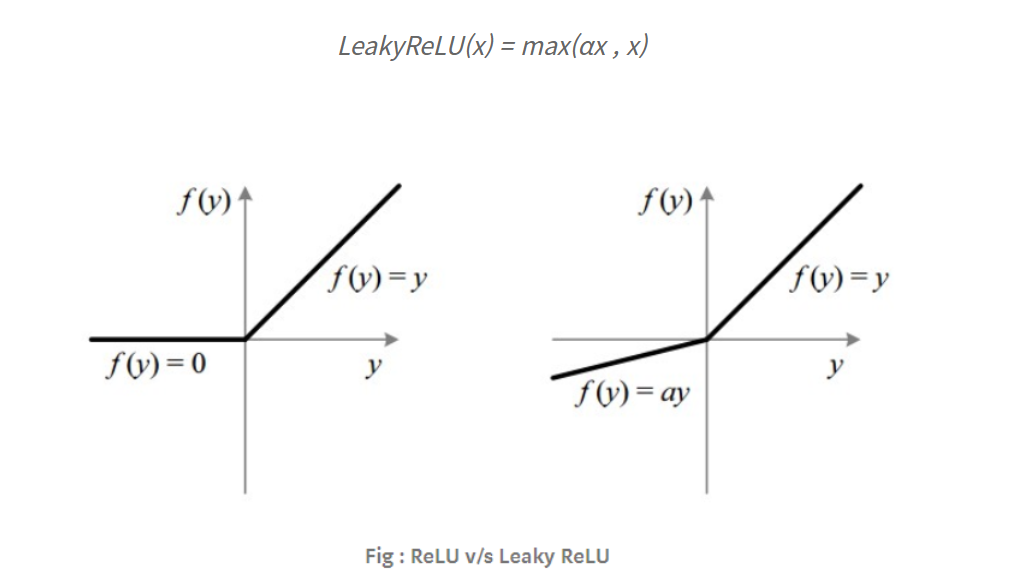
릭키 ReLU함수(P75)
-
죽은 ReLU문제를 해결하기 위해 음수 구간이 0이 되지 않도록 약간의 기울기를 준 것
-
음수 구간의 기울기를 주면 작은 그레디언트가 생겨서 학습 속도가 빨라지지만 기울기가 고정이 되어있기에 최적 성능을 내긴 쉽지 않다.
-
기울기가 작지만 큰 음숫값이 들어오면 출력값이 -무한대로 발산한다
PReL(P75)
-
뉴런별로 기울기 학습이 가능하여 성능 개선이 된다
-
학습시켜야할 대상을 보고 역전파에 의해 값을 변형시킴
-
데이터셋이 클 때는 좋지만 작을 때는 오버피팅 가능성
-
기울기가 작지만 큰 음숫값이 들어오면 출력값이 -무한대로 발산한다.
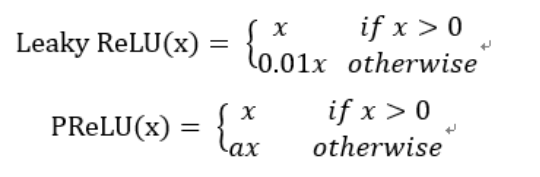
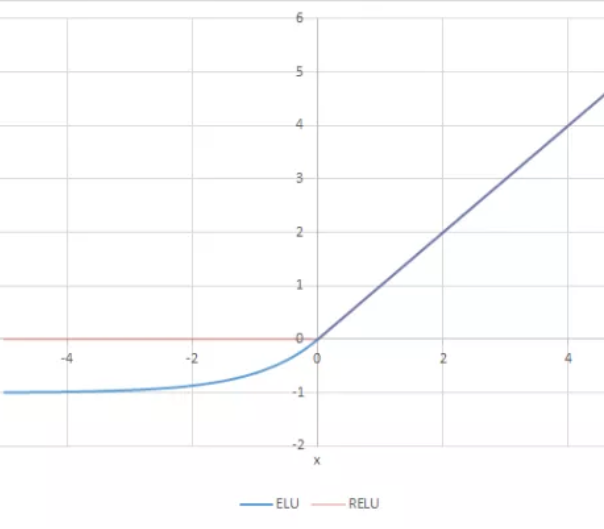
ELU(P76)
- 음수 구간이 지수 함수 형태로 정의 되어 있어서 아무리 커져도 0에 가까운 일정한 음수값으로 포화되어 아주 큰 음수값이 입력되어도 함숫값이 커지지 않기 때문에 노이즈에 민감해지지 않는다.
