데이터셋 구성과 훈련 데이터 단위
데이터셋 구성
관측데이터의 구성
-
표본집단 구성
-
if 범주성 데이터, 클래스별로 비율 맞추기(by 손실함수에 가중치 조절)
-
if 회귀 데이터, 근사하려는 함수 범위 찾기
- 연속 함수 근사, 보간기법
- 영역 밖 , 외삽(근사능력은 떨어짐)
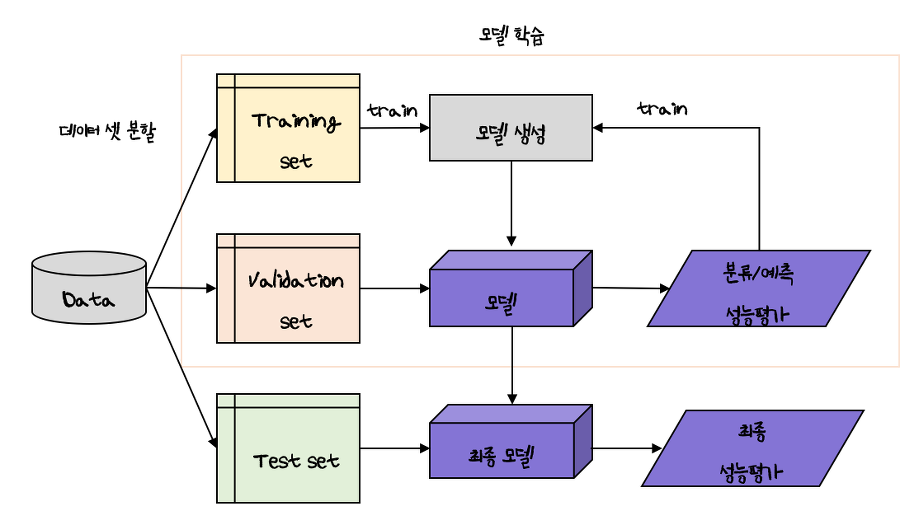
데이터셋의 분리
-
훈련 데이터셋 : 모델을 훈련할 때 사용
-
검증 데이터셋 : 성능 평가를 위해 하이퍼 파라미터 튜닝
-
테스트 데이터 셋 : 최종 성능 평가
-
위의 데이터는 서로 중복되지 않고 배타적 분리
-
훈련에 사용하지 않은 데이터를 평가해야 성능 평가가 이뤄짐
-
7:3 or 8:2 ? 뭐가 더 좋은가요?
-
데이터 셋 분리 원칙
- 분리된 데이터셋의 분포가 원래 데이터 분포 따르기
- 검증 데이터셋과 테스트 데이터셋의 분포는 훈련데이터 셋의 분포와 같다
- 성능 평가를 위한 최소의 데이터셋 구성 후 나머지 데이터는 훈련 데이터 할당
- 훈련 데이터 셋 : 테스트 데이터 셋 = 8: 2 , 7 : 3
- 검증 데이터 셋은 훈련데이터 셋에서 10~20% 분할
훈련 데이터 단위
-
배치 방식; 훈련 데이터셋을 한꺼번에 입력하는 방식(거의 불가능한 방식, 미니배치크기= 훈련데이터 셋)
-
미니배치 방식: 데이터를 작은 단위로 묶어서 훈련 방식, 가장 융통성이 있다
-
확률적 방식: 데이터 샘플단위로 훈련(미니배치의 크기 =1)
훈련 데이터 단위에 따른 경사 하강법의 분류
-
배치 경사 하강법 : 그레디언트를 정확히 계산하여 부드러운 선
-
미니배치 경사 하강법 : 작은 묶음의 샘플로 그레디언트 근사하므로, 중간 위치
-
확률적 경사 하강법 : 하나의 샘플로 그레이디언트 근사하므로 상당히 많이 진동
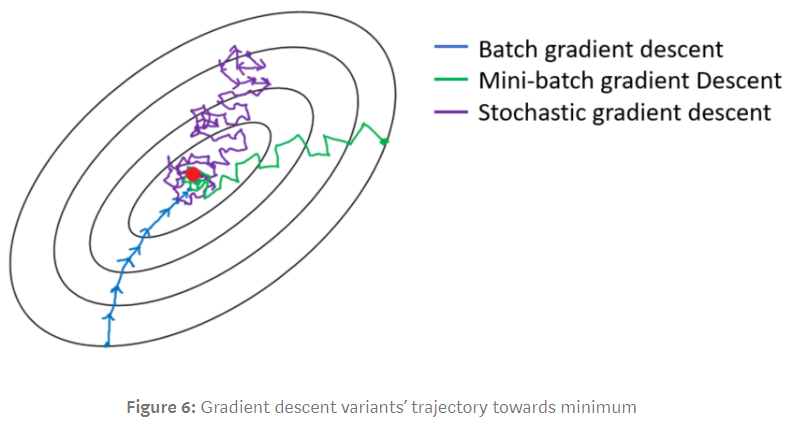
- if 손실함수가 립시츠 연속 성질, 확률적 경사 하강법도 최적해 수렴
*립시츠 연속: 두 점사이의 거리를 일정비 이상으로 증가시키지 않는다.
- 정해진 미분계수를 넘지 못한다
- gradient exploding 문제 해결https://hwiyong.tistory.com/395
미니배치 훈련 방식
- 고해상도 이미지처럼 샘플 용량이크면, 미니배치 크기 =1 로 훈련(SGD)
미니배치 훈련 방식의 성능이 우수
-
학습이 더 빠르고 모델의 성능이 좋다
-
작은 단위로 묶어서 훈련하기 때문에 미니 매치 생성할 때마다 매번 다른 데이터로 묶임
-
매번 확률의 차이가 생겨서, 조금씩 다른 통계량을 갖는 확률적 성질이 생김
-
확률적 성질, 일반화 오류 줄고 과적합 방지하여 정규화 효과 생김 ( WHY?)
-> 다양한 데이터를 학습할 수 있기 때문이다.
-
그레디언트 근삿값을 가져, 학습 속도가 빨라짐
-
정규화 효과로 인해 최적해 찾음

