생산자-소비자 큐로 deque를 사용하라
선입선출(FIFO)
-
처음 들어온 데이터를 더 먼저 사용하는 구조
-
First-In First-Out
-
함수가 처리할 값을 수집하고, 이렇게 수집된 값들을 다른 함수로 처리해야 할 때 도착 순서대로 사용
-
파이썬 내장 리스트 타입을 FIFO로 사용하곤 한다.
class Email:
def __init__(self, sender, receiver, message):
self.sender = sender
self.receiver = receiver
self.message = message
#구성보단 함수의 Email인스턴스를 반환하거나 NoEmailError 예외를 발생시킨다는 인터페이스만 중요하다.
class NoEmailError(Exception):
pass
def try_receive_email():
#Email 인스턴스를 하나 반환하거나, NoEmailError를 발생시킨다.
...생산자 함수는 전자우편을 받아서 나중에 소비될 수 있게 큐에 넣는다.
리스트의 append 메서드를 사용하여 새 메시지를 큐 맨 뒤에 추가함으로써 이전에 받은 메시지들이 모두 처리된 다음에 처리
def produce_emails(queue):
while True:
try:
email = try_receive_email()
except NoEmailError:
return
else:
queue.append(email) #생산자소비자 함수는 전자우편을 가지고 유용한 일을 수행한다. 큐에 대해 pop(0) 호출한다.
pop(0)은 리스트의 첫 번째 원소를 제거하고, 제거한 첫 번째 값을 호출자에게 돌려준다.
소비자는 항상 큐의 맨 앞에 있는 원소를 처리함으로써 원소가 도착한 순서대로 큐의 원소를 처리하도록 보장한다.
def consume_one_email(queue):
if not queue:
return
email = queue.pop(0) #소비자
#장기 보관을 위해 메시지 인덱싱
...생산자와 소비자 함수를 만든 후에 하나로 엮어줄 루프 함수가 필요하다.
keep_running 함수가 False를 반환할 때까지 생산과 소비를 번갈아 반복하는 과정을 동시 처리
def loop(queue, keep_running):
while keep_running():
produce_emails(queue)
consume_one_email(queue)
def my_end_func():
...
loop([], my_end_func)지연시간과 단위 시간당 스루풋사이의 상충 관계를 해결
import timeit
def print_results(count, tests):
avg_iteration = sum(tests) / len(tests)
print(f'\n원소 수: {count:>5,} 걸린 시간: {avg_iteration:.6f}초')
return count, avg_iteration
def list_append_benchmark(count):
def run(queue):
for i in range(count):
queue.append(i)
tests = timeit.repeat(
setup ='queue = []',
stmt = 'run(queue)',
globals=locals(),
repeat= 1000,
number=1)
return print_results(count, tests)여러 크기의 리스트를 사용하여 이 벤치마크 함수를 실행하면 데이터 크기와 성능의 관계 비교
def print_delta(before, after):
before_count, before_time = before
after_count, after_time = after
growth = 1 + (after_count - before_count) / before_count
slowdown = 1 + (after_time - before_time) / before_time
print(f'데이터 크기 {growth:>4.1f}배, 걸린 시간 {slowdown:>4.1f}배')
baseline = list_append_benchmark(500)
for count in (1_000, 2_000, 3_000, 4_000, 5_000):
comparison = list_append_benchmark(count)
print_delta(baseline, comparison)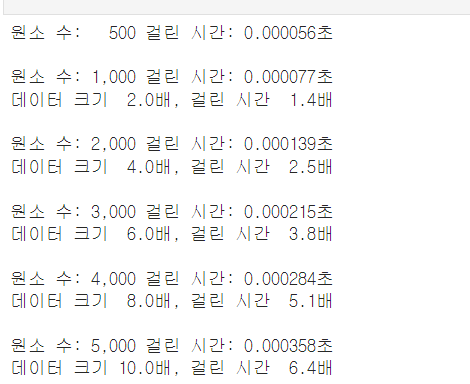
데이터 늘어날 수록 전체 시간이 선형적으로 커지고 내부적으로 원소가 추가됨에 따라서 리스트 타입이 원소 저장을 위해 가용량을 늘리는 북 비용이 발생하지만 비용이 적다.
그리고, append를 반복 호출하므로 여러 append 호출이 이 비용을 분할상황을 해준다.
#큐의 맨 앞에서 원소를 제거하는 pop(0) 호출을 벤치마크한다.
