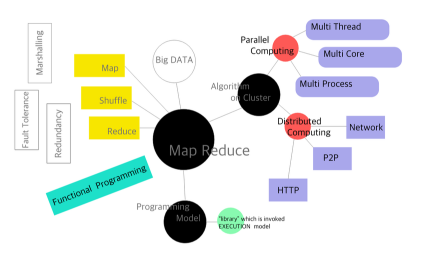
맵리듀스
-
정의: 클러스터에 동작하는 알고리즘으로 프로그래밍 모델이다.
-
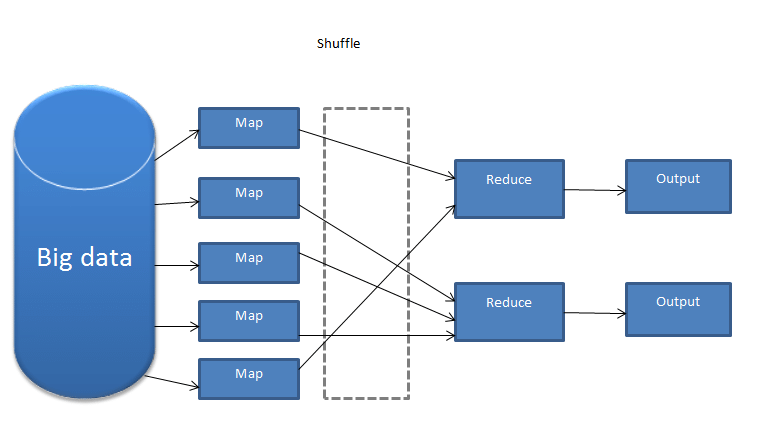
로직: Map, Shuffle, Reduce
-
특징: 빅데이터 솔루션(하둡, 스파크) 을 다루는 프로그래밍모델로 병렬처리 기반이다.
-
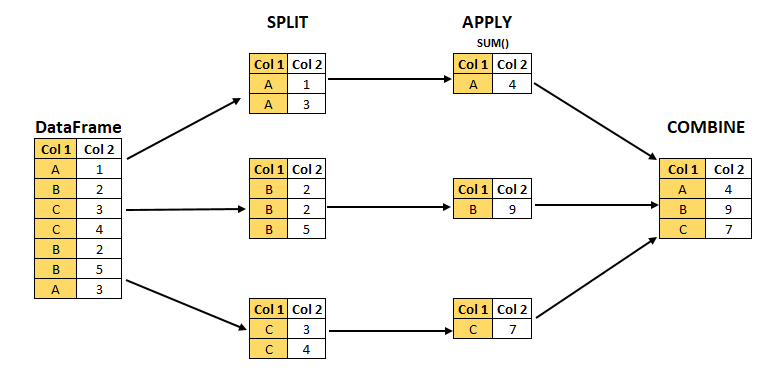
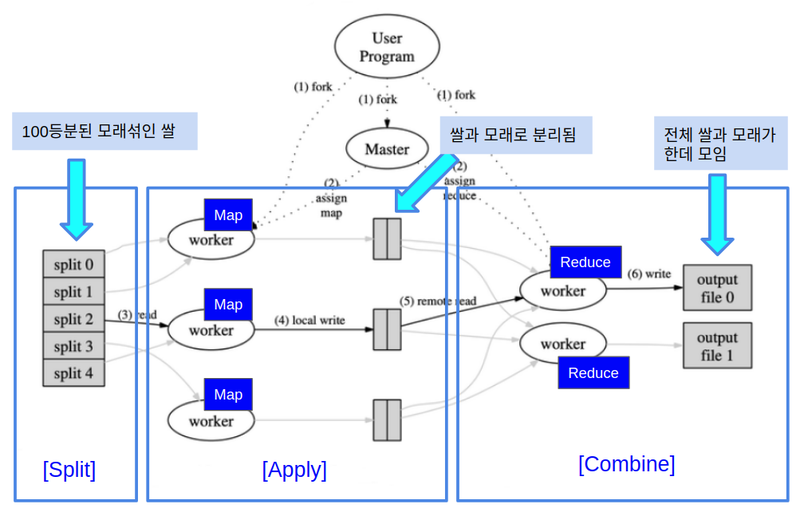
방식: Split-Apply-Combine Strategy
-
I) Split: 특별한 기준으로 나누는 것이 아닌 동일 크기로 나누는 것
-
II) Apply: Split된 object를 카테고리로 분리 후 함수화
-
III) Combine: 처리된 것을 모은다.
-
-
함수
-
map()함수

-
수식:

-
여러 개의 컴퓨터에 연산 나누기
-
Split부분 데이터를 가져가서 조작을 하는 Apply역할 함수
-
in_key인자: Split의 결과로 생긴 partitioning키 값으로 최종 Output반영 X
-
in_value인자
-
split된 데이터 가져다가 아래 인자 갖기
-
out_key: map함수가 결과물을 구분하는 기준 값
-
intermediate_value
-
Code
-
-
mynum = ['1','2','3','4']
mynum_int = list(map(int, mynum)) # mynum의 각 원소에 int 함수를 적용
print(mynum_int)
mynum_square = list(map(lambda x : x*x, mynum_int)) # mynum_int의 각 원소 x에 lambda x : x*x 함수를 적용
print(mynum_square)-
filter

