데이터 확인
-
Dataset: train, test, val
-
df: read_csv
-
parameters: delimiter, names
-
cross-validation: test dataset분리
df_train = pd.read_csv("train.txt",delimiter=';',names=['text','label'])
df_val = pd.read_csv("val.txt",delimiter=';',names=['text','label'])
df = pd.concat([df_train,df_val])
print("Shape of the DataFrame:",df.shape)
df.reset_index(inplace=True,drop=True)
df.head()
sns.countplot(df.label)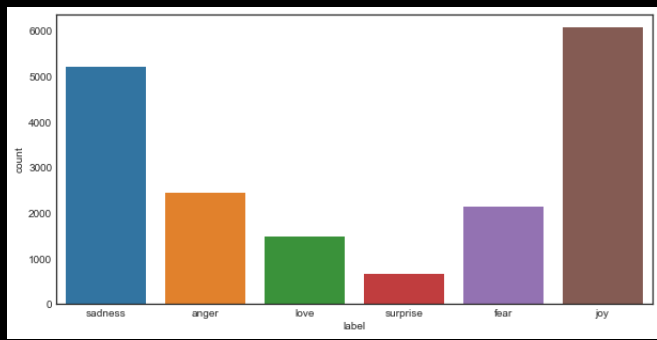
def custom_encoder(df):
df.replace(to_replace ="surprise", value =1, inplace=True)
df.replace(to_replace ="love", value =1, inplace=True)
df.replace(to_replace ="joy", value =1, inplace=True)
df.replace(to_replace ="fear", value =0, inplace=True)
df.replace(to_replace ="anger", value =0, inplace=True)
df.replace(to_replace ="sadness", value =0, inplace=True)
custom_encoder(df['label'])
sns.countplot(df.label)
#이분법적으로 나눠보니 비슷하게 분포가 되어있다.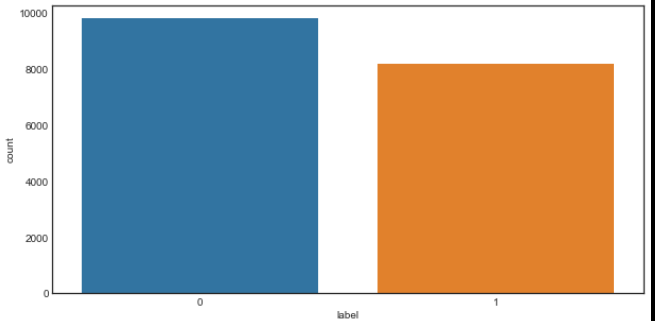
df.head()
Data Pre-processing
#object of WordNetLemmatizer: Transformation수행
lm = WordNetLemmatizer()
def text_transformation(df_col):
corpus = []
for item in df_col:
new_item = re.sub('[^a-zA-Z]',' ',str(item))
new_item = new_item.lower()
new_item = new_item.split()
new_item = [lm.lemmatize(word) for word in new_item if word not in set(stopwords.words('english'))]
corpus.append(' '.join(str(x) for x in new_item))
return corpus
corpus = text_transformation(df['text'])
#Word Cloud: 데이터 시각화 기술로 내포된 text 보여줌
#
rcParams['figure.figsize'] = 20,8
word_cloud = ""
for row in corpus:
for word in row:
word_cloud+=" ".join(word)
wordcloud = WordCloud(width = 1000, height = 500,background_color ='white',min_font_size = 10).generate(word_cloud)
plt.imshow(wordcloud)
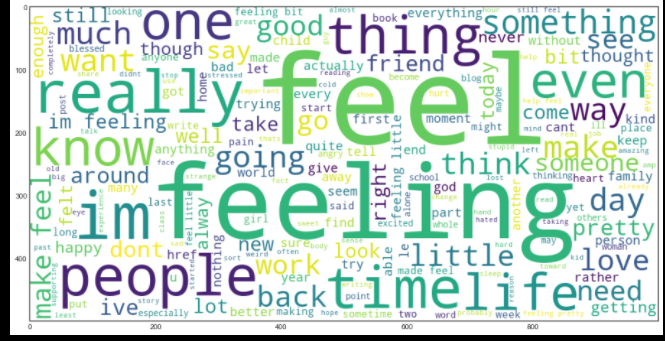
Bag of Words
from sklearn.feature_extraction.text import CountVectorizer
cv = CountVectorizer(ngram_range=(1,2))
traindata = cv.fit_transform(corpus)
X = traindata
y = df.labelGridSearchCV()
parameters = {'max_features': ('auto','sqrt'),
'n_estimators': [500, 1000],
'max_depth': [10, None],
'min_samples_split': [5],
'min_samples_leaf': [1],
'bootstrap': [True]}
grid_search = GridSearchCV(RandomForestClassifier(),parameters,cv=5,return_train_score=True,n_jobs=-1)
grid_search.fit(X,y)
grid_search.best_params_
성장을 도울 아카이빙 블로그