맥스아웃 함수(P76)
-
활성함수를 구간 선형 함수로 가정해서 각 뉴런에 최적화된 활성함수를 함수를 통해서 찾기.
-
뉴런별로 선형 함수 여러 개 학습 후 최댓값 취하기.
-
ReLU의 일반화된 형태
-
맥스아웃 유닉: 학습을 위해 뉴런을 확장한 구조로 선형 함수를 학습하는 선형 노드와 최댓값을 출력하는 노드로 구성이 된다.
-
선형노드: 뉴런의 가중합산 같은 형태
-
최댓값출력노드: 구간별 최댓값을 갖는 선형함수 선택
-
볼록 함수 근사 능력: 선형 노드의 개수에 따라 다르다. 선형 노드
i) 선형 노드 개수 2개 : ReLU와 절댓값 함수 근사 가능
ii) 선형 노드 개수 5개 : 2차 함수를 근사한다.
Swish함수(P78)
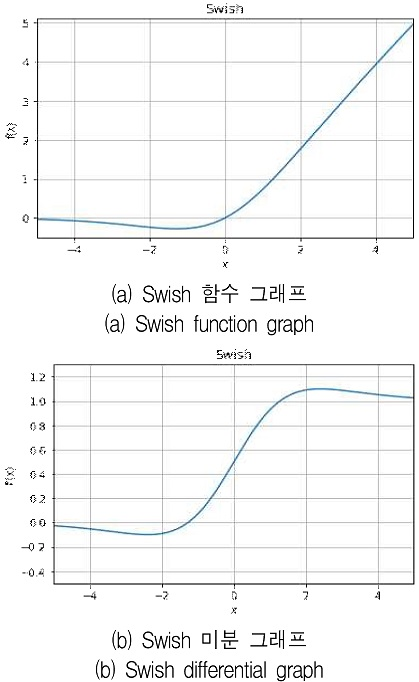
-
구글 브레인에서 찾음
-
AutoML로 찾은 최적의 활성화 함수입니다.
-
선형함수 X와 시그모이드의 곱형태이다
-
인공 신경망의 성능에 최적
-
무한한 값을 가진다
-
학습하는 동안 0근처에서 기울기 값이 포화되는 것을 막는다
-
네트워크 안에서 정보를 잘 흐르게 함으로 초기값과 학습률에 더 민감하다
-
음의 값에 대한 제한이 있기에 강한 정규화 효과를 주고과적합을 줄일 수 있다
-
작은 음수 값에도 음수 결과값이 만들어지기 때문에 표현력을 증가시키고 기울기 흐름 개선
-
논문에서 실험 결과를 ReLU와 Swish를 비교함
http://www.ki-it.com/_common/do.php?a=current&b=21&bidx=2369&aidx=27726 -
code

신경망 모델의 크기(P79)

- 관련 공식 없음(직사각형 넓이구하는 것처럼요)
-
크기: 너비와 깊이로 정해진다
-
너비: 계층별 뉴런의 수
-
깊이: 계층의 수
-
데이터 관계 복잡하다면, 학습 뉴런 수 줄여주기
-
추상화 수준이 높다면, 계층 수 줄이기
-
허나, 이걸 보자마자 파악하는 건 어렵습니다. 그러므로 적절한 모델의 크기를 알려면 경험적이나 통상적인 크기 범위 정하고 성능 분석 후 최적 크기 탐색
모델 크기 탐색(P79~80)
- 그리드 서치(grid search)
-
파라미터별로 구간 정하여 등간격으로 값을 샘플링한다
-
3개씩 정해진다.
-
grid에 해당되는 모든 값들을 한번 씩 훈련시켜서 가장 좋은 조합찾기
-
병렬 탐색 진행이다
-
grid해당 점만 테스트가 가능하다.
- 랜덤 서치(random search)
-
여러 파라미터 조합하여 랜덤하게 값 샘플링한다.