미니배치의 크기 정하기
- 미니배치 큰 경우, 통계적 이득이 크지 않다.
손실 함수의 정의(* )
손실함수를 정의하는 기준
-
모델이 표현하는 함수의 형태 결정
-
손실함수의 최적해 BY 파라미터화
-
최적해가 관측 데이터를 잘 설명하는 함수의 파라미터값 조정
- 모델의 오차 최소화 정의
- 관측 데이터 확률의 최대화( 최대우도추정방식)
오차 최소화 관점
-
모델의 예측과 관측 데이터의 타깃 차이
-
모델 오차 최소화하는 것이 손실함수의 목표
최대 우도추정 관점
-
우도(likelihood): 모델이 추정하는 관측 데이터의 확률
-
관측데이터의 확률이 최대화되는 확률분포 함수 만드는 것이 목표
-
확률모델인 경우에서만 사용
오차 최소화 관점에서 손실 함수의 정의
- 모델의 예측과 타깃과의 오차 최소화
모델의 오차와 손실 함수
-
신경망 모델은 파라미터 와 학습데이터가 있다
-
오차 최소화 관점, 손실 함수는 오차의 크기 나타내는 함수로 정의
-
오차의 크기를 나타내는 대표적인 함수는 벡터의 크기를 나타내는 노름이다.
-
L2(MSE) 와 L1(MAE) 노름을 사용한다.
평균제곱오차(MSE)
- 정의: N개의 데이터에 대해 오차의 L2 노름의 제곱의 평균으로 정의된다
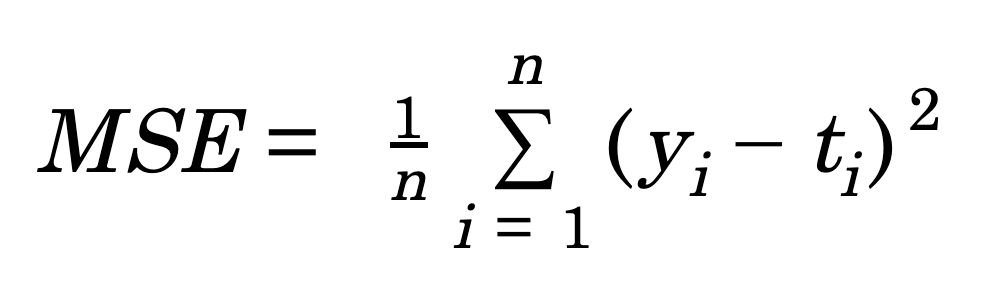
-
목표: 모델이 타깃의 평균 예측
-
단점: 오차가 커질수록 손실이 너무 크게 증가하여 이상치 생길 수 있다.
평균절대오차(MAE)
- 정의: N개의데이터에 대해 오차의 L1노름의 평균정의

-
목표: 모델이 타깃의 중앙값 예측
-
장점: 오차가 커질수록 손실이 선형적으로 증가하여 이상치에 덜 민감
-
단점: 미분이 불가능한 함수이기에 구간별로 미분처리해야함
오차 최소화 관점에서 최적화 문제 정의

