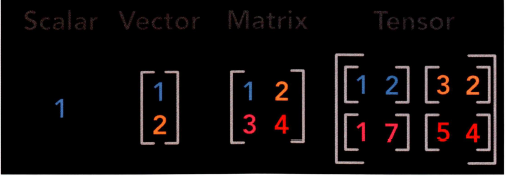
텐서(Tensor)
데이터를 표현하는 단위입니다.
- Scalar
상수값으로 하나의 값을 표현할 때 1개의 수치로 표현하는 것입니다.(float)
*이용법
import torch
scalar1 = torch.tensor([1.])
print(scalar1) # tensor([1.])
scalar2 = torch.tensor([3.])
print(scalar2) # tensor([3.])
*사칙연산
add_scalar = scalar1 + scalar2
print(add_scalar) # tensor([4.])
sub_scalar = scalar1 - scalar2
print(sub_scalar) # tensor([-2.])
mul_scalar = scalar1 * scalar2
print(mul_scalar) # tensor([3.])
div_scalar = scalar1 / scalar2
print(div_scalar) # tensor([0.3333])
- Vector
하나의 값을 표현할 때 2개 이상의 수치로 이용한 것이고 스칼라의 형태와 동일 속성을 갖지만 여러 수치 값을 이용해 표현합니다.(float)
*이용법
vector1 = torch.tensor([1.,2.,3.])
print(vector1) # tensor([1.,2.,3.])
vector2 = torch.tensor([4.,5.,6.])
print(vector2) # tensor([4.,5.,6.])
*사칙연산
add_vector = vector1 + vector2
print( add_vector )# tensor ( [ 5 . , 7 . , 9 . ] )
sub_vector = vector1 - vector2
print(sub_vector )# tensor( [-3. , -3. , -3. J )
mul_vector = vector1 • vector2
print(mul_vector)# tensor( [ 4. , 10. , 18. ] )
div_vector = vector1 / vector2
print( div_vector )# tensor( [0.2500, 0.4000, 0.5000] )*torch 내장 메서드로 계산 가능
torch.add(vector1, vector2) # tensor ( [ 5 . , 7 . , 9 . ] )
torch.sub(vector1, vector2) # tensor([-3., -3., -3.])
torch.mul(vector1, vector2) # tensor( [ 4. , 10. , 18. ] )
torch.div(vector1, vector2) # tensor( [0.2500, 0.4000, 0.5000] )
torch.dot(vector1, vector2) # tensor(32.)
- 행렬
2개 이상의 벡터 값을 통합해서 구성된 값으로, 벡터간 연산 속도를 빠르게 해주는 선형 대수의 기본 단위입니다.
*이용법
matrix1 = torch.tensor ( [ [ l. , 2 . J , [ 3 . , 4 . J J )
print(matrix1 )
#tensor ( [ [ 1 . , 2 . ] ,
# [ 3 . , 4 . ] ] )
matrix2 = torch.tensor( [ [ S . , 6 . J , [7 . , 8 . ] ] )
print(matrix2)
# tensor ( [ [ 5 . , 6 . ] ,
# [ 7 . , 8 . ll )
*사칙연산
sum_matrix = matrix1 + matrix2
print(sum_matrix)
# tensor( [ [ 6 . , 8 . ] ,
# [10., 12.]])
sub_matrix = matrix1 - matrix2
print(sub_matrix)
# tensor ( [ [ -4 . , -4 . ) ,
# (-4., -4.]))
mul_matrix = matrix1 * matrix2
print(mul_matrix)
# tensor ( [ [ 5 . , 12 . ] ,
# [2 1., 32.]])
div_matrix = matrix1 / matrix2
print(div_matrix)
# tensor([[0.2000, 0.3333],
# [0.4286, 0.5000] J )*torch모듈로 사칙연산
torch.add(matrix1, matrix2)
# tensor ( [ [ 6 . , 8 . ] ,
# [1 0., 12.ll)
torch.sub(matrix1, matrix2)
# tensor ( [ [-4 . , -4 . ] ,
# [-4., -4.]])
torch.mul(matrix1, matrix2)
# tensor([[ 5., 12. J,
# [ 2 1. , 32 . ll )
torch.div(matrix1, matrix2)
# tensor( [ [0.2000, 0.3333] ,
# [0.4286, o.sOOO J l )
torch.matmul(matrix1, matrix2)
# tensor([[19., 22.],
# [43., 50.]])
- 텐서
tensor1 = torch.tensor ( [ [ [ 1. , 2 . ] , [ 3 . , 4 . ] l , [ [ 5 . , 6 . ] , [ 7 . , 8 . ] ] ] )
print(tensor1)
# tensor ( [ [ [ 1. , 2 . ] ,
# [ 3. , 4 . ll,
# [ [ 5. , 6 . l,
# [ 7 . , 8 . ]]])
tensor2 = torch.tensor([[[9., 10. l, [1 1., 12.]], [[13., 14.], [15., 16.]]])