#벤처마크를 실행하면, 큐 길이가 성능에 어떤 영향을 미치는 지 알 수 있다.
def list_pop_benchmark(count):
def prepare():
return list(range(count))
def run(queue):
while queue:
queue.pop(0)
tests = timeit.repeat(
setup = 'queue = prepare()',
stmt ='run(queue)',
globals = locals(),
repeat = 1000,
number =1)
return print_results(count, tests)
baseline = list_pop_benchmark(500)
for count in (1_000,2_000,3_000,4_000,5_000):
comparison = list_pop_benchmark(count)
print_delta(baseline, comparison)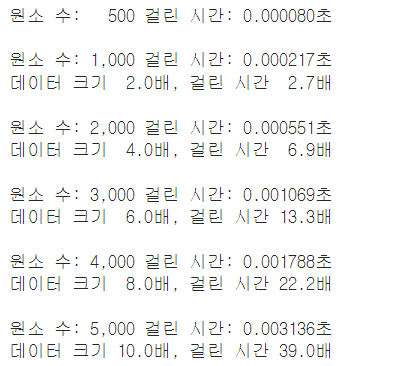
위의 결과를 보면 값이 지수적으로 늘어납니다.
왜냐하면, pop(0)를 하면 리스트의 모든 남은 원소를 제 위치로 옮겨야 하고, 결과적으로 전체 리스트 내용을 다시 재대입해야하기 때문입니다.
리스트의 모든 원소에 대해 pop(0)을 호출하므로 대략 len(queue) * len(queue)연산을 수행해야 모든 대기열 소비가 가능하게 되어서 데이터가 크게 되면 이런 코드는 작동하기 어렵다.
파이썬 collections 내장 모듈 deque 클래스
-
produce_emails 함수에 있는 append는 그대로
-
consume_one_email에 있는 list.pop메서드와 deque.popleft 메서드를 아무 인자도 없이 호출하게 바꾼다.
-
나머지 코드 그대로 두기
import collections
def consume_one_email(queue):
if not queue:
return
email = queue.pop(0) #소비자
#전자우편 메시지 처리
...
def my_end_func():
...
loop(collections.deque(), my_end_func)
#append의 성능이 리스트를 사용하는 성능과 거의 비슷
def deque_append_benchmark(count):
def prepare():
return collections.deque()
def run(queue):
while queue:
queue.pop(0)
tests = timeit.repeat(
setup = 'queue = prepare()',
stmt ='run(queue)',
globals = locals(),
repeat = 1000,
number =1)
return print_results(count, tests)
import collections
baseline = deque_append_benchmark(500)
for count in (1_000,2_000,3_000,4_000,5_000):
comparison = deque_append_benchmark(count)
print_delta(baseline, comparison)
def deque_popleft_benchmark(count):
def prepare():
return collections.deque(range(count))
def run(queue):
while queue:
queue.popleft()
tests = timeit.repeat(
setup = 'queue = prepare()',
stmt ='run(queue)',
globals = locals(),
repeat = 1000,
number =1)
return print_results(count, tests)
baseline = deque_popleft_benchmark(500)
for count in (1_000,2_000,3_000,4_000,5_000):
comparison = deque_popleft_benchmark(count)
print_delta(baseline, comparison)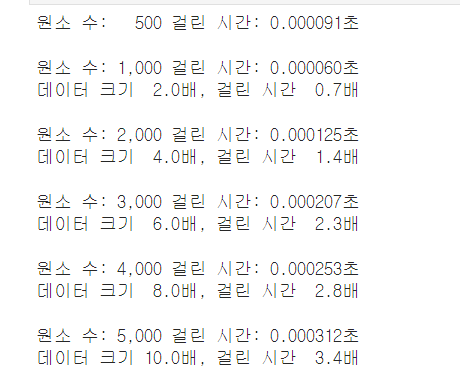
Summary
-
생산자는 append를 호출해서 원소를 추가하고 소비자는 pop(0)를 사용해서 원소를 받게 만든다면 리스트 타입을 FIFO 큐로 사용할 수 있다. 그러나, 리스트를 FIFO 큐로 사용하면, 큐 길이가 늘어남이 따라서 pop(0)의 성능이 선형보다 더 크게 나빠지기 때문에 문제가 될 수 있다.
-
collections 내장 모듈에 있는 deque 클래스는 큐 길이와 관계없이 상수 시간 만에 append와 popleft를 수행하기 때문에 FIFO큐 구현에 이상적이다,