최대우도추정 관점에서 손실함수 정의
-
모델이 예측하는 우도가 최대화하는 손실함수 정의
-
오차를 최소화하면 된다
관측 데이터의 우도와 손실 함수
-
신경망 모델은 파라미터로 이뤄진 확률 모델
-
학습 데이터의 각 샘플로는 독립적으로 샘플링하여 i.i.d 성질 만족
-
관측 데이터의 확률이 우도
-
샘플이 서로 독립이므로 관측데이터의 우도는 N개의 샘플의 우도 곱으로 표현 가능

최대우도추정 관점에서 최적화 문제 정의
- 목적함수인우도를 최대화하는 확률 모델의 파라미터 찾기
최대우도추정 관점의 최적화 문제 개선
-
수치적 변화 및 안정적으로 최적화가 가능하다
-
표준 형태의 최소화 문제 통일 가능
-
변환 과정
- 로그 우도를 사용한다
- 최대화문제를 최소화로 하기 위해서 음의 로그 우도로 사용한다.
목적 함수를 로그 우도로 변환
-
지수족 확률분포(가우시안, 베르누이)를 로그로 취하면 함수 형태가 다루기 쉬워진다
-
언더플로를 방지한다(곱-> 합산)
-
최적해는 달라지지 않는다

최대화를 최소화 문제로 변환
회귀문제에서 최대우도측정을 위한 손실 함수 정의
-
회귀모델: 가우시안 분포
-
신경망 모델 출력: 평균과 정밀도의 역수를 분산으로 분포정의
-
오차제곱합(SSE)가된다.
이진 분류 문제에서 최대우도추정을 위한 손실함수 정의
-
이진 분류 모델: 베르누이 분포
-
신경망 모델 출력: 첫 번째 클래스의 발생 확률이 정의
-
손실함수: 베르누이 분포의 음의 로그 우도
-
평균 사용 시, 최적화 과정에서 손실이 작아진다.
다중 분류 문제에서 최대우도추정을 위한 손실 함수 정의
-
다중 분류 모델: 카테고리 분표
-
신경망 모델 출력: 각 클래스가 발생할 확률
-
손실함수: 카테고리 분포의 음의 로그 우도
-
크로스 엔트로피 사용
신경망 학습을 위한 손실함수
-
신경망 학습: 오차 최소화 , 우도 최대화 -> 손실함수 유도
-
지도 학습, 기본 회귀 문제와 분류 문제 확장하여 변형 또는 혼합 형태
-
손실 함수: 평균제곱 오차, 크로스 엔트로피
-
회귀 문제 : 평균제곱오차 사용
-
분류 문제: 이진 크로스엔트로피, 크로피 엔트로피
정보량, 엔트로피, 크로스 엔트로피
정보량
-
정의: 확률을 표현하는데 필요한 비트수 (사건이 얼마나 자주 발생)
-
놀라움의 정도에 비례
-
확률이 낮은 사건이 발생하면 놀라움의 정도가 커져 정보가 많다
-
정보량은 확률의 반비례이다
-
독립 사건들의 정보량은 더해져야, 확률의 역수에 로그값 취하기
-
확률이 0 이면 정보량은 무한대, 확률이 1이면 정보량은 0
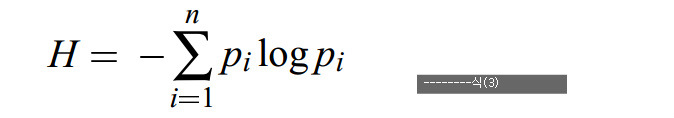
엔트로피
-
정의: 확률 변수 또는 확률분포가 얼마나 불확실한지 혹은 무작위한지 나타냄.
-
특징: 분산이 크면 엔트로피가 높다(정비례)
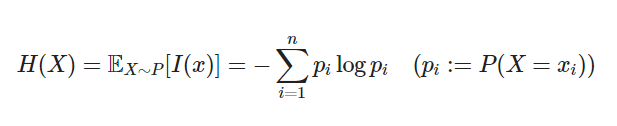
크로스 엔트로피
-
정의: 두 확률분포의 차이 또는 유사하지 않은 정도
-
특징: q의 정보량을 p에 대한 기댓값 취하기
- q가 p를 정확히 추정하여 두 분포가 같으면 크로스 엔트로피 최소화
- q가 p를 잘 추정 못하면 크로스 엔트로피 최대화손실함수로서 이진 크로스 엔트로피의 동작
-
신경망의 예측 분포와 타깃 분포가 같을 때와 다를 때 크로스 엔트로피가 달라지는지 확인
-
예측값이 1이면 크로스 엔트로피 0 (타깃분포 = 예측 분포)
-
예측값이 0이면 크로스 엔트로피 무한대이다.