print(tensor2)
# tensor([[[ 9., 10. ],
# [11., 12.]],
# [[13., 14. ],
# [15., 16. ]]])
*사칙연산
sum_tensor = tensor1 + tensor2
print(sum_tensor)
# tensor ( [ [ [ 10 . , 12 . ] ,
# [14., 16.]],
# [[18., 20. ],
# [22., 24. ]]])
sub_tensor = tensor1 - tensor2
print(sub_ tensor)
# tensor([[[-8., -8. ],
# [-8., -8.]],
# [[-8., -8. ],
# [-8., -8. ]]])
mul_tensor = tensor1 * tensor2
print(mul_tensor)
# tensor(([[ 9., 20. ],
# [ 33., 48. ]],
# [[ 65., 84.],
# [105., 128.]]])
div_tensor = tensor1 / tensor2
print(div_tensor)
# tensor([[[0.1111, 0.2000],
# [0.2727, 0.3333]],
# [[0.3846, 0.4286],
# [0.4667, 0.5000] ] ] )*torch메서드 이용
torch.add(tensor1, tensor2)
# tensor ( [ [ [ 10 . , 12 . ] ,
# [14., 16. ]],
# [[18., 20.],
# [22., 24.]]])
torch.sub(tensor1, tensor2)
# tensor ( [ [ [ -8 . , -8 . ],
# [-8., -8. ]],
# [ [-8 . , -8 . ] ,
# [-8., -8.]]])
torch.mul( tensorq, tensor2)
# t ensor([[ [ 9., 20.],
# [ 33., 48.]],
# [[ 65., 84. ],
# [ 105 . , 128 . ] ] ] )
torch.div( tensor1, tensor2)
# tensor ( [ [ [ 0 . 1111, 0 . 2000 ] ,
# [0.2727, 0.3333] ],
# [[0.3846, 0.4286],
# [0.4667, 0.5000] ]] )
torch.matmul(tensor1, tensor2)
# tensor ( [ [ [ 3 1. , 34 . ] ,
# [ 7 1., 78. JJ,
# [[155., 166.],
# [211., 226.] ]])- 그림으로 보는 정리
Autograd
Back propagation을 이용하여 파라미터 업데이트를 쉽게 해줍니다.
원리
- Step1
import torch # 파이토치 사용하기 위해 불러오기
if torch.cuda.is_available( ): #GPU이용하여 계산 가능한지 파악하는 메서드
DEVICE = torch.device('cuda')
else:
DEVICE = torch.device('cpu')- Step2
BATCH_SIZE = 64 # 딥러닝 모델에서 파라미터 업데이트할 때 게산되는 데이터의 개수
INPUT_SIZE = 1000 # 딥러닝 모델에서 Input의 크기이자 입쳑층의 노드 수를 의미
HIDDEN_SIZE = 100 # 딥러닝 모델에서 Input을 다수의 파라미터를 이용해서 계산한 결과를 한 번 더 계산되는 파라미터 수로 은닉층의 노드 수를 의미
OUTPUT_SIZE = 10 # 딥러닝 모델에서 최종으로 출력되는 값의 벡터의 크기를 의미
- Step3(작동방식)
x = torch.randn(BATCH_SIZE ,
INPUT_SIZE ,
device = DEVICE ,
dtype = torch.float ,
requires _grad = False )
y = torch.randn(BATCH_SIZE,
OUTPUT_SIZE ,
device = DEVICE ,
dtype = torch.float ,
requires_grad = False )
w1 = torch.randn(INPUT_SIZE,
HIDDEN_SIZE ,
device = DEVICE ,
dtype = torch.float ,
requires _grad = True )
w2 = torch.randn(HIDDEN_SIZE,
OUTPUT_SIZE,
device = DEVICE ,
dtype = torch.float ,
requires _grad = True )
*파라미터 업데이트
learning_rate = le-6
for t in range(1, 501):
y_pred = x.rnm(wl).clamp(min = O).rnm(w2)
loss =(y_pred - y).pow(2).sum( )
if t % 100 == 0:
print("Iteration: ", t, "\t", "Loss: ", loss. it em( ) )
loss.backward( ) #(6)
with torch.no_ grad ( )
w1 -= learn i ng_ra t e * wl . grad
w2 -= learn i ng_ra t e * w2 . grad
w1. grad . zero_ ( )
w2. grad . zero_ ( )*결과
# Iteration : 100 Loss: 584.4674072265625
# Iteration : 200 Loss: l.8814672231674194
# Iteration : 300 Loss: 0.015688762068748474
# Iteration : 400 Loss: 0.0004902312648482621

성장을 도울 아카이빙 블로그