-
9개씩 정해짐
-
다양한 조합이 가능
-
골고루 테스트할 수 있기에 성능이 좋음
-
최종 선택 조합이 정말 최선인지 확인은 어렵다
-
최적 조합 찾는데 많은 시간이 걸림
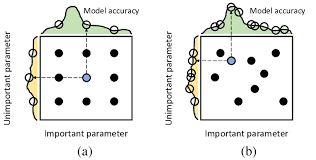
- NAS(네트워크 구조 탐색 방법)
-
자동 모델 탐색 방법
-
최적의 모델 생성 방법으로 하는 강화학습
-
유전 알고리즘
-
베이지안 기법 구현
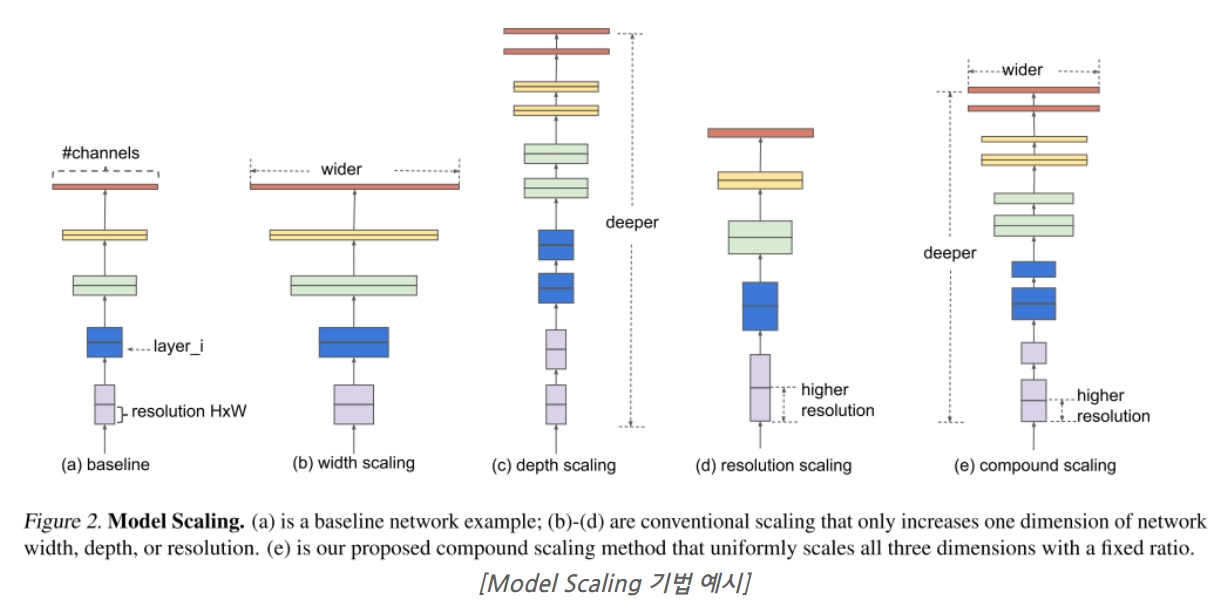
모델 크기 조정(P80~82)
*너비,깊이,해상도를 동시에 늘린 것이 가장 좋다
신경망 학습 관련 내용(*)
시그모이드 함수와 크로스 엔트로피 손실
-
시그모이드 함수 포화: 함수 양 끝부분에 그레디언트 포화가 발생하여 학습 중단이 된다
-
시그모이드 함수 or 소프트 맥스 + 크로스 엔트로피 손실(출력계층) : 일부 구간에서 포화 발생 안함
-
ReLU 와 softplus(양수 구간 포화 안됨)
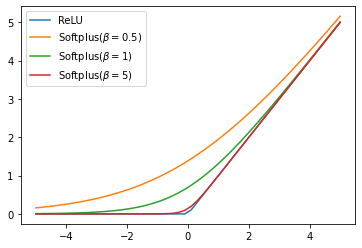
- 시그모이드 함수의 지수 항이 크로스 엔트로피의 로그 함수에 상쇄되어 소프트 플러스 함수 생성
양수만 출력하는 활성 함수의 최적화 문제
-