-
수식:
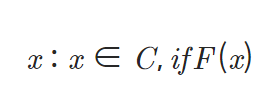
-
Code:
mynum = range(-5, 5) # -5부터 4까지의 정수
mynum_plus = list(filter(lambda x: x > 0, mynum)) # mynum의 각 원소 x에 대해 lambda x: x > 0 인지 체크하는 필터를 적용
print(mynum_plus)- reduce

-
수식:
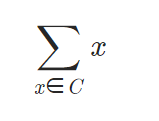
-
컬렉션 축약
-
여러 개 컴퓨터에 분산하여 연산 결과 합치기
-
map()함수로 인해 만들어진 결과물을 Combine하는 역할
-
intermeditae_value를 out_key별로 구분하여 리스트 형태로 입력 후 grouping(by R) 그리고 Output출력
-
Code:
-
mynum = ['1','2','3','4']
mynum_int = list(map(int, mynum)) # mynum의 각 원소에 int 함수를 적용
print(mynum_int)
mynum_square = list(map(lambda x : x*x, mynum_int)) # mynum_int의 각 원소 x에 lambda x : x*x 함수를 적용
print(mynum_square)`
이미지로 보는 맵리듀스
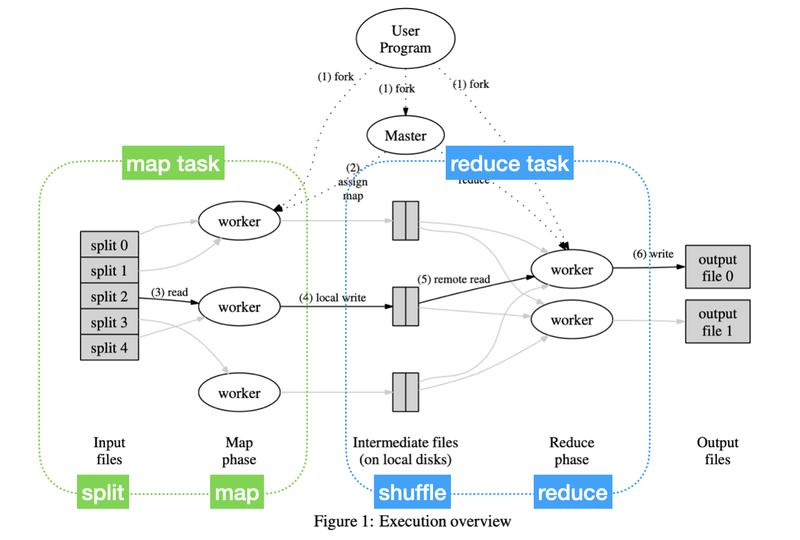
병렬 컴퓨팅(Parallel Computing)
-
정의: 한 대의 컴퓨터, 여러 개의 CPU코어 사용
-
멀티프로세스(Multiprocessing) : 연속적으로 실행되는 컴퓨터 프로그램으로 스케줄링의 대상이 되는 task로 이를 프로세스라고 한다. 이 프로세스가 2개 이상 있는 경우를 의미한다.
-
멀티스레드(Multithreading) : 프로세스 내에서 실행되는 흐름의 단위를 스레드라고 하는데 이것이 2개 이상 사용이 되는 것이다.
분산 컴퓨팅(Distributed Computing)
-
정의: 여러 대의 컴퓨터가 네트워크로 연결된 상황
-
용어: P2P , HTTP, Network
클러스터 컴퓨팅
-
개념: 병렬 컴퓨팅과 분산 컴퓨팅을 통합하는 것으로 여러 대의 컴퓨터들이 연결되어 하나의 시스템처럼 동작하는 집합으로 노드와 관리자로 구성이 됨
-
노드: 프로세싱 자원 제공 시스템
-
관리자: 노드를 서로 연결하여 단일 시스템처럼 만드는 로직 제공
하둡과 스파크
하둡
-
정의: 대용량 데이터 분산처리하는 자바 기반 프레임워크.
-
단점: map함수가 모두 종료 되어야 reduce함수가 실행이 되는 성능 손실이 크므로 빅데이터 기반의 배치성 통계 작업에 주로 투입
*배치성 통계 작업
- 정의: 데이터를 일괄적으로 모아 처리하는 법
스파크
- 정의: map 함수가 전부 종료되지 않아도 결과 스트리밍한다

콜백함수
-
정의: 호출될 함수를 다른 함수의 매개변수가 되고, 매개변수로 전달된 함수가 호출됨
-
CODE
def france():
print('bonjour')
print("슝=3")
hello = france
print(hello)
hello() # bonjour
print(type(hello)) # function데이터 컬렉션
-
정의: List,Set와 같은 형태의 자료형이다.
-
예시:

-
주로 deque, defaultdict, namedtuple()가 사용된다.
-
defaultdict 자료구조(문장에 쓰인 단어의 개수 세는 코드)
from collections import defaultdict
text = """I have a depression, and then there was a girl who came into
my life. One day, my life was changed because that girl just changed my
life. She taught me how to love and how to be an active person.
And then, I feel so happy when I am always with her.
I love her so much. I don't want let her go. I am sad because she
is with her favorite friends. I will do anything to make her proud"""
result = defaultdict(int)
word = text.split()
for i in word:
result[i] += 1
print(result)
result['girl']