문제: 활성함수의 출력이 항상 양수이면 학습 경로의 방향이 크게 진동하여 느려지는 문제가 일어난다
-
원인:
-
양수만 출력하는 활성함수를 모두 은닉계층에서 사용
-> 첫 은닉계층을 제외한 모든 입력은 양수
- 뉴런의 입력이 항상 양수이면 지역 미분도 양수
- 모든 차원이 양수가 되어 가중치를 업데이트할 때 한 방향으로만 이동하게 되어 최적해로 곧바로 가지 못함
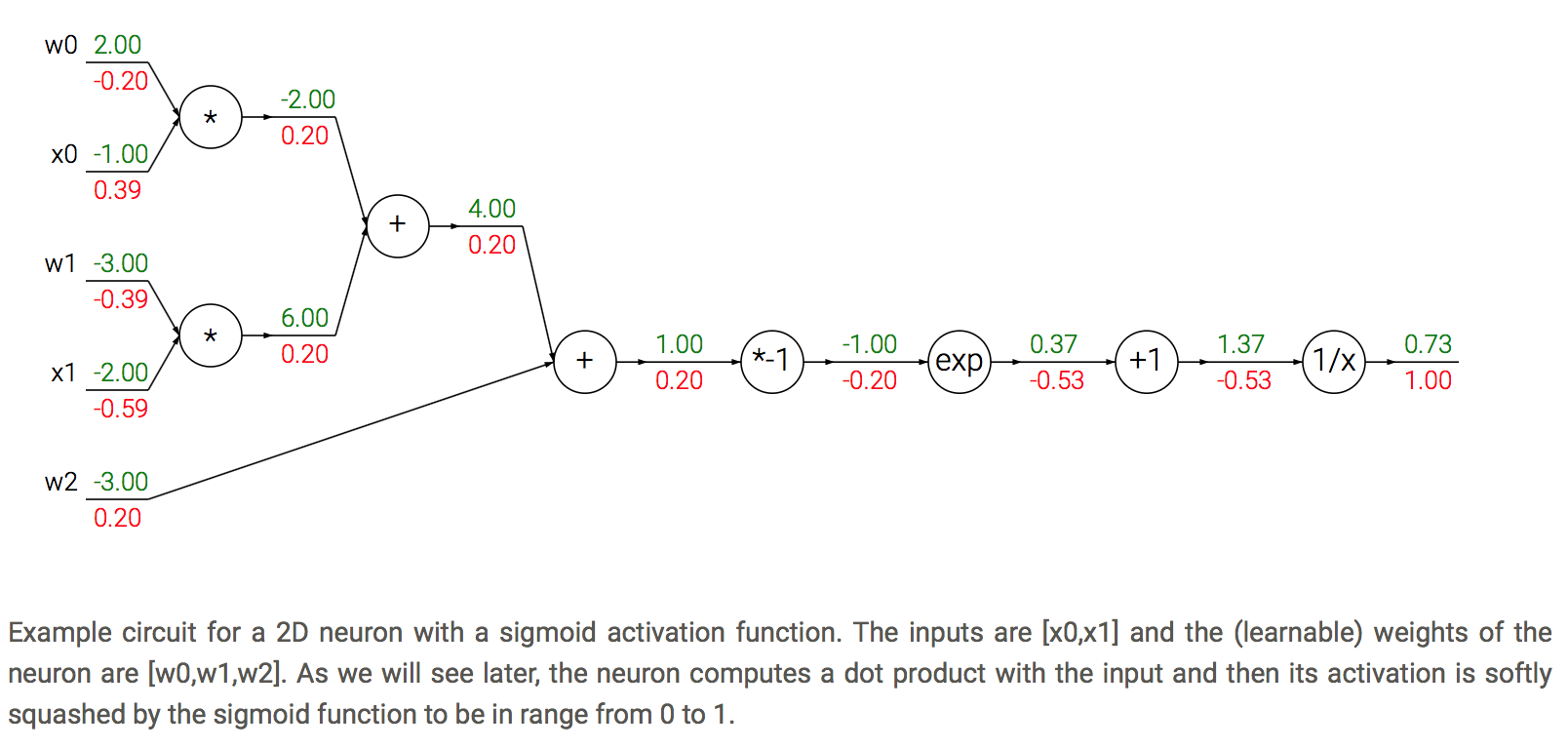
죽은 ReLU
-
뉴런이 계속 0을 출력하는 상태
-
가중치를 초기화 못하거나 학습률이 매우 클 때 발생
-
가중치 음수, 가중합산이 음수가 되어 ReLU는 0을 출력하고 그레디언트도 0이되어 학습 진행 안됨
미분 불가능한 활성 함수
- 미분이 안되는 함수를 사용해도 된다
--> 근사 방식(근접한 값)으로 함수를 표현하기 때문에 약간의 미분 오차는 결과에 영향을 안 줌
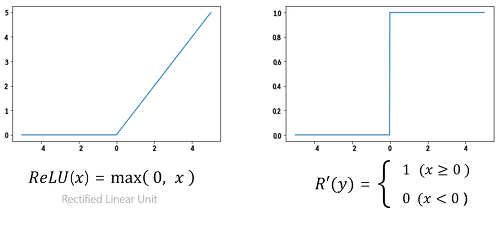
- 결론
i) 미분이 가능하면 구간 내에서 정상적으로 미분하여 학습 (우미분 값 == 좌미분 값)
ii) 미분이 불가능하면 우미분 혹은 좌미분 값 중 하나를 선택하여 학습( 우미분 값 != 좌미분 값)
